

Programming in Scala: Carbon Footprint
1. Introduction
There’s no question that now we are moving at a blazing pace in the epoch of the information age. It’s estimated that data volume generated by the ICT sector is approaching 100 zettabytes (100 billion terabytes) annually. To use this data, it needs to be captured, transferred, processed, and stored. And as the data keep scaling, the described processes follow to scale. Meaning that more hardware is needed to process more complex algorithms at the expense of consuming more energy.
Are there downsides to this?
As we all become more aware of the impact of carbon emissions on climate change, we might be aware of some bleak perspectives looming ahead. But to be aware of something is only the first step. It’s actions that matter. That’s why I, a professional software developer, have asked myself a question. Can the software I build do the right thing and join this race towards zero-emission (sustainable programming) as well?
But to answer this question, some other questions need to be answered first:
- Does the software leave a carbon footprint?
- How can a software developer reason about the environmental impact of his code?
- How can the carbon footprint be measured?
- How do the choices we make, writing software in Scala, affect sustainability?
- How else can I make my choices more environmentally friendly?
2. The software’s carbon footprint
Every code needs some resources to run it. By resources we mean two things: the hardware on which the code runs and the energy it needs to complete the task. Both these resources assume some carbon footprint. To describe carbon emissions from hardware utilization, we use the term embodied emissions. Embodied emissions are carbon emissions caused by the production of components. In contrast, the energy used to run a task implies the carbon footprint from electricity production. There are many ways to produce electricity. Although we use more and more renewable energy sources every year, 84% of the globally generated electricity still comes from fossil fuels, infamous for their high carbon footprint. Keep in mind that computations are global, too. This means that the emission types described are produced by the code running on the client devices, as with the code running on the servers in a data center.
So, how can code be sustainable?
By choosing more efficient and smart algorithms. Especially these algorithms which consider all of the above-described factors. Algorithms that take into consideration how much energy they use. Algorithms that prolong the hardware lifespan. To understand what I mean by this, let’s take a look at the following example:
A hard disk drive (HDD) construction comprises an array of magnetic disks, rotating at high speed, and a mechanical arm with a magnetic read/write head attached to it. Whenever an application requests an IO operation from the disk, the magnetic disks start to rotate and the arm moves to the addressed sector to start reading or writing data in blocks.

Because this operation is partially mechanical, the main HDD components are prone to wear and tear during heavy usage. That leads to the driver’s physical failure and the eventual need for replacement. A wrong algorithm for data storage on a disk can lead to data fragmentation. That in turn can lead to frequent random data access from distant disk segments. More moves and more wear lead to a shorter disk lifespan, which according to the research already averages between 2 to 5 years. On the other hand, DDR RAM doesn’t suffer from the same constraints and, in some cases, has a lifetime warranty, due to its unbounded lifespan. Add to this that DDR operational power is significantly less than that of HDD (about 3W against 9W) and you might notice the differences in environmental impact caused by plain usage of the hardware by the software.
Using Technical Understanding for Sustainable Algorithmic Decisions
By understanding in depth all of these technical details, we can reconsider what algorithms we use and how. For example, by just understanding the hardware operational differences described above, we could prefer to cache data in memory at edge over reading it from drives. We have used the cache before, too. To reduce the latency to meet the service level objectives and improve general software performance. The difference is that this time we are doing it for environmental benefits, treating sustainability as a non-functional requirement that moreover can be objectively measured.
3. Measuring impact
Measuring Carbon Emissions in Software Systems: The SCI Methodology
The Green Software Foundation have introduced a methodology to measure carbon emissions from software systems. This specification suggests the following approach to compute the Software Carbon Intensity (SCI).
SCI=(O+M) per R
O – software operational emission from the energy used
M – embodied emissions
R – functional unit of measurement
Since the goal of this article is to understand the energy efficiency of the Scala code, I’m going to omit embodied emissions, although the significance of this parameter is no less important when estimating the full SCI.
The estimation of operational emissions (O) is simple – O = EI, where:
E – energy in kWh, used to run the measured software unit
I – the amount of carbon produced per one kilowatt-hour of electricity (g/kWh). This value depends on how the energy is produced in different regions and generally is available from the electricity vendors. All my estimates assume this param to be equal to 142 g/kWh.

From this, I can conclude that to understand the carbon intensity of different software implementations, I need only to compute how much electricity is consumed.
