THE SIGNAL: What matters in distributed systems | #4
June 2026 | Issue #4
Welcome back. AI coding agents pushed GitHub to 275 million commits a week, and Microsoft’s own cloud couldn’t keep up: enterprise SLAs slipped below 99.9% before Microsoft started routing overflow to AWS. A 119-point Hacker News thread argues that multi-agent coding tools quietly rediscovered a 40-year-old impossibility result.
Today: What to watch this month
- AI agents pushed GitHub to 275 million commits a week, and Microsoft ran out of Azure capacity to handle it. Enterprise SLAs fell below 99.9% in June. Microsoft is now routing overflow to AWS, a competitor’s cloud, as a stopgap.
- A Hacker News debate asks if multi-agent coding is a distributed systems problem. 119 points, 62 comments, real pushback on both sides.
- Apache Kafka 4.3.1 closes a native memory leak in Kafka Streams. RocksDB state stores leaked native memory on repeated open and close.
- JDK 27 locks its feature set. Compact object headers cut heap use 10-20%. G1 becomes the default collector everywhere.
- Scala’s codebase passes an independent security audit. OSTIF and Quarkslab did the review. Fixes shipped in Scala 3.8.4.
- An ex-Meta L8 shares an actual agentic engineering setup. One practitioner’s counterpoint to a rough month for AI-assisted engineering orgs.
- GitHub Copilot for JetBrains drops its own agent harness. Microsoft consolidates on Copilot CLI everywhere. JetBrains counters the same week with a self-hosted model.
The Architecture Debate: Is Multi-Agent Coding a Distributed Systems Problem?
A post by Kiran that spread fast this month argues that multi-agent AI coding systems inherit the coordination failures Fischer, Lynch, and Paterson proved impossible to solve in 1985, and draws the same line to the Byzantine Generals problem. Agreement among independent actors that can fail or communicate unreliably has no guaranteed-terminating solution. Point several coding agents at the same codebase and you built a consensus problem, whether you meant to or not. The Hacker News thread pulled 119 points and 62 comments, real engagement for a theory post.
Where the argument holds. Teams running parallel coding agents against shared state hit exactly the symptoms distributed systems engineers know by heart: stale reads, conflicting writes, work that silently duplicates because no agent knew another agent already finished it. Sequential stages with deterministic verification gates (plan, design, code, then a hard check before merge) work in practice precisely because they avoid the shared-mutable-state trap that makes consensus hard in the first place.
Where it breaks down. LLM agents are not independent actors in the Byzantine fault tolerance sense. They share weights and training data, so two agents facing the same ambiguous prompt tend to drift toward the same wrong answer instead of failing independently. That undermines the FLP framing, which assumes failures are uncorrelated. Commenters also point out that humans coordinate systems at Linux-kernel scale without a formal consensus proof in sight. Task scoping and clear specs do more work than any protocol.
Scalac angle: don’t reach for consensus algorithms to fix multi-agent coding chaos. Reach for the boring distributed-systems trick that actually works here: reduce shared mutable state. Give each agent an isolated workspace, a narrow task, and a deterministic gate before merge. If two agents must touch the same files, that’s a scheduling problem, not a Byzantine fault tolerance problem. Solve it with locks and ordering, not philosophy.
