
Mocking Libraries can be your doom
Test automation is great. Nowadays, it’s become a crucial part of basically any software development process. And at the unit test level it is often a necessity to mimic a foreign service or other dependencies you want to isolate from. So in such a case, using a mock library should be an obvious choice that should make your life easier, right?
The thing is that it’s often a bad decision.
There are some more ways to solve this problem.
Let me explain with a few examples.
Why unit and integration tests are awesome
At the beginning of your product’s test automation journey, tests for the whole system seem to give the biggest bang for your buck. Just turn the entire thing on like a user would do and automate the typical things a typical user would try to do.
But as your project grows you quickly realize the tests are taking much more time and they’re executing so many sophisticated procedures that it’s harder and harder to find the bug and its root cause. And even when you do find it, the fix might consume a ton of developers’ time.
So, the right direction to go (actually from the very start) is to write tests for the individual, smaller parts of your product, which suddenly::
- increases the quality of your software
- makes it more robust
- helps you find bugs much earlier (in the software development process)
- helps you find bugs much faster (the smaller the piece of code you test, the shorter your test tends to be)
- solidifies the responsibilities definition of each software component (BDD testing style aims to be good at that especially)
What is a mock? (external service don’t hurt me)

A mock is a simulated object that mimics the behavior of real objects in controlled ways.
Simply speaking, it is supposed to replace the thing you’re trying to isolate from.

A program that prints out an automatically generated document.

