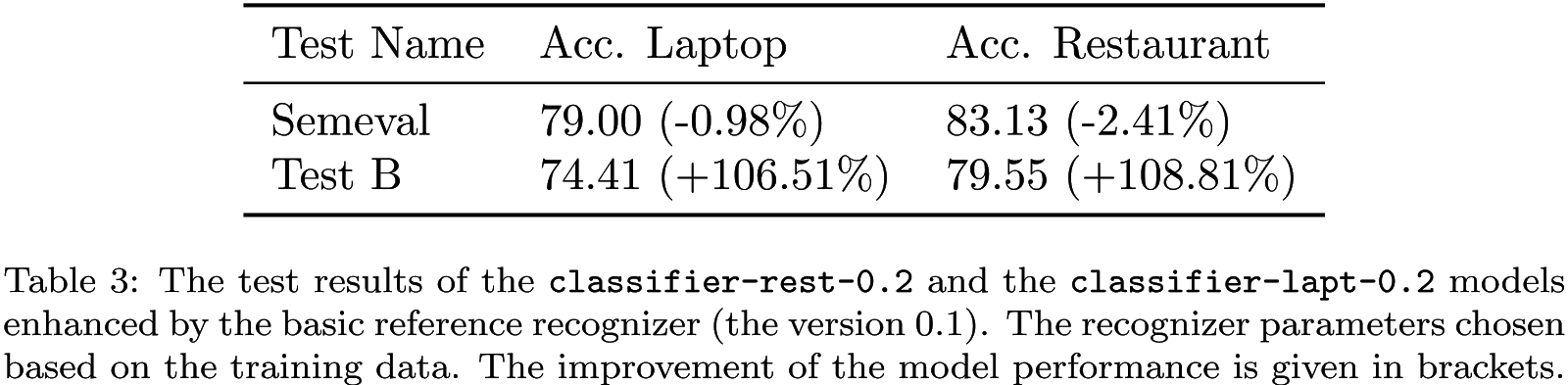PREVIOUS
Chapter
06
Firstly, we will highlight how to start fixing the model limitations more smoothly using the professor. Coming back to the problem stated in test B, avoiding questionable predictions, we want to build an aux. classifier that predicts whether a text relates to an aspect or not. If there is no reference in a text to an aspect, the professor sets a neutral sentiment regardless of the model prediction (details here).
import aspect_based_sentiment_analysis as absa
name = 'absa/basic_reference_recognizer-0.1'
recognizer = absa.aux_models.BasicReferenceRecognizer.from_pretrained(name)
professor = absa.Professor(reference_recognizer=recognizer)
Good practice is to gradually increase the model complexity in response to demands. Because the reference recognition is a side problem, we can simplify the task. We propose a simple aux. model BasicReferenceRecognizer that only checks if an aspect is clearly mentioned in a text (model details are here, the training is here). The table below confirms the significant improvement of Test B performance. Nonetheless, in most cases, there is a trade-off between the performance of different tests as it is here. Note that this is a simple test case. Therefore, we encourage you, especially if it concerns your business, to construct more challenging tests wherein aspect mentions are more implicit.