Notes from the Trenches: GitHub’s Infrastructure Cracks Under the AI Agent Load
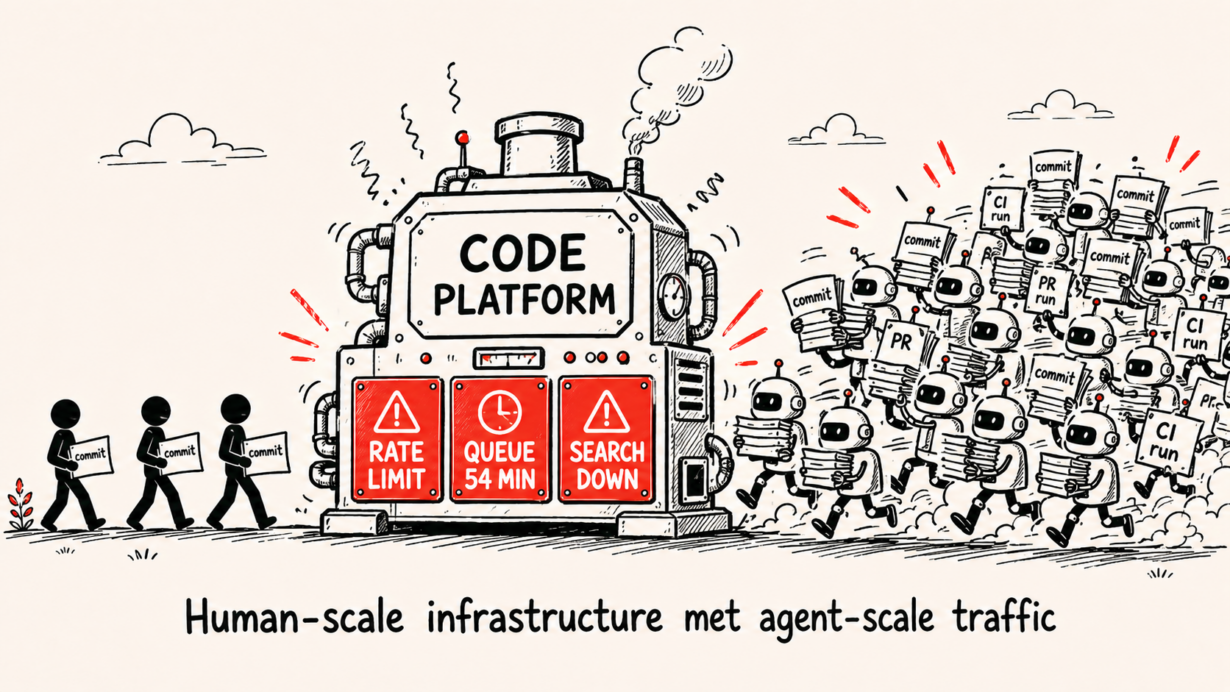
The problem: GitHub processed 1 billion commits across all of 2025. By April 2026, that pace hit 275 million commits a week, putting the platform on track for roughly 14 billion commits this year. GitHub COO Kyle Daigle put it plainly: “There were 1 billion commits in 2025. Now, it’s 275 million per week.” Claude Code alone went from about 100,000 commits a week in September 2025 to 2.6 million by April, a 25x jump in six months. AI agent pull requests grew from 4 million to 17 million over the same stretch, a 325% increase.
The infrastructure, built for human-scale commit patterns, buckled: on April 1-2, Copilot’s backend exhausted resources and went down for 2.7 hours, code search stayed offline for 8.7 hours, and emergency rate limiting degraded the Copilot Cloud Agent for four hours. The following week, agent session wait times hit 54 minutes against a normal baseline of 15-40 seconds, and session startup failures briefly spiked to 97.5%. May added nine more outages. By June, availability had dropped below the 99.9% enterprise SLA threshold.
The solution, for now. Microsoft confirmed on June 16 that it’s routing GitHub’s burst compute and storage load, specifically GitHub Actions runners and Codespaces, to AWS, a competitor’s cloud. Azure’s own data center expansion is underway but construction and hardware procurement run 18-24 months. Routing overflow to AWS is a bridge, not a fix, while that capacity comes online.
Scalac angle: capacity models built around human developer behavior don’t transfer to agent-driven traffic. Agents commit more often, open more pull requests, and run in bursts tied to session length rather than working hours. If you’re scaling infrastructure for agent workloads, load-test against agent-shaped traffic specifically, not a scaled-up version of your human usage curve, and keep a real multi-cloud escape hatch ready before you need it. Microsoft had one. Building yours after the outage starts is too late.
