

How to implement streaming microservices with ZIO 2 and Kafka
The design and implementation of distributed and highly concurrent applications is something we do every day at Scalac. The adoption of distributed systems is a trend that is currently growing, and it’s not going to stop. Apart from Kubernetes, Apache Kafka is surely the main reason for this.
Here at Scalac, we use Apache Kafka as the main component for asynchronous communication between microservices. Ingestion of large-scale data, resilience to data loss and corruption, replication, and easily achievable parallelism via consumer groups are some of the main reasons why Kafka is one of the most important tools for building distributed systems.
Also, it is no secret that we love Scala, and that we have fully embraced Functional Programming, so this article will assume some familiarity with functional effect systems like ZIO and just a basic understanding of Apache Kafka. Although this article is aimed at developers who are already familiar with ZIO and want to know how to integrate Kafka in ZIO-based projects, we will cover the basics of ZIO, ZIO Streams, and finally, the process of implementing streaming microservices using ZIO Kafka and functional programming techniques. As special guests, some other libraries from the ZIO ecosystem will make their appearance: ZIO Config, ZIO Logging, ZIO JSON and ZIO HTTP!
Let’s get started.
Overview of the libraries we will be using
ZIO
ZIO is a library that allows us to build modern applications that are asynchronous, concurrent, resilient, efficient, easy to understand and to test, using the principles of functional programming. (If you need a more in-depth introduction to ZIO, you can take a look at the “Introduction to Programming with ZIO Functional Effects” article in the Scalac blog).
The ZIO data type
The most important data type in the ZIO library (and also the basic building block of any application based on this library), is also called ZIO, and is designed around three type parameters:
ZIO[-R, +E, +A]A nice mental model of the ZIO data type is the following:
ZEnvironment[R] => Either[E, A]This means a ZIO effect needs an environment of type ZEnvironment[R] to run (ZEnvironment[R] represents a dependency on a service or several services that are needed for running the effect), and can fail with an error of type E or succeed with a value of type A.
The ZLayer data type
It’s also important to remember that we have the ZLayer data type at our disposal, which allows us to have pure, highly compositional values which can be combined automatically to build the whole dependency graph of our application and provide the ZEnvironment[R] that a ZIO application needs. (If you need to know more about ZLayer, you can read the “Mastering Modularity in ZIO with ZLayer” ebook available in the Scalac blog).
ZIO Streams
Functional streams, as an abstraction, are commonly used to elegantly solve problems in the area of concurrency and processing of unbounded data, making resource safety and CPU utilization the priority.
The ZIO Streams library is an implementation of functional streams, and it contains three fundamental data types:
ZStream[-R, +E, +A]: Acts as a producer of values of typeA, possibly failing with an error of typeEand requiring an environment of typeZEnvironment[R]. The difference betweenZIOandZStreamis that:ZIOcan succeed with a single value of typeAZStreamcan succeed with zero or more values (potentially infinite) of typeA
ZPipeline[-Env, +Err, -In, +Out]: Acts as a transformer of values of typeIn, into values of typeOut, possibly failing with an error of typeEand requiring an environment of typeZEnvironment[R]. A nice mental model for this type is:
ZPipeline[Env, Err, In, Out] = ZStream[Env, Err, In] => ZStream[Env, Err, Out]ZSink[-R, +E, -In, +L, +Z]: Acts as a consumer of values of type In, producing an output of typeZand leftovers of typeL, possibly failing with an error of typeEand requiring an environment of typeZEnvironment[R].
If you need more information on ZIO Streams, you can take a look at the official documentation.
ZIO Kafka
ZIO Kafka is a Kafka client for ZIO. It provides a purely functional, streams-based interface to the Kafka client and integrates effortlessly with ZIO and ZIO Streams to provide an elegant interface for consuming, processing and committing Kafka records.
Applications that are based on event-driven architecture probably are using Apache Kafka as a data backbone, which is the unifying point in the system where all of the events are stored. Since Kafka topics are meant to consistently increase over time with new events, applications that follow event-driven principles are constructed as infinite loops, which consume events and then process them in some way.
Using a plain Kafka client is a valid option of course, but in a lot of situations it can be really hard to implement some common streaming workflows such as buffering, aggregating batches of records up to a specified timeout, or control of emitted messages per time unit. These are not trivial tasks and will distract a developer, and delay the implementation of any business requirements. It is imperative that a code base can support all of these afore-mentioned patterns, but this is hard to implement, hard to test and hard to extend. Now imagine that you would like to implement all of this, but in a completely asynchronous and non-blocking manner: It sounds extremely hard, because it is. Fortunately, all of these patterns are available in ZIO Streams, and that is probably the main reason why you should avoid using the plain Kafka client.
