

Last month in AI – November 2025
November was the month AI went full gladiator mode: three frontier labs released their best models within a week, Google reclaimed the throne with Gemini 3, and open source proved it can win Olympic gold medals in mathematics. Meanwhile, the agent revolution became official doctrine at Microsoft and Google, and China’s AI ecosystem hit escape velocity with 10 million app downloads in seven days. If October was the “agent uprising,” November was the “model wars finale.” 🏆
Models
Google Gemini 3 Pro

https://deepmind.google/technologies/gemini/
Google didn’t just catch up in November—they lapped the competition. Gemini 3 Pro, launched November 18, sits at #1 on LMSYS Arena and tops benchmarks for text generation, image editing, image processing, and text-to-image. It solved 5 out of 6 IMO 2025 problems in “Deep Think” mode, a feat that would earn a silver medal at the International Mathematical Olympiad. The model was trained exclusively on Google’s Tensor TPUs, not Nvidia GPUs, which sent Broadcom’s stock soaring on chip demand and sparked a new hardware narrative: ASICs are back. Over 1 million users tried Gemini 3 in its first 24 hours, and Google’s stock jumped 8% in a week. The model integrates into Search, Maps, Vertex AI, and the new Google Antigravity agentic development platform. Pricing runs $10–20 per million tokens, and early reviews call it a “vending machine simulator champ” for long-term decision-making. After years of playing catch-up to ChatGPT, Google is finally back in the lead.
Claude Opus 4.5

https://www.anthropic.com/news/claude-opus-4-5
Anthropic dropped Claude Opus 4.5 on November 25, right before Thanksgiving, and it’s the efficiency king of November’s model wars. It scores 80.9% on SWE-bench Verified for coding and research tasks, outpacing Sonnet 4.5 in both speed and cost. The price dropped 67% to $5 per million tokens, making it cheaper than Sonnet 4 for most workloads. The killer feature is the new effort parameter, which lets developers control how much computational effort Claude spends on a problem. At medium effort, Opus 4.5 matches Sonnet 4.5’s performance while using 76% fewer output tokens. At highest effort, it exceeds Sonnet 4.5 by 4.3% while still using 48% fewer tokens. Early testers say it “just gets it”—handling ambiguity and reasoning over tradeoffs without human intervention. Tasks that were “near-impossible for Sonnet 4.5 just a few weeks ago are now within reach.” It’s live in the Claude app and API, and developers on X are calling it “the best model release in a long time” for programming. Opus 4.5 wins the “Triple Crown” on the LMArena leaderboard, taking #1 in the Expert Arena. If Gemini 3 is the benchmark champion, Opus 4.5 is the pragmatist’s choice.
OpenAI GPT-5.1

https://help.openai.com/en/articles/6825453-chatgpt-release-notes
OpenAI released GPT-5.1 on November 12, and it’s all about personality and adaptability. The update introduces two variants: GPT-5.1 Instant (warmer, more conversational) and GPT-5.1 Thinking (adapts thinking time to question complexity). The headline feature is personality presets: users can now choose from Cynical, Nerdy, Default, Friendly, Efficient, Professional, Candid, and Quirky. GPT-5.1 Instant uses adaptive reasoning to decide when it should think before responding, delivering thorough answers without sacrificing speed. GPT-5.1 Thinking spends longer on complex problems and shorter on simple prompts, with clearer responses and less jargon than GPT-5. On benchmarks, it hits 87.5% on ARC-AGI (up from o3’s 75%) and 25% on Frontier Math. It also powers a new Codex-Max variant for full-project coding. API pricing runs $5–15 per million tokens, and it’s already the default in Microsoft Copilot. The personality presets are a subtle but significant shift: OpenAI is betting that AI customization matters more than raw performance gains. If Gemini 3 is the benchmark king and Opus 4.5 is the efficiency champion, GPT-5.1 is the chameleon—adapting its tone, style, and reasoning depth to match the user.
DeepSeek V3.2 & V3.2 Speciale

