

Handling Split Brain scenarios with Akka
When operating an Akka cluster the developer must consider how to handle network partitions (Split Brain scenarios) and machine crashes. There are multiple strategies to handle such erratic behavior and, after a deeper explanation of the problem we are facing, I will try to present them along with their pros and cons using the Split Brain Resolver in Akka, which is a part of the Reactive Platform.
What exactly is the problem?
The basic is as follows – a node cannot differentiate between complete crashes and temporary network failures that could get resolved.
The network tracks the state and health of the nodes it contains using a “heartbeat”. This is a mechanism where each node sends a simple message in a given interval (for example with a time delta) to every other node that basically says “I’m OK”.
The system makes sure that all the messages have been received using “sink” node which collects the signals, orders them using a FIFO queue and eventually diagnoses if there are any problems with the ordering of the signals.
The problem is that if the heartbeat of a node stops, the network and other nodes cannot identify the reason why what was the reason the node stopped responding. Thus we can’t be sure whether the node may work again in the future and when it will happen (some network problem) or has permanently stopped working (for example the JVM or hardware crashed) and will not recover and should be discarded.
A network partition (a.k.a. Split Brain) is a situation where a network failure caused the network to split. The split means that the parts can no longer communicate with each other. They need to decide what to do next on their own based on the latest membership data of the cluster.
We can distinguish three main failure scenarios/categories: – Network partitions (split brain scenarios) – Crashes (JVM crash, hardware crash, etc.) – Unresponsive process (CPU starvation, garbage collector pauses, etc.)
How can we tackle this?
To be frank – there is no silver bullet for the problem described above. Each network needs to be analyzed individually for the optimal strategy to be chosen. The most widely used are: – Static Quorum – Keep Majority – Keep Oldest – Keep Referee
I will try to describe each one detailedly in the next sections along with their pros and cons.
Static Quorum
How it works?
This strategy will down the unreachable nodes if the number of remaining (healthy) nodes is equal or greater to a predefined constant number called the quorum size – i.e. this value defines the minimal number of nodes the cluster must posses to be operational.
When to use it?
It is best to use it when we have a fixed number of nodes in a cluster or when we can define a fixed number of nodes with a certain role.
Important notes
- One important rule regarding Static Quorum: You mustn’t add more nodes to the cluster than
quorum-size*2 -1as this can lead to a situation during a split where both clusters think they have enough nodes to function and try to down each other.
Keep Majority
How it works?
This strategy will down the unreachable nodes if the current one is part of the majority based on the last membership information, otherwise it will down the reachable part (the one it is a part of). If the parts are of equal size the one containing the node with the lowest address will be kept.
When to use it?
When the number of nodes in the cluster can change over time (it’s dynamic) and therefore static strategies like static-quorum won’t work.
Important notes
- A small chance exists that both parts have different membership information and thus produce different decisions. This can lead to both sides deciding to down each other as each one of them thinks they are the majority based on their membership information.
- If there are more than two partitions and none of them has a majority then each one of them will shutdown terminating the cluster
- If more than half of the nodes crash at the same time the remaining ones will terminate themselves based on the outdated membership information thus terminating the whole cluster.
Keep Oldest
How it works?
This strategy will down the part that does not contain the oldest node. The oldest member is important as the active Cluster Singleton runs on the oldest member.
When to use it?
When we use a Cluster Singleton and don’t want to shut down the node where it runs.
Important notes
- This strategy only cares where the oldest member resides, so e.g. we have a 2-98 split and the oldest member is among the 2 nodes then the other 98 will get shut down.
- There is a similar risk like the one described in the Keep Majority note – that both sides will have different information about the location of the oldest node. It can result in both nodes mutually trying to shut down one another, as each one think it possesses the oldest member.
Keep Referee
How it works?
This strategy will down the part that does not contain the given referee-node. The referee-node is an arbitrary member of the cluster we run the strategy on. It is up to us to specify which node would be suitable for this role. If the number of remaining nodes is less than a predefined constant called down-all-if-less-than-nodes then they will get shut down. If the referee node is removed then all nodes will get shut down.
When to use it?
When a single node is critical for the system running (the one we mark as the referee node).
Important notes
- This strategy creates a single point of failure by design (the referee node).
- It will never result in two separate clusters after a split occurs (as there can only be one referee node, thus one cluster alive).
Strategies in Akka
Here I will try to quickly show how to enable and configure the strategies that were explained in the previous section.
Enabling
You can enable a strategy in Akka with the configuration property akka.cluster.split-brain-resolver.active-strategy. All the strategies are inactive until the cluster membership and unreachable nodes information has been stable for a certain amount of time.
https://gist.github.com/anonymous/e2038e5cfc0b0587eaa313361c12546e
After a part of the split decides to shut down it will issue a shut down command to all its reachable nodes. But this will not automatically close the ActorSystem and exit the JVM, we need to do this manually in the registerOnMemberRemoved callback:
https://gist.github.com/anonymous/9da56f09c95c5362adbbfc85451b1a1e
Roles
Each node can have a configured role which can be taken into account when executing a strategy. This is useful when some nodes are more valuable than others and should be the last to terminate when needed.
Static Quorum in Akka
Enabling:
https://gist.github.com/anonymous/f1d858a88b4c171d841f06fa26709c56
Configuration:
https://gist.github.com/anonymous/89742d9057c29530bcc9359279687720
Keep Majority in Akka
Enabling:
https://gist.github.com/anonymous/671d95ab25915a7de30841e032443c8e
Configuration:
https://gist.github.com/anonymous/51c008c33348c1e6a32da3cec9df7cfb
Keep Oldest
Enabling:
https://gist.github.com/anonymous/e65519f4e79e6b1cbb37faf589c9a2ef
Configuration:
https://gist.github.com/anonymous/c68a4bd9ebecaca3073d7efe89f4a959
Keep Referee
Enabling:
https://gist.github.com/anonymous/c47b5f523a2490807d8cf7d304b3717f
Configuration:
https://gist.github.com/anonymous/fa945abcfb61516d41683fbad90f415b
Example
As an example I will create a Split Brain scenario using two computers – a MacBook Pro laptop and a Manjaro Linux box. Firstly, I’ll show how the clusters will behave without a Split Brain Resolver and then how they do with one. The partition will be fixed using the Keep Majority strategy.
Here is a diagram that represents the example network. The dashed lines are the Wi-Fi connections. Host1 is the Linux box, Host2 the MacBook:
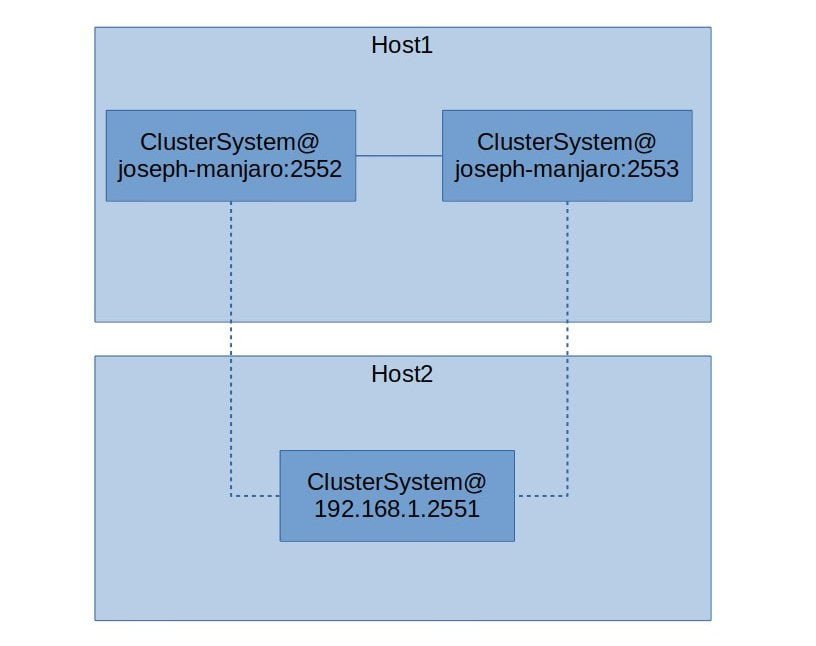
Before the Split
So here is the status of the Macbook node after startup and letting the Linux nodes join in. The Macbook node acts as the seed node:

As we can see evertything is fine. Here is the status of the two Linux nodes before the Split, the first one:

And the second node:

Ok, so let us produce two splits, one without the SBR and the second using the Keep Majority strategy.
After the Split (no SBR)
To create a Split I will simply turn off the Macbook’s Wi-Fi so it can’t communicate with the Linux box anymore. After about 10 seconds the clusters removed nodes from the other machine. On the Macbook:

The same on the Linux nodes, the first one:

The second one:

As we can see this results in two clusters which is a situation we want to avoid as this leaves us with two entities that can’t communicate. with each other. This means it can’t properly process data anymore and fails the CAP theorem requirement about Partition tolerance.
After the Split (Keep Majority)
So again we switch off the Wi-Fi on the Mac. After a short period of time the Keep Majority strategy is triggered in both clusters and the Macbook one should be downed as it is in the minority (1 Macbook node vs 2 Linux nodes).
Here is the Macbook node after the Split occured:

As we predicted the node has shut itself down and exited. Here is the node on the Linux box:

And the second one:

The Linux nodes were the ones left, just as we expected.
Links
Most of this article was based on the Akka documentation about this problem:
- Understanding Consensus
- Akka Split Brain Resolver
- How to handle network partitions with Akka
- Wikipedia article about the problem
- Split Brain in DBs analysis
Do you like this post? Want to stay updated? Follow us on Twitter or subscribe to our Feed.
More on Akka
- Websockets Server with akka-http
- Akka Streams and RabbitMQ
- TestContainers in Scala: Use Integration Tests for building your services
- How to implement streaming microservices with ZIO 2 and Kafka
- Programming in Scala: Carbon Footprint
Read more

Authors

I have a broad knowledge and extensive experience in developing high and low-level software using C, Python, Java, JavaScript and Scala. Haskell and FP enthusiast. My main non-IT hobbies and interests include music, playing guitar(s) and piano, politics, philosophy and ancient history (mainly Greek).
Popular Posts in category
Looking into Scala.js

Your first microservices using Scala and Lagom

User Authentication with Keycloak – Part 1: React front-end