ZIO Kafka offers these fundamental data types:
Consumer: Consumes values from a Kafka topic.Producer: Produces values to a Kafka topic.Serializer[-R, -T]: Serializes values of typeTwhen producing to a Kafka topic, requiring an environment of typeZEnvironment[R].Deserializer[-R, +T]: Deserializes values of typeTwhen consuming from a Kafka topic, requiring an environment of typeZEnvironment[R].Serde[-R, T]: Combines the functionality ofSerializerandDeserializer.
If you need more information on ZIO Kafka, you can take a look at the official documentation.

ZIO HTTP
ZIO HTTP is a powerful library that is used to build highly performant HTTP-based services and clients using functional programming and ZIO, using Netty as its core.
In this article, we are going to use the ZClient data type from ZIO HTTP:
ZClient[-Env, -In, +Err, +Out]ZClient models an HTTP client which:
- Requires an environment of type
Env - Requires input of type
In - Might fail with an error of type
Err - Might succeed with a value of type
Out
There’s also the Client alias:
type Client = ZClient[Any, Body, Throwable, Response]So, a Client is a ZClient which:
- Does not require any environment
- Requires input of type
Body - Might fail with an error of type
Throwable - Might succeed with a value of type
Response
If you want to know more about ZIO HTTP, you can take a look at the official documentation.
ZIO JSON
ZIO JSON is a fast and secure JSON library with tight ZIO integration. Important data types in this library are:
JsonEncoder[A]: Encodes a value of typeAas JSONJsonDecoder[A]: Decodes JSON as a value of typeAJsonCodec[A]: Combines the functionality ofJsonEncoderandJsonDecoder
If you want to go deeper into ZIO JSON, you can take a look at the official documentation.
ZIO configuration facade and the ZIO Config library
A great improvement in ZIO 2 is that it now includes built-in support for configuration via a facade for configuration providers. This enables a unified, yet customizable and flexible way to configure our applications, delegating the complex logic to a ConfigProvider, which may be supplied by ecosystem libraries such as ZIO Config.
So, here are the important elements that the ZIO library provides to work with configuration:
- Configuration description: Given by a
Config[A], which describes configuration data of typeA. - Configuration backend: Given by a
ConfigProvider, which is the underlying engine that ZIO uses to load configs. By the way, the ZIO library itself ships with a simple defaultConfigProvider, which reads configuration data from environment variables and, if not found, from system properties. This can be used for development purposes or to bootstrap applications towards more sophisticatedConfigProviders. - Configuration facade: By using the
ZIO.configmethod we can load configuration data described by aConfig[A]instance, using the currentConfigProvider.
If you need more information on how ZIO handles configuration, you can take a look at the official documentation here. And, to know more about the ZIO Config library, you can take a look here.
ZIO logging facade and ZIO Logging
Another great improvement in ZIO 2 is that, similarly to what we have shown in the previous section regarding configuration, it now includes built-in support for logging via a facade that standardizes the interface to logging functionality, delegating the complex logic to logging backends such as ZIO Logging.
By the way, ZIO includes a default logger that prints any log messages that are equal or above the Info level. If you need more production-level loggers, you can use ZIO Logging, which provides:
- Console loggers.
- File loggers.
- SLF4J integration, through the
zio-logging-slf4jmodule. This gives you access to several logging backends which are supported by SLF4J, such asjava.util.logging, logback and log4j. - Java Platform/System Logger integration, through the
zio-logging-jplmodule.
We’ll see how to use the ZIO logging facade in later sections, but if you need more information you can find it in the official documentation here. And also, here is more information for the ZIO Logging library.
Implementing a sample system using ZIO Kafka
Now, after we’ve explained the basics, it is time to go through an implementation of a sample system.
Our system will consist of 2 services:
- Producer service, which will be responsible for producing some raw events to Kafka
- Processor service, which will be responsible for:
- Consuming raw events produced by the producer service.
- Enriching raw events by contacting some external API (
restcountries.comspecifically). - Producing enriched records to Kafka again.