Using Perf Tool to Measure Energy Consumption in Software Systems
I’m going to do this using the perf tool. perf is a profiler available for Linux OS and which leverages the Performance Counters feature of Linux Kernel. The tool’s available metrics include events from hardware, software, and Performance Monitor Unit (PMU). PMU is one of the subsystems of the modern CPU for which each vendor defines different specifications and offers a different set of metrics.
Let us take a look at the metrics perf offers, by running it for the most basic HelloWorld example from Scala’s getting started guide. To avoid extra overhead, all of the benchmarks will be performed by executing the code from a single jar built by the assembly. In addition, to be able to collect all the metrics, perf must be executed in privileged mode.
sudo perf stat -- java -jar ./out/sustainability/assembly.dest/out-tmp.jar sustainability.Hello > /dev/null
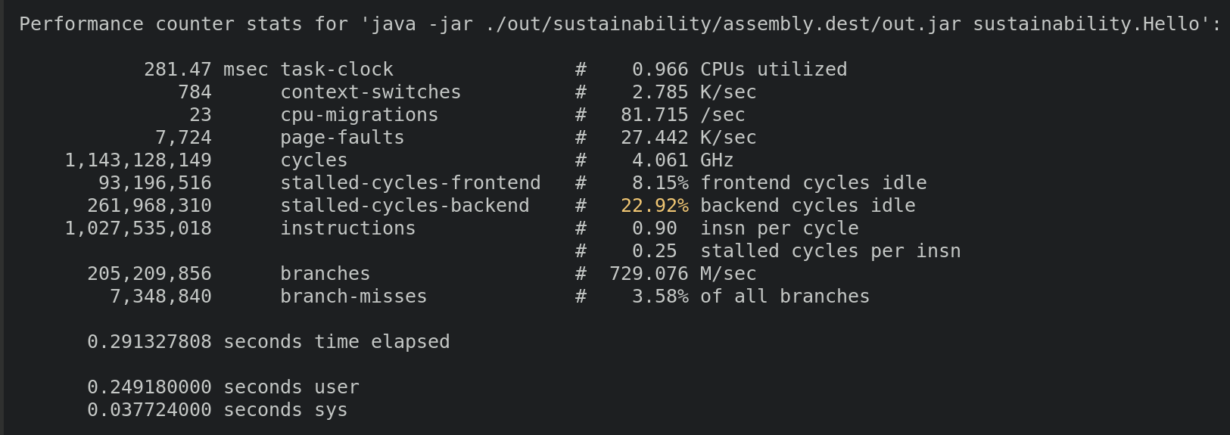
This gives me some interesting metrics on CPU utilization by my code. From these results, I can discover the CPU time it took to run the task, how many times my code was paused by context switching, and how many times instructions were moved to another core in my multicore system.
What is missing in this perspective is the energy used to run the code. To get this, the PMU event must be specified. The full list of all available events can be found by running perf list. On my AMD processor, the target event is called power/energy-pkg/, but as has already been mentioned, the event name can be different for different CPU models.
sudo perf stat -e "power/energy-pkg/" -- java -jar ./out/sustainability/assembly.dest/out.jar sustainability.Hello > /dev/null
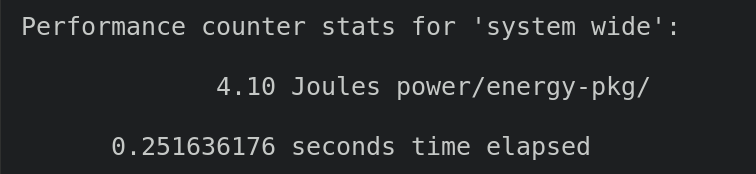
Estimating Carbon Emissions of Java VM Using Energy Consumption
So it took 4.1 Joules of energy to run my simple task in Java VM. This is equivalent to 0.16*10-3 of carbon emissions running this program. Only the CPU consumes this energy, to run the workload, while energy consumption from other hardware is excluded from the equation. Nevertheless, this measure should be enough to estimate the relationship between the software’s algorithmic complexity and its carbon footprint.
4. Sustainable programming: Scala
Now we can turn back to Scala.
From the Sustainable Scala research, I already know how Scala can be compared with other languages when executing the same set of well-known algorithms. The same research highlights footprint differences between idiomatic and non-idiomatic Scala codes. These are great findings, but there is something more that I really want to know. Namely, what are the implications of rallying on a third-party library or framework to solve the day-to-day tasks? Libraries make our life easier by hiding complexity behind easy-to-use abstractions. My goal is to understand the carbon footprint cost of these hidden complexities.