Signal Over Noise: Three Critical Changes This Month
1. Apache Kafka 4.3.1 closes a native memory leak in Kafka Streams
Kafka 4.3.1 fixes roughly 15 issues, and the headline one is KAFKA-20616: createOffsetsCFOptions() created a ColumnFamilyOptions object that was never stored or closed, and on the JNI side that silently allocates an 8 MB LRUCache every time. The leak multiplies per segment and per task, hitting windowed stores hardest. A second bug on the close path skipped handle cleanup entirely when an exception fired during EOSv2 shutdown, because the cleanup ran outside a finally block. If you run Kafka Streams with RocksDB state stores, especially windowed ones, upgrade to 4.3.1 and check native memory usage trends over the following week, not just at deploy time.
2. DK 27 locks its feature set
JDK 27 forked off for its rampdown phase on June 4, and the feature list is now frozen. Compact object headers become the default header layout; in the JEP’s own SPECjbb2015 benchmarks that cuts heap usage 22% and CPU time 8%, with 15% fewer garbage collections under G1 and Parallel. G1 becomes the default garbage collector in every environment, not just server-class machines. JFR gets data redaction for secrets (JEP 536), and jcmd gains post-mortem core dump analysis (JEP 528). Oracle deprecates the macOS/x64 port for removal. If you run distributed systems on the JVM at scale, the heap reduction alone is worth planning a JDK 27 upgrade around once it ships, independent of any other feature.
3. Scala’s codebase passes an independent security audit
Quarkslab’s audit of the Scala codebase, commissioned through the Open Source Technology Improvement Fund and published in March, found no critical or major issues: 5 medium, 1 low, and 2 informational findings, all fixed. Scala 3.8.4, released June 5, ships those fixes. Alongside it: the REPL now ships as a separate artifact, scala3-repl, a breaking change for any project or tool that assumed it came bundled. If your tooling shells out to the Scala REPL, add the explicit dependency before you upgrade, not after something breaks in CI.
Community Voice
Scala tooling caught a real practitioner’s attention this month. Yann Moisan writes about running Claude Code against a Scala codebase, working around the lack of native Scala support by wiring up Metals, the Scala language server, as a standalone MCP server. Moisan synthesizes: “This setup is particularly useful when you want Claude Code to reason about your Scala project with full awareness of its structure, dependencies, and compiler errors rather than treating it as plain text.” On the build-tool tradeoff, he’s specific: “The tradeoff is stability vs. efficiency. With sbt, metals and sbt compile independently (double compilation).”
The pattern generalizes past Scala. Any statically typed language with a mature language server gets the same upgrade: point your agent at the compiler’s own understanding of the code, not just the text of it.
In the Know
GitHub Copilot for JetBrains deprecates its local agent harness — Microsoft consolidates on Copilot CLI as the default harness across every surface. JetBrains counters the same window with Mellum2, a self-hosted, on-premises model. One harness everywhere versus own your model and your harness: a real fork in agent-tooling philosophy.
SIP-80: Target-Typed Companion Shorthand — Less .apply ceremony in generic code.
sbt 2.0.0-RC15 — Another release candidate down. Plugin compatibility remains the last blocker before GA.
Top Resources
Repo to watch: kstreamplify
Michelin’s open-source Kafka Streams utility library: bootstrapping, error handling, serialization, Kubernetes integration, in pure Java. Shipped v1.8.0 on June 29. Pairs directly with this month’s Kafka Streams memory-leak fix if you’re standardizing on shared Streams tooling.
Article to read: “An Ex-Meta L8’s Agentic Engineering Setup”
Kun Chen, a former Meta principal engineer, runs a terminal-first setup: WezTerm, Neovim, and Tmux, Claude Code for Anthropic’s models and OpenCode for everything else, voice input through a local Whisper model, and custom tooling to manage parallel git worktrees and validate agent output before it merges. The operating principle: direct the agents like an engineering manager, stay focused on what to build and whether it works, not on typing the code yourself.
