PREVIOUS
Chapter
01
Functional programming is a programming paradigm, where programs are a composition of pure functions. This represents a fundamental difference to object-oriented programming, where programs are sequences of statements, usually operating in a mutable state. These are organized into so-called functions, but they are not functions in the mathematical sense, because they do not meet some fundamental characteristics.
Firstly, a function must be total, this means that for each input that is provided to the function there must be a defined output. For example, the following function dividing two integers is not total:
def divide(a: Int, b: Int): Int = a / b
To answer why this function is not total, consider what will happen if we try to divide by zero:
divide(5, 0)
// java.lang.ArithmeticException: / by zero
The division by zero is undefined and Java handles this by throwing an exception. That means the divide function is not total because it does not return any output in the case where b = 0.
Some important things we can highlight here:
So how can we fix this problem? Let’s look at this alternative definition of the divide function:
def divide(a: Int, b: Int): Option[Int] =
if (b != 0) Some(a / b) else None
In this case, the divide function returns Option[Int] instead of Int, so that when b = 0, the function returns None instead of throwing an exception. This is how we have transformed a partial function into a total function, and thanks to this we have some benefits:
The second characteristic of a function is that it must be deterministic and must depend only on its inputs. This means that for each input that is provided to the function, the same output must be returned, no matter how many times the function is called. For example, the following function for generating random integers is not deterministic:
def generateRandomInt(): Int = (new scala.util.Random).nextIntTo demonstrate why this function is not deterministic, let’s consider what happens the first time we call the function:
generateRandomInt() // Result: -272770531
And then, what happens when we call the function again:
generateRandomInt() // Result: 217937820
We get different results! Clearly this function is not deterministic and its signature is misleading again, because it suggests that it does not depend on any input to produce an output, whereas in truth there is actually a hidden dependency on a scala.util.Random object. This may cause problems, because we can never really be sure how the generateRandomInt function is going to behave, making it difficult to test.
Now, let’s have a look at an alternative definition. For this, we’ll use a custom random number generator, based on an example from the Functional Programming in Scala book:
final case class RNG(seed: Long) {
def nextInt: (Int, RNG) = {
val newSeed = (seed * 0x5DEECE66DL + 0xBL) & 0xFFFFFFFFFFFFL
val nextRNG = RNG(newSeed)
val n = (newSeed >>> 16).toInt
(n, nextRNG)
}
}
def generateRandomInt(random: RNG): (Int, RNG) = random.nextInt
This new version of the generateRandomInt function is deterministic: no matter how many times it is called, we will always get the same output for the same input and the signature now clearly states the dependency on the random variable. For example:
val random = RNG(10)
val (n1, random1) = generateRandomInt(random) // n1 = 3847489, random1 = RNG(252149039181)
val (n2, random2) = generateRandomInt(random) // n2 = 3847489, random2 = RNG(252149039181)If we want to generate a new integer, we must provide a different input:
val (n3, random3) = generateRandomInt(random2) // n3 = 1334288366, random3 = RNG(87443922374356)
Finally, a function must not have any side effects. Some examples of side effects are the following:
This means that a pure function can only work with immutable values and can only return an output for a corresponding input, nothing else.
For example, the following increment function is not pure because it works with a mutable variable a:
var a = 0;
def increment(inc: Int): Int = {
a + = inc
a
}
And the following function is not pure either because it prints a message in the console:
def add(a: Int, b: Int): Int = {
println(s "Adding two integers: $ a and $ b")
a + b
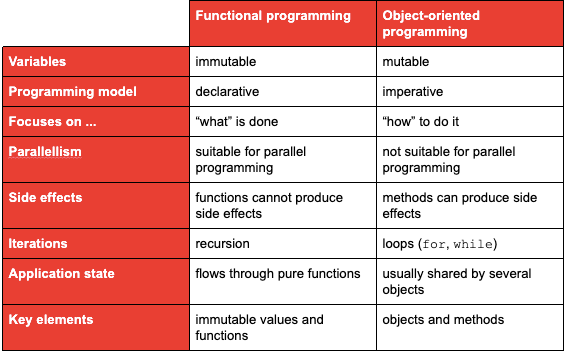
}The following table summarizes the major differences between these two programming paradigms:
For various reasons, functional programming may still seem complex to many. But, if we take a closer look at the benefits, we can change our way of thinking.
For starters, embracing this programming paradigm helps us to break each application down into smaller, simpler pieces that are reliable and easy to understand. This is because a functional source code is often more concise, predictable, and easier to test. But how can we ensure this?
Since Scala supports the functional programming paradigm, these benefits also apply to the language itself. As a result, more and more companies are using Scala, including giants such as LinkedIn, Twitter, and Netflix. In addition, this year Scala is one of the top 10 languages that developers want to learn.