We have already discussed the differences between API designs in our other post and learned that REST, thanks to its simplicity and flexibility, has become a de-facto default choice of client-server applications. Mass adoption of a particular technology amplifies the effects the technology produces. See it this way. A single HTTP request-response to a web server can consume an absolutely insignificant amount of energy to complete. Scale it to hundreds or thousands of requests per second which modern services are expected to process. Then scale it to millions of services globally which perform a multitude of different tasks. This multiplication can make an initially inconspicuous effect more noticeable when applied globally.
This is why the goal of my tests is to benchmark the carbon footprint of the core libraries foundational for the most common REST API implementations: HTTP request handlers and JSON serializers.
The code for all of the test cases below can be found on GitHub.
5. Benchmarking HTTP libraries
For the web server tests, I looked at the most popular Scala HTTP libraries at the moment: Akka Http, ZIO Http, and http4s. Using each of these libraries I implemented a simple static files handler following the library documentation. No other performance optimization was done.
Then I profiled server execution using the perf tool for 2 scenarios:
- During a measurable time period, the service runs idle with no active clients. This gave me a baseline for how much energy is used to initialize JVM and bootstrap the server.
wrkload generation requests the static file of 600k using 4 concurrent threads and 10 connections. This allowed me to measure throughput and roughly estimate how much energy it takes to handle a single HTTP request.
Moreover, each test was repeated several times to get averages.
The results revealed that the tested libraries, doing exactly the same job, consumed quite different amounts of energy and consequently had quite different overall carbon footprints.
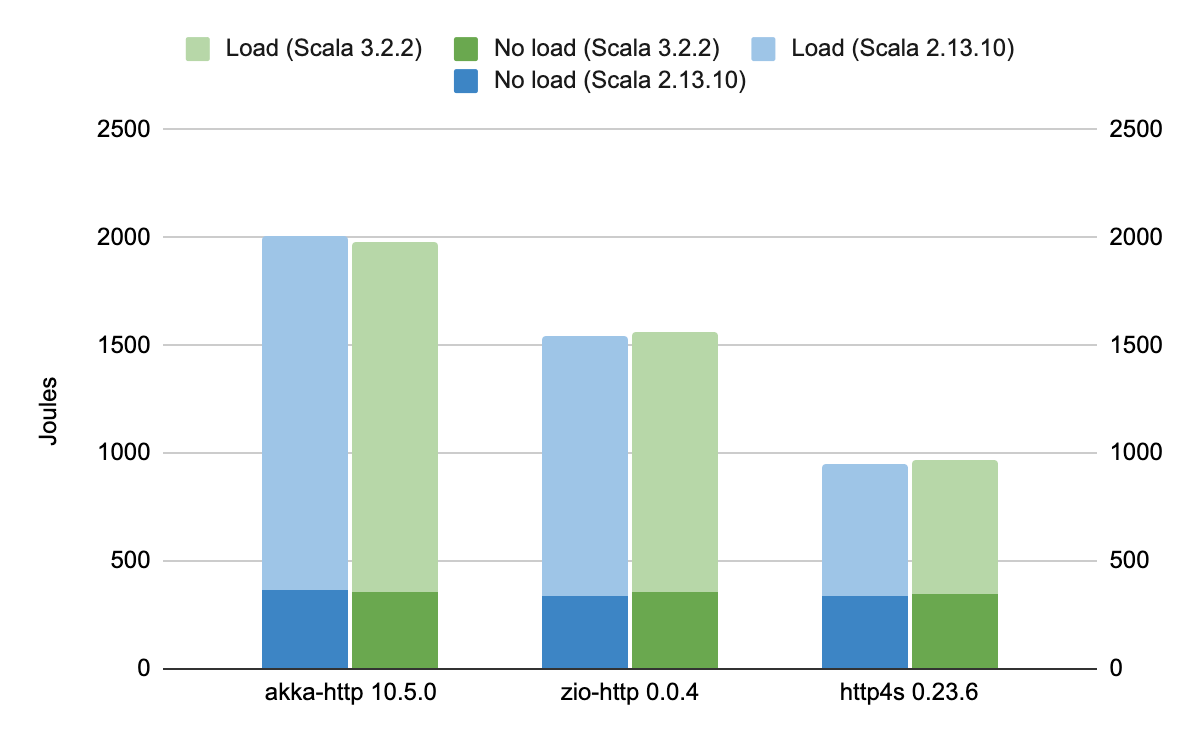
From this chart, you can see that the http4s web server has twice as less energy as the akka-http, with zio-http being somewhere in between. However, this data alone is incomplete without inspection of how much payload each server was able to handle. These benchmarks are not in favor of http4s.