Paper to read: “Reaching Agreement Among Reasoning LLM Agents”
A formal consensus protocol for multi-agent LLM systems with provable safety and liveness guarantees, cutting latency 1.2-20x versus ad-hoc orchestration baselines while keeping answer quality within 2.5% of uncoordinated baselines. Classical consensus theory applied directly to the systems this issue’s Debate argues already need it.
What is SIGNAL?
SIGNAL is a monthly, opinionated newsletter for JVM and Scala teams who run real distributed systems. Each issue has three sections — Architecture Debate, Notes from the Trenches, Signal Over Noise — and focuses only on changes and incidents that matter in production, not on hype or vendor marketing.
Scalac builds high‑throughput systems in Scala, Java, and Rust; SIGNAL is the filter we wish we had when making our own architecture bets.
References
- TechTimes. GitHub’s AI Agent Crisis Forces Microsoft to Tap AWS as Outages Break Enterprise SLAs. June 16, 2026. https://www.techtimes.com/articles/318481/20260616/githubs-ai-agent-crisis-forces-microsoft-tap-aws-outages-break-enterprise-slas.htm
- Zen van Riel. GitHub Infrastructure Buckles Under AI Agent Commits. https://zenvanriel.com/ai-engineer-blog/github-ai-agent-commits-infrastructure-crisis/
- CNBC. Microsoft’s GitHub Was Positioned to Win the AI Coding Race. Outages Got in the Way. May 22, 2026. https://www.cnbc.com/2026/05/22/microsoft-was-positioned-to-win-in-ai-coding-outages-got-in-the-way.html
- Kiran. Multi-agentic Software Development Is a Distributed Systems Problem (AGI Can’t Save You From It). https://kirancodes.me/posts/log-distributed-llms.html
- Hacker News discussion of the above, 119 points, 62 comments. https://news.ycombinator.com/item?id=47761625
- Apache Kafka 4.3.1 Release / KAFKA-20616. https://kafka.apache.org/downloads https://issues.apache.org/jira/browse/KAFKA-20616
- OpenJDK. JDK 27 Project Page. https://openjdk.org/projects/jdk/27/
- JEP 534: Compact Object Headers by Default. OpenJDK. https://openjdk.org/jeps/534
- JEP 523: Make G1 the Default Garbage Collector in All Environments. OpenJDK. https://openjdk.org/jeps/523
- Quarkslab. Scala Security Audit. https://blog.quarkslab.com/scala-security-audit.html
- Scala 3.8.4 Release Notes. The Scala Programming Language. https://www.scala-lang.org/news/3.8.4/
- This Week in Scala. June 1, 2026. https://thisweekinscala.substack.com/p/this-week-in-scala-jun-1-2026
- Yann Moisan. Scala with Claude Code. https://www.yannmoisan.com/scala-with-claude-code.html
- ByteByteGo. An Ex-Meta L8’s Agentic Engineering Setup. June 23, 2026. https://blog.bytebytego.com/p/an-ex-meta-l8s-agentic-engineering
- Microsoft DevBlogs. GitHub Copilot for JetBrains Is Moving to Copilot CLI as the Default Agent Harness. https://devblogs.microsoft.com/java/github-copilot-for-jetbrains-is-moving-to-copilot-cli-as-the-default-agent-harness/
- SIP-80: Target-Typed Companion Shorthand. Scala Improvement Proposals. https://github.com/scala/improvement-proposals/pull/134
- sbt 2.0.0-RC15 Releases. GitHub. https://github.com/sbt/sbt/releases
- Michelin. kstreamplify. GitHub. https://github.com/michelin/kstreamplify
- Ruan, Wang, Shi, Li. Reaching Agreement Among Reasoning LLM Agents (Aegean). arXiv, December 2025. https://arxiv.org/abs/2512.20184