https://huggingface.co/deepseek-ai/DeepSeek-V3.2
DeepSeek dropped a bombshell on December 1 (technically just hours after November ended, but too significant to ignore): DeepSeek V3.2 and DeepSeek V3.2 Speciale, two models that rival GPT-5 and Gemini 3 Pro—and they’re totally free. The standard V3.2 is designed as an everyday reasoning assistant, while V3.2 Speciale is the high-powered variant that achieved gold-medal performance in four elite international competitions: 2025 IMO (35/42 points), International Olympiad in Informatics (492/600, ranked 10th), ICPC World Finals (10/12 problems, 2nd place), and China Mathematical Olympiad. On AIME 2025, Speciale hit 96.0% pass rate (vs GPT-5-High’s 94.6% and Gemini 3 Pro’s 95.0%). In the Harvard-MIT Mathematics Tournament, it scored 99.2% (vs Gemini’s 97.5%). For coding, V3.2 resolved 73.1% of real-world bugs on SWE-Verified (competitive with GPT-5-High’s 74.9%) and scored 46.4% on Terminal Bench 2.0 (vs GPT-5-High’s 35.2%). The secret sauce is DeepSeek Sparse Attention (DSA), an efficient attention mechanism that reduces computational costs while maintaining quality on long contexts. The company acknowledges that “token efficiency remains a challenge”—DeepSeek typically requires longer generation trajectories to match Gemini’s output quality. But the results speak for themselves: open-source just matched GPT-5. The models are MIT-licensed and available on Hugging Face. V3.2 Speciale is API-only until December 15, when its capabilities merge into the standard release. This is the model that proves China’s AI labs are no longer playing catch-up—they’re leading.
DeepSeek Math V2

https://huggingface.co/deepseek-ai
DeepSeek also released Math V2 on November 25, a mathematical prodigy that won gold at IMO 2025 and scored 118/120 on Putnam 2024. It’s fully MIT-licensed, uses hybrid “thinking/non-thinking” modes for efficiency, and was trained for just $294,000—1000x cheaper than comparable Western models. Math V2 excels in verifiable reasoning, and developers on X are already forking it for custom math agents. It’s available for free download on Hugging Face.
Allen Institute OLMo 3
The Allen Institute for AI (Ai2) released OLMo 3 on November 27, and it’s the transparency champion of November. The OLMo 3 family spans 7B to 70B parameters, and unlike most “open-source” models that only release weights, OLMo 3 releases everything: weights, training data, training pipeline, and evaluation code. It’s a 100% open model in the truest sense. OLMo 3 is strong in reasoning and code, and it’s designed for researchers who want to audit biases, understand failure modes, or experiment with training techniques. In an era where “open-source” often means “weights only,” OLMo 3 is a transparency flex. It’s free to download, and it’s already being used in academic labs to study how LLMs learn. If you believe that AI safety requires full transparency, OLMo 3 is the model to watch.
Alibaba Qwen3 Variants

Alibaba released multiple Qwen3 variants in early November, including Qwen3 Instruct (235B parameters) and Qwen3 Coder (32B parameters). The models feature a “thinking budget” mechanism that allows developers to control how much computational effort the model spends on reasoning, similar to Claude’s effort parameter. Qwen3 tops benchmarks for controllable multilingual work, and it’s fully open-sourced. But the real story is the Qwen AI app, which launched in China and hit 10 million downloads in its first week. That’s explosive adoption, and it signals that China’s AI ecosystem is no longer just catching up—it’s pulling ahead in domestic markets. Alibaba is positioning Qwen as the “AI-powered gateway to daily life,” and if the download numbers are any indication, they’re succeeding.
Moonshot Kimi K2 Thinking