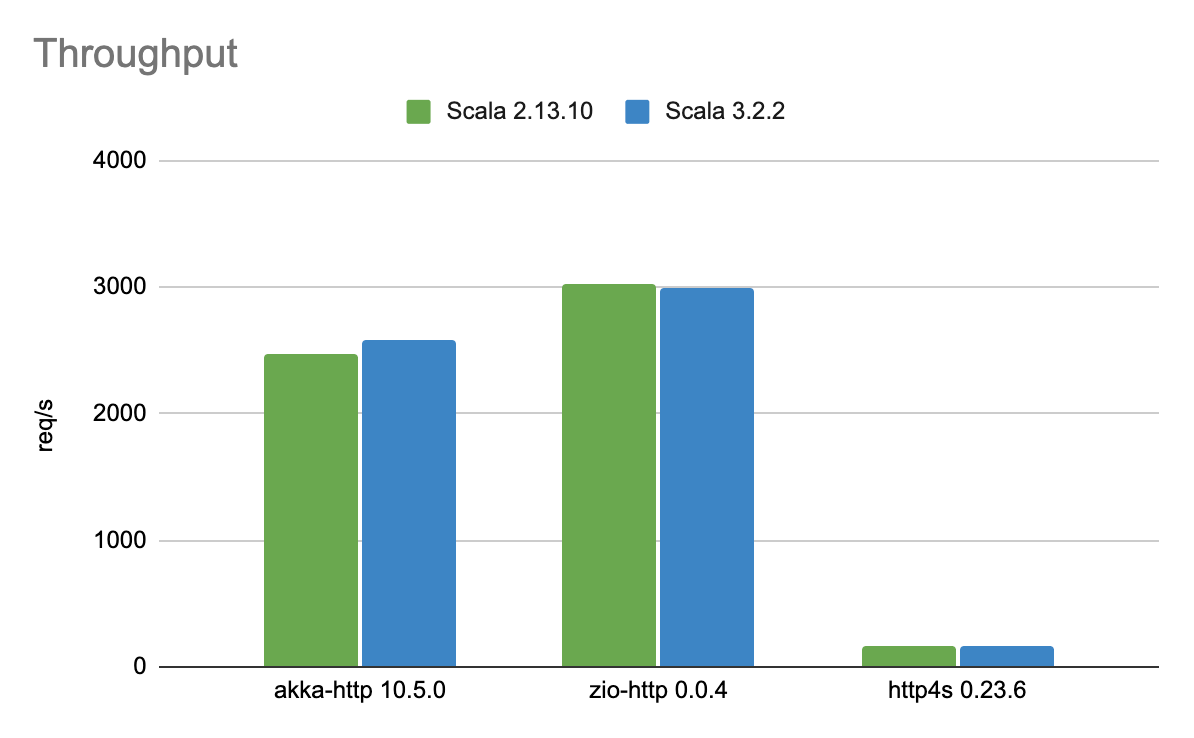
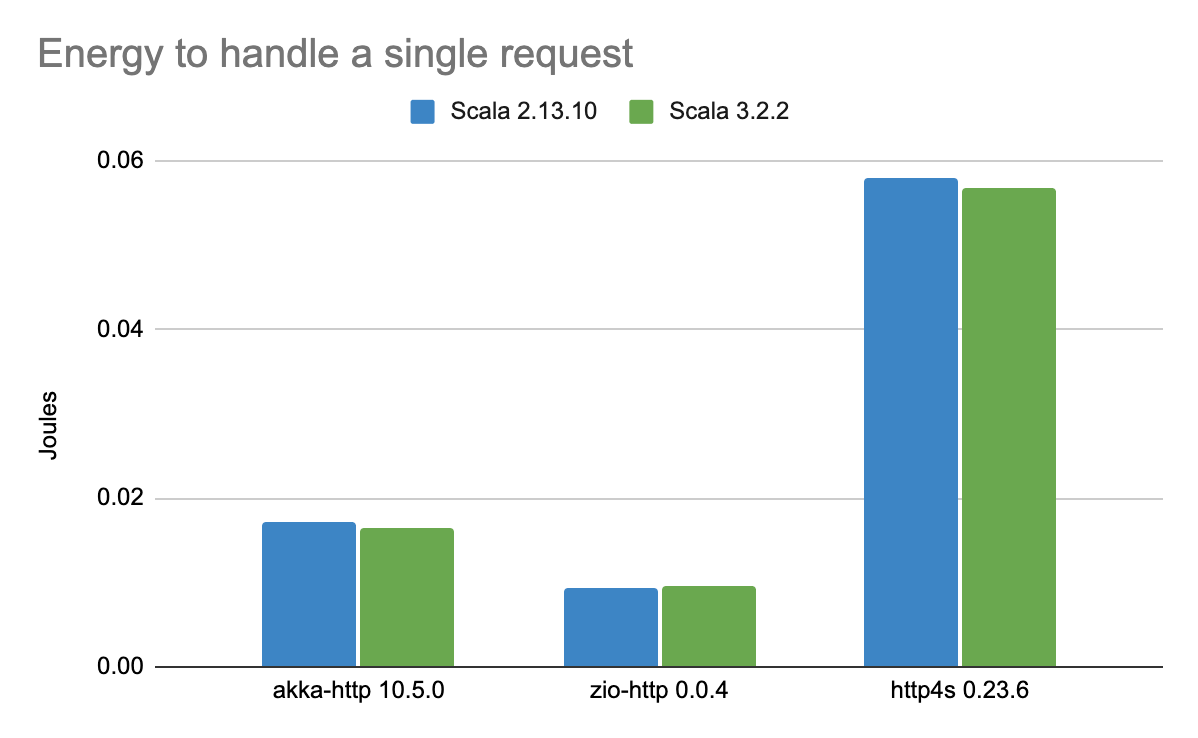
http4s was able to handle only a fraction of the requests the other two competitors were able to process. Besides http4s, emissions per single request are 6 times higher than by zio-http. Generally, zio-http outperformed its rivals by showing much better performance without sacrificing efficiency.
The comparison compiling the same libraries using Scala 2 and Scala 3 showed only marginal changes with no real impact.
6. Benchmarking JSON libraries
For this comparison, I chose the following JSON serialization libraries circe, Json4s, Play JSON, and zio-json. For testing scenarios, each of these libraries had to deserialize a complex JSON imitating a pet store inventory into ADT instances, and then serialize obtained objects into pretty printed JSON. To test the correlation between JSON size and performance, the tests were repeated on 3 datasets of different nested collections sizes, varying from 1,000 records up to 100,000 records.
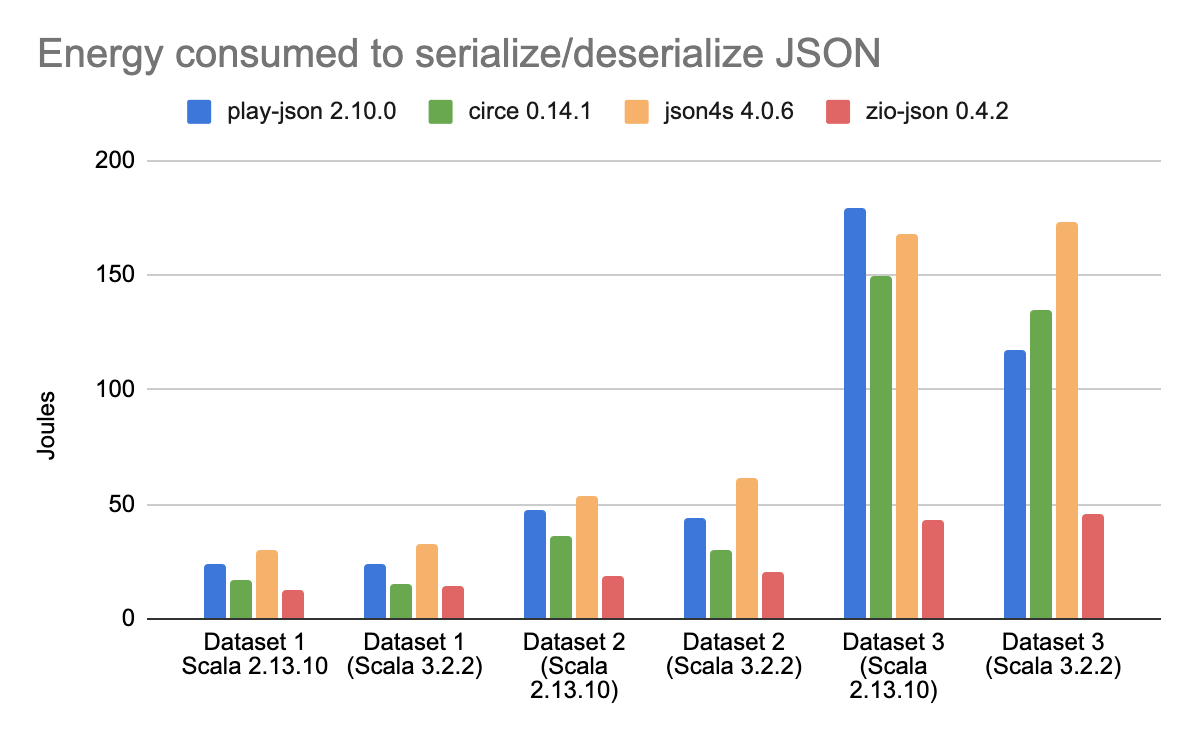
This time, the results I got are even more curious. Mainly because the difference in results for some libraries is more noticeable when compiled using Scala 3 against Scala 2. The most prominent is the change in play-json energy use. Without being particularly prominent at smaller datasets, when compiled for Scala 3, it was able to outperform both circe and json4s. The circe library also showed better efficiency when compiled using newer Scala versions. But the undeniable winner for these tests has become zio-json, showing astonishing results in both performance and energy use.
7. Test conclusions