When mocking a printer you can save time and paper and still test whether your program is generating your document correctly.
What is a mocking library?
A mocking library is a tool, that helps you:
- prepare mock objects
- dynamically replaces (monkeypatch) the real object with the mock object you have prepared
From the Java world, mockito and wiremock are really powerful mocking tools.
From the Python world the most popular libraries are probably mock and responses.
Example 1: mocking a peripheral
Starting with the gif example from above – a function that prepares a document and prints it out using a printer.
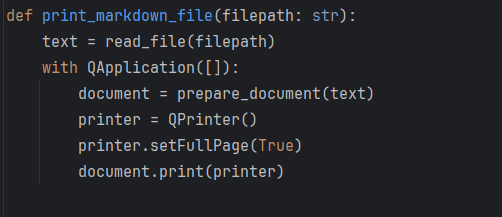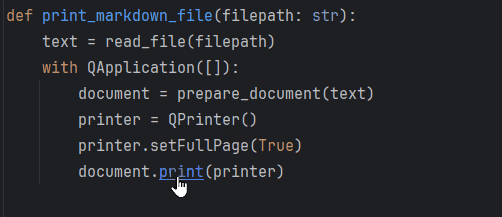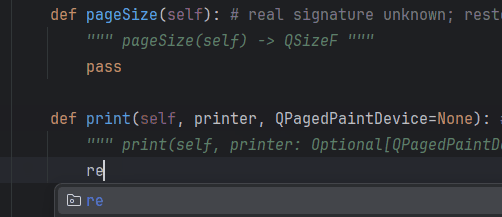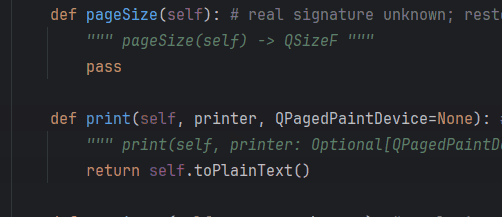
def print_markdown_file(filepath: str):
text = read_file(filepath)
with QApplication([]):
document = prepare_document(text)
printer = QPrinter()
printer.setFullPage(True)
document.print(printer)
return documentEvery time you run this function, document.print will use your printer and your precious ink. We don’t want that to happen in the unit tests, right?
And besides – unit tests need to work on other machines (almost always), including machines that don’t have access to your printer. So there goes one more reason to mock!.
Note: you can follow the full code examples here.
Monkey patching
We can monkeypatch the print method and verify it was called:
@patch.object(QTextDocument, "print")
def test_with_patching(mocked_print):
print_markdown_file("data/sample.md")
mocked_print.assert_called_once()Now, method document.print does nothing. Yay! 🎉🎊
We can now apply some behavior to the mock object. Let’s tell it to run QTestDocument’s “toPlainText” method instead of “print”:
def test_with_patching(mocker):
spy = mocker.spy(QTextDocument, "toPlainText")
with patch.object(QTextDocument, "print", lambda self, _: spy(self)):
print_markdown_file("data/sample.md")Just to illustrate – the patch.object in the code example above is (roughly) doing this:
Now let’s parametrize the test and add an assertion that the document was properly populated with text from the input file:
@pytest.mark.parametrize("md_filepath, expected", [
("data/sample.md", "I\nlove\npancakes\n\n\nPrinted by:\nMe")
])
def test_with_patching(mocker, md_filepath: str, expected: str):
spy = mocker.spy(QTextDocument, "toPlainText")
with patch.object(QTextDocument, "print", lambda self, _: spy(self)):
print_markdown_file(md_filepath)
assert spy.spy_return == expectedIf this looks complex to you, don’t worry. It is indeed difficult to read and requires some digging to understand.
And if you really want to dig more:
- md_filepath = “data/sample.md” from @parametrize decorator
- expected = “I\nlove\npancakes\n\n\nPrinted by:\nMe” from @parametrize decorator
- mocker is a pytest fixture I got by installing pytest-mock.
- patch.object is replacing member (2nd arg) of a given object (1st arg) with something else (3rd arg)
- lambda is a one-liner function that takes 2 args: self and printer. Since the printer is an unused variable, I used underscore mark (the commonly agreed marker for unused arg/variable, mentioned in PEP640 and acknowledged by some python linters, like pylint)
- spy is an object that behaves just like the provided method, but it additionally tracks its interactions and calls.
Dependency injection
What if we refactored the tested function so that it accepts any kind of printing function to print_markdown_file function as an argument?
def print_markdown_file(
filepath: str,
print_func: Callable[[QTextDocument], Any] = print_on_paper
):
content = read_file(filepath)
with QApplication([]):
doc = prepare_document(content)
print_func(doc)
return docAfter some changes, now print_markdown_file accepts one new kwarg, which by default is using print_on_paper function. We can now easily override that with a function that does nothing:
def test_with_di():
printed_document = print_markdown_file(
"data/sample.md",
print_func=lambda _: None)and verify that the document contains text from the provided sample.md file:
@pytest.mark.parametrize("md_filepath, expected", [
("data/sample.md", "I\nlove\npancakes\n\n\nPrinted by:\nMe")
])
def test_with_di(md_filepath: str, expected: str):
printed_document = print_markdown_file(md_filepath, print_func=lambda _: None)
assert printed_document.toPlainText() == expectedOverall, this solution has obvious advantages:
- It is undoubtedly cleaner and easier to read
- There is no mysterious dynamic object replacement
It’d be nice to also verify that print_func gets called with a document instance. Feel free to check the entire code example to learn more.
Example 2: mocking an external service
Now let’s take a look at a classic, a widely used HTTP API call example.
We’re going to calculate the value of the given amount of specified currency in PLN using current currency rates from the national Polish bank API.
def to_pln(currency: Currency, amount: float) -> float:
url = f"https://api.nbp.pl/api/exchangerates/rates/a/{currency}/last"
response = httpx.get(url)
response.raise_for_status()
mid = response.json()["rates"][0]["mid"]