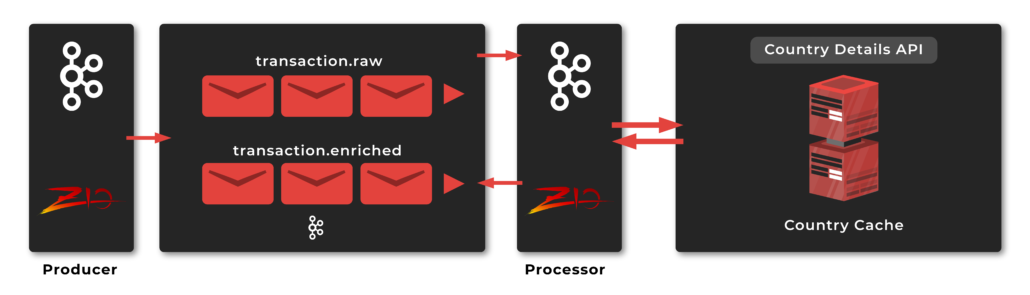
The project is implemented as a multi-module Bleep project. By the way, Bleep is a new build tool which:
- Aims to be fast and simple.
- Has a great CLI experience.
- Offers automatic import from sbt.
- Enables easy import into your IDE, such as IntelliJ IDEA.
Here you can see the bleep.yaml file for our project, where we configure all our modules and dependencies:
$schema: https://raw.githubusercontent.com/oyvindberg/bleep/master/schema.json
$version: 0.0.2
jvm:
name: graalvm-java19:22.3.1
projects:
kafka:
dependencies:
- com.lmax:disruptor:3.4.4
- io.github.embeddedkafka::embedded-kafka:3.4.0
- org.apache.logging.log4j:log4j-core:2.20.0
- org.apache.logging.log4j:log4j-slf4j-impl:2.20.0
extends: template-common
folder: ./modules/kafka
platform:
mainClass: embedded.kafka.EmbeddedKafkaBroker
processor:
dependencies:
- com.lmax:disruptor:3.4.4
- dev.zio::zio-http:3.0.0-RC2
- org.apache.logging.log4j:log4j-core:2.20.0
- org.apache.logging.log4j:log4j-slf4j-impl:2.20.0
dependsOn: protocol
extends: template-common
folder: ./modules/processor
scala:
options: -Ymacro-annotations
platform:
mainClass: io.scalac.ms.processor.ProcessorApp
producer:
dependencies:
- com.lmax:disruptor:3.4.4
- org.apache.logging.log4j:log4j-core:2.20.0
- org.apache.logging.log4j:log4j-slf4j-impl:2.20.0
dependsOn: protocol
extends: template-common
folder: ./modules/producer
platform:
mainClass: io.scalac.ms.producer.ProducerApp
protocol:
dependencies:
- dev.zio::zio-config-magnolia:4.0.0-RC16
- dev.zio::zio-config-typesafe:4.0.0-RC16
- dev.zio::zio-json:0.5.0
- dev.zio::zio-kafka:2.3.2
- dev.zio::zio-logging-slf4j:2.1.13
- dev.zio::zio-logging:2.1.13
- dev.zio::zio-macros:2.0.15
- dev.zio::zio-streams:2.0.15
- dev.zio::zio:2.0.15
extends: template-common
folder: ./modules/protocol
scripts:
dependencies: build.bleep::bleep-core:${BLEEP_VERSION}
platform:
name: jvm
scala:
version: 2.13.11
templates:
template-common:
platform:
name: jvm
sbt-scope: main
scala:
compilerPlugins: com.hmemcpy::zio-clippy:0.0.1
version: 2.13.11So, we have:
- A
kafkamodule, which is used just to bootstrap an embedded Kafka instance, for development purposes. - A
protocolmodule, where we define models (case classes) for events in our system. We are going to use the JSON format for our Kafka messages, so in the protocol module, JSON codecs are also implemented using the ZIO JSON library. - A
producermodule, which will just implement the producer service we have described above. - A
processormodule, which will just implement the processor service we have described above.
Also, notice we are using the zio-clippy compiler plugin recently published by Igal Tabachnik, which enables nicer error messages for ZIO.