https://huggingface.co/Moonshot
Moonshot AI released Kimi K2 Thinking on November 6, and it’s the agentic sleeper hit of November. The model cost just $4.6 million to train, and it can auto-select 200–300 tools for complex tasks, beating ChatGPT in agentic workflows with minimal human input. It’s popular in China as a cheaper OpenAI alternative, and developers on X are praising its ability to chain tools together without constant prompting. Kimi K2 is proof that agentic AI doesn’t require frontier-scale budgets—you can build a competitive agent for less than $5 million.
IBM Granite 4.0 Nano

https://huggingface.co/ibm-granite
IBM released Granite 4.0 Nano in the first week of November, and it’s the ultra-small LLM that punches above its weight. The Nano family includes models as small as 350M parameters, yet they outperform much larger models in knowledge, math, and code tasks. Granite 4.0 Nano is Apache 2.0-licensed, making it fully open for commercial use, and it’s optimized for edge devices such as smartphones and IoT hardware. If you need an LLM that runs on a Raspberry Pi, Granite 4.0 Nano is your choice.
GigaAI GigaBrain-0 VLA
GigaAI dropped GigaBrain-0 VLA on November 28, and it’s the robotics breakthrough of the month. VLA stands for vision-language-action, and GigaBrain-0 is an open-source model that matches π0.5 performance on embodied tasks. It was trained on 1000+ hours of real-world robot data and uses an end-to-end PaliGemma2 base for planning and execution. Code and weights are available on GitHub, and robotics researchers on X are calling it a step toward “model-to-body” convergence—the idea that a single model can control multiple robot form factors. If you’re building robots, GigaBrain-0 is the model to start with.
Hardware
Google Ironwood TPU + Gemini 3

Google’s Ironwood TPU isn’t just a chip—it’s a strategic weapon in the AI hardware wars. Paired with Gemini 3, Ironwood challenges Nvidia’s dominance by proving that ASICs (application-specific integrated circuits) can compete with GPUs for AI training and inference. Gemini 3 was trained exclusively on TPUs, not Nvidia GPUs, and the results speak for themselves: #1 on LMSYS Arena. The Ironwood announcement sent Broadcom’s stock soaring on chip demand, and it sparked conversations about whether the industry is entering a post-GPU era. Nvidia still dominates with 62% year-over-year sales growth, but Google’s TPU strategy is forcing the market to reconsider the GPU monopoly. Meta is reportedly in talks with Google about buying Tensor chips, and Anthropic announced in October that it plans to significantly expand its use of Google’s TPU technology. The message is clear: Nvidia isn’t the only game in town anymore.
Qualcomm Snapdragon 8 Gen 5

https://www.qualcomm.com/snapdragon
Qualcomm unveiled Snapdragon 8 Gen 5 in November, promising AI performance leaps for flagship smartphones. The chip is designed for on-device AI, enabling models like Granite 4.0 Nano and MobileLLM-Pro to run locally without cloud connectivity. Qualcomm is betting that the future of AI is edge-first, and Snapdragon 8 Gen 5 is their answer to Apple’s M-series chips. The chip also challenges Nvidia at the low end of the AI hardware stack, where power efficiency matters more than raw performance.
Baidu’s AI Chip Push

Baidu emerged as China’s AI chip powerhouse in November, mixing self-developed silicon with Nvidia GPUs to power its ERNIE models. Baidu’s hybrid approach—custom ASICs for specific tasks, Nvidia GPUs for general training—mirrors Google’s TPU strategy. It’s a sign that Chinese AI companies are no longer content to rely on U.S. chip exports. Baidu is also reportedly working on next-generation chips that could rival Nvidia’s H100 in performance.
AMD Ryzen AI Max+ 395: vLLM Support Arrives