return round(mid * amount, 2)Let’s prepare a test that will verify this function works as intended. And we will need to do it in such a way that it also works on machines without internet access.
Monkey patching with a generic mock
The first approach we could follow is to replace the get function from the httpx module with our own mock object that will respond statically with the same structure as the original API (see example).
def test_rate():
with patch.object(httpx, "get", return_value=MockedResponse()) as mocked_get:
pln = to_pln(Currency.EUR, 100)
assert pln == 650
mocked_get.assert_called_once_with("https://api.nbp.pl/api/exchangerates/rates/a/eur/last")I sprinkled one more assertion here to get bonus points for validating that httpx.get was called with expected arguments.
Looks not too bad actually! Now we only need to prepare the MockedResponse class so that it contains a fixed rate of 6.5.
After analyzing the source code, we can deduce that our MockedResponse must have 2 methods:
- raise_for_status()
- json() that returns a specific dictionary
class MockedResponse:
@staticmethod
def json():
return {"rates": [{"mid": 6.5}]}
@staticmethod
def raise_for_status():
passAfter implementing MockedResponse we successfully get a PASSED test result.
Monkey patching with a dedicated mock library
After installing pytest-httpx we gain new test readability superpowers. With its httpx_mock fixture, everything can be set and ready to go with a single line of code:
def test_rate(httpx_mock):
"""Make all HTTP requests always return this json."""
httpx_mock.add_response(json={"rates": [{"mid": 2}]})
pln = to_pln(Currency.EUR, 100)
assert pln == 200add_response method is doing the http requests monkey patching under the hood for us.
httpx_mock will also raise an exception if any of the defined responses are not used.
Pretty neat!
Dependency injection
How about we take the refactoring approach now? What if the http requests module was an input argument?
def to_pln(currency: Currency, amount: float, http_requests=httpx) -> float:
url = f"https://api.nbp.pl/api/exchangerates/rates/a/{currency}/last"
response = http_requests.get(url)
response.raise_for_status()
mid = response.json()["rates"][0]["mid"]
return round(mid * amount, 2)We can now call to_pln like so:
def test_to_pln():
result = to_pln(Currency.USD, 50, MockedRequests())
assert result == 150Crafting the MockedRequests class is now going to be pretty similar to the first approach. I’m going to try to make it look as simple as possible:
class MockedRequests:
def get(self, _):
return self
@staticmethod
def raise_for_status():
pass
@staticmethod
def json():
return {"rates": [{"mid": 3.0}]}With an instance of this class we can successfully run a test without any internet connection.
I might trigger some dependency injection fans here, but actually, if I was to mention the solutions above in order from most to least readable it would be:
dedicated mock library > dependency injection > generic mock library
| unittest.mock | pytest-httpx | dependency injection | |
| no object replacement at runtime | ✖️ | ✖️ | ✔️ |
| check url was called | with explicit assertion | ✔️ | needs manual implementation |
| additional lines of code to run this example | ~8 | ~1 | ~9 |
Note: this order is my personal opinion but it has proven itself in all the cases I have encountered during my career, – it doesn’t mean that using pytest-httpx is always the best solution.
Example 3: mocking AWS S3
This example explores dependency injection some more. It contains 4 mocking techniques which became a bit lengthy, so I decided to keep it on Github and attach it here for you as a bonus. Feel free to check it out here.
Conclusions
If you want your Unit Tests to be a breeze, you definitely need a plan. And during the planning process, it’s nice to remember a few things:
- Don’t over-define what Unit means in your project. Sometimes a single function is a good object to test in isolation while a whole bunch of files with several classes inside might do just as well as a unit in a different case. Consider these possibilities. Would it be easier to read and implement if the test covered a bigger / smaller chunk of code? Would it cover more or fewer scenarios? And finally, would it take more / less time to code such a test?
- Mocks are very useful, but if you happen to use a lot of them, your test will get complicated. Think about refactoring your dev code, enabling dependency injection to make your testing easier.
- When picking the right mocking technique, a general rule of thumb (based on my personal experience) would be to try to investigate a specific mocking library (if it exists) then check feasibility of dependency injection, and finally, use a generic monkey patch library as a last resort. This order might not be applicable for all scenarios and programming languages though, and picking the right technique ultimately comes with experience.
Read also:

Authors

Python developer / test automation specialist at Scalac. Teaching python at Merito university. Also, huge fan of pydantic, bouldering / via ferrata amateur, a bass player, currently learning korean for fun

Popular Posts in category

Looking into Scala.js

Your first microservices using Scala and Lagom
Handling Split Brain scenarios with Akka