As had been expected, different libraries can result in very different CO2 footprints, presumably doing the same job. In particular, both ZIO projects zio-http and zio-json showed fantastic results, not only in latency and throughput but also in its energy efficiency.
There are a lot more other benefits of using ZIO for your new projects, which you can learn from our other articles:
- https://scalac.io/blog/zio-sql-type-safe-sql-for-zio-applications/
- https://scalac.io/ebook/introduction-to-programming-with-zio-functional-effects/introduction-3/
- https://scalac.io/ebook/mastering-modularity-in-zio-with-zlayer/intro/
- https://scalac.io/ebook/improve-your-focus-with-zio-optics/introduction-5/
- https://scalac.io/blog/how-to-learn-zio-and-functional-programming/
But don’t get me wrong. The tests I’ve performed have been focusing only on the libraries’ input-output and single non-functional requirement – sustainability. One should not forget that there are a lot more features to be considered in choosing the core library for a new project. Reliability, extensibility, maintainability and testability are some of the other non-functional requirements which must be carefully evaluated to make the wisest choice. Wisdom builds on time and expertise. This is why we recommend hiring Scala experts to make the most intelligent choice for you.
Whether you want to build a new system from scratch or optimize an existing one, Scalac Experts have the expertise to make it happen.
Scalac strives to be the leading consulting company for implementing engineering standards and practices tailored to your business needs.
Partnering with Scalac means working with certified Scala engineers with a proven track record working on large-scale projects and actively contributing to open-source Scala projects. In addition, our team has extensive knowledge of functional programming, microservice architecture, distributed systems, machine learning, etc.
