

Last month in AI – August 2025
AI-driven Newsletter
Welcome to the latest edition of Last month in AI!
August felt like AI’s “summer blockbuster” month: frontier labs shipped tentpoles, open-weights kept pace, and – because this is 2025 – models literally fought each other at chess on a livestream. Also: DIY datacenter rigs got cheaper, and Google’s “nano banana” went fully viral.
Let’s dive into the highlights that defined August.
Models
Qwen3 image edit

Alibaba’s Qwen team dropped Qwen-Image-Edit, built on the 20B Qwen-Image backbone, and it’s unusually good at text edits inside images (Chinese & English).
It routes inputs through Qwen2.5-VL for semantic control and a VAE encoder for appearance control, allowing you to swap objects or restyle scenes while keeping fonts and layout intact. Think “Photoshop with a prompt.” Free weights, Apache-2.0.
gpt-oss

OpenAI finally went truly open-weights again with 20B and 120B models (Apache-2.0). Both ship with 128k context, sparse-MoE (4 experts), and tool-use + reasoning tuning. The 120B reaches near o4-mini performance on a single 80 GB GPU, while the 20B targets edge deployments. They include chain-of-thought and structured output support, and beat similarly sized peers on MMLU, TauBench, and health evals.
Kitten TTS
A super-tiny TTS that actually sounds decent: ~15M params in <25 MB, CPU-only, with eight expressive voices. It’s the kind of model you can run in a browser or Raspberry Pi without drama. Tiny, fast, Apache-2.0, and already spawning plug-and-play servers.
Claude Opus 4.1

Claude Opus 4.1 is Anthropic’s drop-in upgrade to Opus 4, with stronger coding and agentic performance. It’s live across API, Bedrock, Vertex, and Copilot previews. New addition: an “end conversation” safety feature for persistent abuse cases. Same price, sharper brain.
GPT-5
OpenAI’s new flagship went GA on Aug 7 across ChatGPT and the API. GPT-5 leans hard into agentic coding (SWE-bench Verified and Aider polyglot numbers are front-page), better tool calling, and a router that dials up “thinking” only when needed. Team/Enterprise rollouts are underway, plus a “Pro” reasoning tier for longer digs.
DeepSeek 3.1

DeepSeek 3.1 integrates “thinking” and “non-thinking” modes into a single checkpoint, enhancing multi-step reasoning and tool use. Built on its MoE lineage (671B total / ~37B active), it’s already appearing in local stacks and cloud runners.
Google Nano Banana

Google’s Gemini 2.5 Flash Image – a.k.a. nano banana – is now available for developers and in the Gemini app, featuring multi-image fusion, consistent character edits, and SynthID watermarking, all baked in, priced around $0.039/image via the API. The feature’s been confirmed across Google’s developer channels and press.
Hardware
New Nvidia RTX Pro Blackwell cards

NVIDIA quietly expanded its workstation line with RTX PRO 4000 SFF (20 GB GDDR7, 70 W) and RTX PRO 2000 (12 GB GDDR6, 70 W). Compact, power-efficient, and perfect for small-form-factor AI desktops.
Huawei enters the scene
- https://e.huawei.com/cn/products/computing/ascend/atlas-300v-pro.
- https://e.huawei.com/cn/products/computing/ascend/atlas-300i-duo

Huawei added Atlas 300V Pro and Atlas 300i Duo PCIe accelerators to its Ascend lineup, targeting domestic inference/video workloads with multi-codec pipelines and dual-chip options – further evidence China’s AI stack is getting denser at the card level.
Building a training rig with Tenstorrent Blackhole

A great write-up shows a 4× Blackhole (P150a) DIY box for ~$5.6k in cards – 32 GB GDDR6 each, QSFP-DD 800 GbE fabric, and PCIe Gen5 x16, good enough to pretrain mid-size models and fine-tune long-context stacks at home. Tenstorrent’s docs back the 800G networking and PCIe 5.0 specs.
MaxSun Arc Pro B60 Dual (48 GB, ~$1,200)