https://github.com/vllm-project/vllm/pull/25908
AMD’s Ryzen AI Max+ 395 got official vLLM support in late November, and it’s a game-changer for local AI. vLLM is the go-to standard for deploying and testing LLMs, and the Ryzen AI Max+ 395 is a 128GB unified memory beast that can run massive models locally. The PR adds support for the entire AI 300 series (gfx1150 and gfx1151), making these chips some of the least expensive vLLM dev options available. Early adopters on r/LocalLLaMA are already experimenting with tensor parallel setups using multiple 128GB machines connected via RDMA NICs, enabling models 10x larger than typical 24GB consumer setups. One user reports organizing a “big nerd meetup” with four 128GB machines to test scaling. The Ryzen AI Max+ 395 is a true unicorn—a laptop chip with desktop-class AI capabilities. AMD is positioning it as the edge AI champion, and with vLLM support, it’s now a serious contender for developers who want to run frontier models locally without cloud dependency. The catch: ROCm support is still rough (FlashAttention doesn’t work automatically, AITER is “a big mess”), but the community expects these issues to smooth out in a few weeks. If AMD can nail the software stack, Ryzen AI Max could be the Nvidia killer for local AI.
Intel Rumors: Apple M-Chips by 2027

Intel’s stock jumped 7.9% in November on rumors that the company will supply low-end Apple M-chips by 2027. If true, this would mark a dramatic reversal of fortune for Intel, which lost Apple’s business to ARM-based chips in 2020. The rumor suggests that Apple is hedging its bets on chip supply, and Intel is positioning itself as a backup supplier in case TSMC faces geopolitical disruptions. It’s a long shot, but the market is betting on it.
Other
Microsoft Agent 365

https://www.microsoft.com/en-us/microsoft-365/blog/2025/11/microsoft-agent-365
Microsoft unveiled Agent 365 at the Ignite conference in November, and it’s the unified control plane for agents that the industry has been waiting for. Agent 365 allows enterprises to manage agents created in Microsoft’s ecosystem and third-party agents from partners like Anthropic, OpenAI, and Google. Microsoft’s vision is “Frontier Firms”—organizations that are human-led and agent-operated. Agent 365 is the infrastructure to make that vision real. It includes monitoring, governance, and orchestration tools, and it integrates with Microsoft 365 Copilot to give every employee an AI assistant. The announcement positions Microsoft as the enterprise agent platform, and it’s a direct challenge to Google’s Antigravity and OpenAI’s agent ecosystem.
Google Antigravity

https://developers.googleblog.com/google-antigravity
Google launched Antigravity on November 18, coinciding with the Gemini 3 release. Antigravity is an agentic development platform that Google describes as “an evolution of the IDE into an agent-first future.” It includes browser control and asynchronous interaction patterns, allowing developers to build agents that can run for longer periods without human intervention. Google’s pitch is that with models like Gemini 3, we’re entering a world where agents operate at higher abstractions than individual prompts and tool calls. Antigravity is the platform to build those agents. It’s a direct competitor to Microsoft’s Agent 365, signaling that the agent wars are heating up.
Cloudflare Acquires Replicate

https://blog.cloudflare.com/cloudflare-acquires-replicate
Cloudflare announced the acquisition of Replicate in November, bringing 50,000+ production-ready AI models into the Cloudflare Workers AI ecosystem. Replicate is an AI platform that allows developers to deploy and run AI models with minimal infrastructure overhead. Cloudflare’s pitch: “Access any AI model globally with just one line of code.” The acquisition turns Cloudflare Workers into a leading platform for building and running AI applications, and it’s a direct challenge to AWS Lambda, Google Cloud Functions, and Azure Functions. Existing Replicate users can continue using their APIs without interruption, and they’ll soon benefit from Cloudflare’s global network.
OpenAI IndQA Benchmark

https://openai.com/research/indqa
OpenAI launched IndQA in November, a new benchmark for evaluating AI models across 12 Indian languages and 10 cultural domains. The benchmark includes 2,278 questions created with help from 261 domain experts from India, including journalists, linguists, scholars, artists, and industry practitioners. OpenAI’s argument: existing multilingual benchmarks like MMMLU are saturated (top models cluster near high scores) and translation-focused (they don’t measure cultural understanding). IndQA is designed to evaluate how well models understand regional context, culture, and history. It’s a recognition that English-only benchmarks are insufficient for a global AI ecosystem, and it’s a signal that OpenAI is serious about serving non-English markets. India is OpenAI’s second-largest market, and IndQA is the first step toward building models that truly understand Indian languages and culture.
Microsoft .NET 10 (LTS)