Our engineers stay up-to-date with the newest technologies and use cutting-edge automation tools to ensure high-quality output and shorter delivery times, leaving you free to focus on your core business.
8. Doing more
Here are some other actions which sustainable programming software development professionals can engage in
- Develop the mentality to keep sustainability in mind. This is a goal where every little contribution counts.
- Move your infrastructure to the cloud. The modern virtualization technologies used by cloud vendors allow them to run software on shared hardware and therefore maximize its utilization. In addition, because of the economics of scale, cloud providers have a greater capacity to use more modern and energy-efficient technologies for computing, cooling, and data storage. Besides that, big data centers follow initiatives to use energy generated by low-emission sources for their operations.
- If you are already in the cloud, check your personal infrastructure carbon footprint using one of the provider sustainability tools. There you can find such dashboards as for AWS, Azure and GCP.
- Find domain experts who could help you to optimize your code and infrastructure to meet your sustainability goals.
- Check the Green Software Patterns archive from the Green Software Foundation project to learn more sustainable programming techniques to reduce the carbon footprint.
See more

Authors

I'm a software developer with more than a decade of experience writing software of all sorts. I'm an enthusiastic, meticulous, and unstoppable challenge seeker.
Popular Posts in category

Looking into Scala.js

Your first microservices using Scala and Lagom
Handling Split Brain scenarios with Akka