A very 2009-core move in 2025: two Intel Arc Pro B60s on one board, 48 GB GDDR6 total, and a ~$1,200 price tag. It’s aimed at AI inference, not gaming, but the cost-per-VRAM looks spicy for local LLMs. Listings and reports suggest shipments started in China mid-month.
Other
Chess match
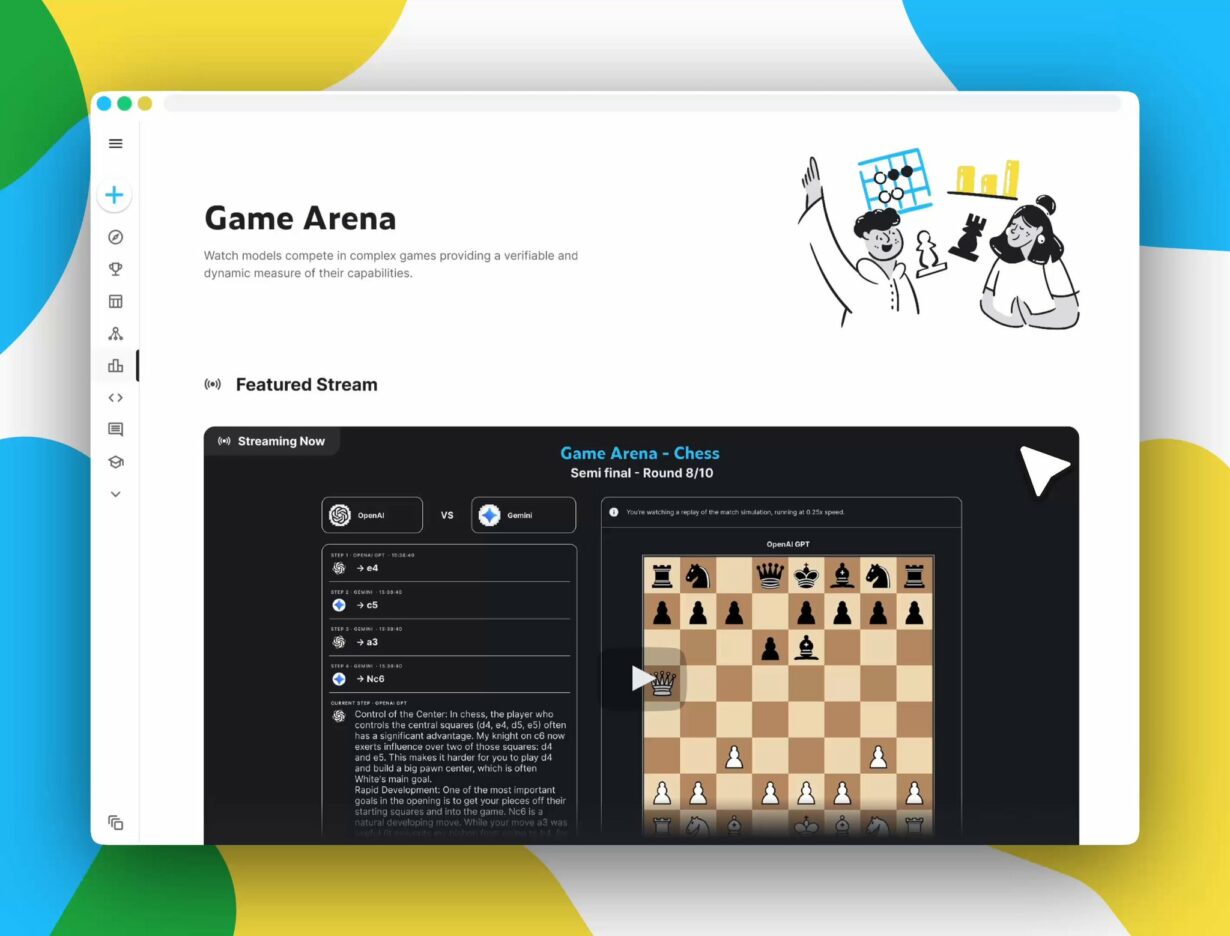
Kaggle’s new Game Arena opened with an AI chess exhibition (Aug 5 – 7). Eight frontier models duked it out; OpenAI’s o3 swept xAI’s Grok 4 in the final 4-0. Yes, there were brackets. Yes, commentators roasted the blunders. Peak 2025.
Fine-tuning GPT-OSS (keeping FP4)

LMSYS + NVIDIA showed how to fine-tune GPT-OSS while preserving MXFP4 quantization. The method recovers accuracy without reverting to bf16, demonstrated across multilingual and refusal-reduction tasks, and is deployable via SGLang.
NVIDIA paper on efficient LLMs

NVIDIA introduced PostNAS, a way to redesign attention blocks after pretraining. Their 2B/4B hybrids reported ~47× throughput gains vs Qwen3-1.7B at 64k tokens on H100s, while holding competitive accuracy. Could make “efficient by design” the new default.
Rendergit
Andrej Karpathy open-sourced rendergit: point it at any repo and it flattens everything into a single static HTML page – with a special “LLM view” for copy-pasting into chatbots. The “just show me the code” crowd rejoiced.
Fun Corner
And because AI isn’t all benchmarks and GPUs… we’re bringing a new section to our “Last Month in AI.”
Welcome to the Fun Corner!


Summary
That’s a wrap for this month’s edition!
August was packed: new flagships, smarter open-weights, tiny-but-mighty TTS models, creative image editing breakthroughs, and hardware shakeups from both the usual suspects and new challengers. It was a month where frontier labs pushed harder, open-source matched pace, and the AI ecosystem showed just how wide – and weird – it can get.
See you in the next edition – until then, keep exploring, keep building, and maybe even let your favourite model play a round of chess.
Want to learn more?
Explore our blog for detailed guides, technical tutorials and much more!
- Why Scala Days 2025 is a must-attend for CTOs – and where to find scalac there?
- Rust vs Scala: a technical developer’s perspective
- Scalendar September 2025
Also, don’t forget to join Scalac’s Talent Pool!
Check more here https://scalac.io/blog/scala-rust-devops-frontend-careers/

Authors

An AI expert and Scala developer at Scalac, providing ongoing analysis of key developments in artificial intelligence. Scalac's go-to specialist for AI trends and applications. His work bridges the gap between AI research and practical business implementation, making him a trusted voice not only among all the blog posts here, but in the AI community in general. Also, a proud owner of a Czechoslovakian Wolfdog, one of the closest-to-wolf dog breeds that you can legally own.