https://devblogs.microsoft.com/dotnet/announcing-dotnet-10
Microsoft released .NET 10 in November, the latest Long Term Support (LTS) release that will receive support for the next three years. .NET 10 is packed with AI features, including the Microsoft Agent Framework for building agentic systems, Microsoft.Extensions.AI, and Microsoft.Extensions.VectorData for integrating AI services and built-in MCP support. Microsoft is positioning .NET 10 as the platform for AI-native applications, and it’s a clear signal that the company sees agents as the future of software development.
MCP Specification Update (1-Year Anniversary)

https://modelcontextprotocol.io
November marked the one-year anniversary of Anthropic’s Model Context Protocol (MCP), and the project was celebrated with a major specification update. The new release includes support for task-based workflows (experimental), which provides a new abstraction for tracking the work an MCP server performs. Tasks support multiple states: working, input_required, completed, failed, and cancelled. The update also enables active polling to check the status of ongoing work and to retrieve results for completed tasks. Anthropic’s pitch: “It’s hard to imagine that a little open-source experiment, a protocol to provide context to models, became the de facto standard for this very scenario in less than twelve months.” MCP is now supported by Cloudsmith, Linkerd, .NET 10, and dozens of other platforms. It’s the infrastructure layer for the agent ecosystem.
Legit Security VibeGuard

https://www.legitsecurity.com/vibeguard
Legit Security released VibeGuard in November, an AI agent for securing AI-generated code. VibeGuard links directly into a developer’s IDE to monitor agents, prevent attacks, and prevent vulnerabilities from reaching production. It also injects security and application context into AI agents to train them to be more secure. According to Legit Security’s research, 56% of security professionals cite lack of control over AI-generated code as a top concern. VibeGuard is the first product designed specifically to address that concern, and it’s a sign that AI security is becoming a category of its own.
Webflow App Gen
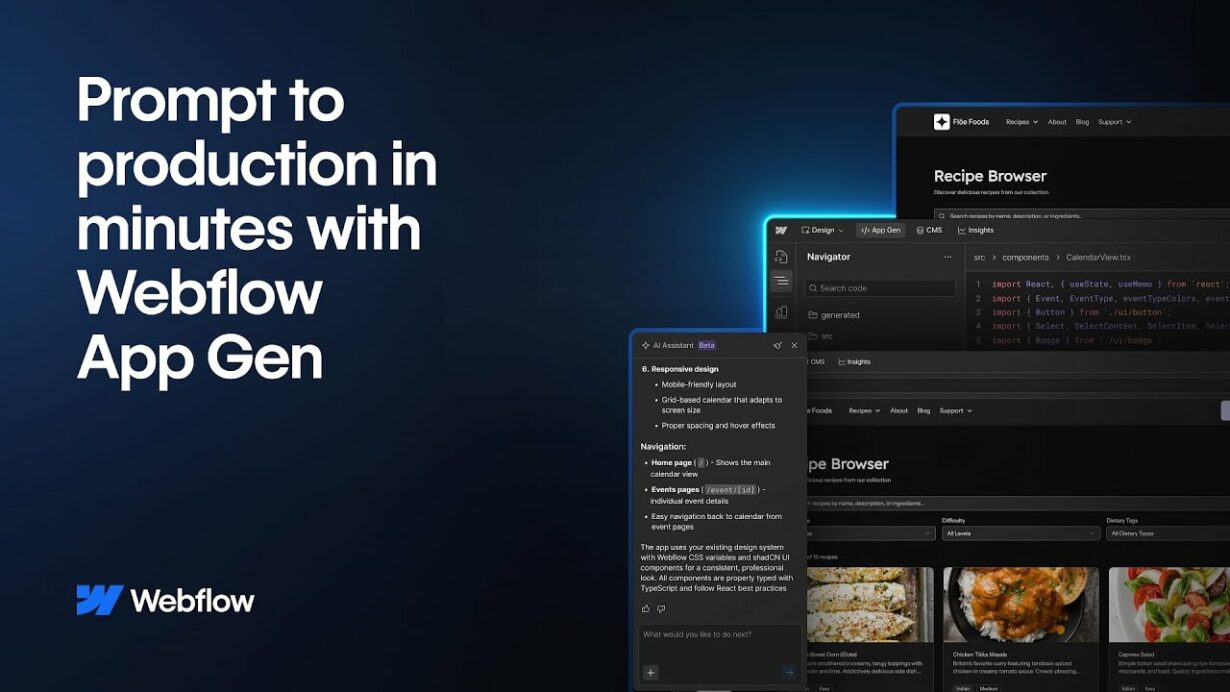
Webflow launched App Gen in November, a new vibe coding capability that allows users to create web experiences without coding skills. App Gen leverages a site’s existing design system, content, and structure to ensure brand consistency, and it can reuse existing Webflow components. It automatically applies typography, colors, and layout variables, and it connects to the site’s CMS to turn structured content into data-driven interfaces. Webflow is positioning App Gen as the evolution from creating websites to creating web experiences, and it’s a direct challenge to no-code platforms like Bubble and Framer.
Alibaba Qwen App: 10M Downloads in Week 1

https://www.zdnet.com/article/alibabas-qwen-ai-chatbot
Alibaba’s Qwen AI app hit 10 million downloads in its first week post-public beta, marking explosive growth in domestic adoption. The app is currently only available in China, and Alibaba describes it as “the AI-powered gateway to daily life.” The download numbers suggest that China’s AI ecosystem is no longer just catching up to the West—it’s pulling ahead in consumer adoption. Qwen integrates with Alibaba’s e-commerce, payments, and cloud services, making it a super-app for AI-powered tasks. If Qwen can maintain this growth trajectory, it could become the WeChat of AI.
Nvidia Stock: Down 10% in November, Up 33% YTD

Nvidia’s stock was down 10% in November despite being up 33% year-to-date. The November dip reflects concerns about valuation and competition from Google’s TPUs, Qualcomm’s AI chips, and Baidu’s custom silicon. Nvidia still dominates the AI hardware market with 62% year-over-year sales growth and 65% profit growth, but the market is starting to price in the possibility that Nvidia’s monopoly is eroding. The company’s response: double down on full-stack offerings (GPUs + networking + software) and maintain the CUDA moat that makes it hard for developers to switch to competitors.
Oracle: Down 42% from Highs

Oracle’s stock tumbled 42% from its highs in November on debt fears. The company has been aggressively investing in AI infrastructure, including partnerships with OpenAI and Anthropic, but investors are worried about the debt load required to fund those investments. Oracle’s bet is that cloud AI infrastructure will be a multi-trillion-dollar market, but the market isn’t convinced yet. The stock decline is a reminder that AI infrastructure is capital-intensive, and not every company can afford to play the game.
Baidu Layoffs

Baidu kicked off major layoffs across units in November after Q3 losses, blaming AI growth slowdown. The layoffs are a sign that even China’s AI giants are feeling the pressure to cut costs and prove profitability. Baidu’s ERNIE models are competitive with Western LLMs, but the company hasn’t figured out how to monetize them at scale. The layoffs suggest that the AI bubble might be deflating, at least in China.
Fun Corner
This month’s fun corner theme is RAM prices… It’s not funny anymore.



Authors

An AI expert and Scala developer at Scalac, providing ongoing analysis of key developments in artificial intelligence. Scalac's go-to specialist for AI trends and applications. His work bridges the gap between AI research and practical business implementation, making him a trusted voice not only among all the blog posts here, but in the AI community in general. Also, a proud owner of a Czechoslovakian Wolfdog, one of the closest-to-wolf dog breeds that you can legally own.