Exploring the kafka module
The kafka module contains an EmbeddedKafkaBroker object:
import io.github.embeddedkafka._
import org.slf4j.LoggerFactory
object EmbeddedKafkaBroker extends App with EmbeddedKafka {
val log = LoggerFactory.getLogger(this.getClass)
val port = 9092
implicit val config: EmbeddedKafkaConfig =
EmbeddedKafkaConfig(kafkaPort = port, zooKeeperPort = 5555)
val embeddedKafkaServer: EmbeddedK = EmbeddedKafka.start()
createCustomTopic(topic = "transactions.raw", partitions = 3)
createCustomTopic(topic = "transactions.enriched", partitions = 3)
log.info(s"Kafka running: localhost:$port")
embeddedKafkaServer.broker.awaitShutdown()
}You can see EmbeddedKafkaBroker basically:
- Starts an embedded Kafka instance listening on port 9092
- Creates two topics:
transactions.rawandtransactions.enriched
Exploring the protocol module
The protocol module defines some case classes that will be used for communication between the producer and consumer modules, through the embedded Kafka instance. The first one is TransactionRaw, which is used to model events that will be published by the producer module:
package io.scalac.ms.protocol
import zio.json._
import zio.kafka.serde._
final case class TransactionRaw(userId: Long, country: String, amount: BigDecimal)
object TransactionRaw {
implicit val codec: JsonCodec[TransactionRaw] = DeriveJsonCodec.gen[TransactionRaw]
lazy val serde: Serde[Any, TransactionRaw] = deriveSerde[TransactionRaw]
}Notice that, because TransactionRaw events will be published to Kafka as JSON, we need to define a Serde that will take care of the encoding/decoding. This line is the one which takes care of that:
lazy val serde: Serde[Any, TransactionRaw] = deriveSerde[TransactionRaw]The deriveSerde method is defined in the io.scalac.ms.protocol package object:
package io.scalac.ms
import zio._
import zio.json._
import zio.kafka.serde._
package object protocol {
def deriveSerde[A: JsonCodec]: Serde[Any, A] =
Serde.string
.inmapM(string => ZIO.fromEither(string.fromJson[A]).mapError(new IllegalArgumentException(_)))(
a => ZIO.succeed(a.toJson)
)
}Let’s analyze what deriveSerde does:
- It requires an implicit
JsonCodecfor the typeAfor which we want to build aSerde. So, in the case ofTransactionRaw, this line in the companion object is the one that provides that implicit value (you can see it’s a piece of cake to automatically deriveJsonCodecinstances for your data types with ZIO JSON):
implicit val codec: JsonCodec[TransactionRaw] =
DeriveJsonCodec.gen[TransactionRaw]- It calls
Serde.stringto obtain the defaultSerdethat ZIO Kafka offers to serialize/deserialize events as strings. By the way, the type of this isSerde[Any, String]. - Then, it transforms that
Serde[Any, String]into aSerde[Any, A], by calling theSerde#inmapMmethod, which allows to effectfully transform the success type of aSerdeinto another type (there’s alsoSerde#inmapwhich allows to do pure, non-effectful transformations).Serde#inmapMwill require two functions:String => ZIO[Any, Throwable, A]: In our specific case, this function takes the inputstring, and decodes it by callingstring.fromJson[A](fromJsonis an extension method you can use when there’s an implicitJsonCodecin scope). If the inputstringis not a valid JSON, the function will return aZIOeffect that fails withIllegalArgumentException.A => ZIO[Any, Throwable, String]: In this case, this function takes anAand returns a JSON string, by callinga.toJson(toJsonis also an extension method you can use when there’s an implicitJsonCodecin scope).
Next, we have TransactionEnriched, which contains the same fields as TransactionRaw, but it is enriched with Country details as you can see. The processor service will be responsible for fetching these additional details from restcountries.com, and produce the enriched transactions to a new Kafka topic (you can see we are also deriving a JsonCodec and a Serde for TransactionEnriched):
package io.scalac.ms.protocol
import zio.json._
import zio.kafka.serde._
final case class TransactionEnriched(userId: Long, country: Country, amount: BigDecimal)
object TransactionEnriched {
implicit val codec: JsonCodec[TransactionEnriched] = DeriveJsonCodec.gen[TransactionEnriched]
lazy val serde: Serde[Any, TransactionEnriched] = deriveSerde[TransactionEnriched]
}By the way, here is the model for Country:
package io.scalac.ms.protocol
import zio.json._
final case class Country(name: String, capital: String, region: String, subregion: String, population: Long)
object Country {
implicit val codec: JsonCodec[Country] = DeriveJsonCodec.gen[Country]
}Exploring the producer module
The producer module contains some classes. The first one is AppConfig which will represent the configuration for the producer application:
package io.scalac.ms.producer
import zio.config.magnolia._
final case class AppConfig(bootstrapServers: List[String], topic: String)
object AppConfig {
lazy val config = deriveConfig[AppConfig]
}Something interesting to notice in the companion object is that we are automatically deriving a ZIO configuration descriptor with type Config[AppConfig], by calling the deriveConfig[AppConfig] macro provided by the zio-config-magnolia module. We will need this very soon.
Also, we have an EventGenerator object that just contains a list of transactions the producer application will publish to Kafka:
package io.scalac.ms.producer
import io.scalac.ms.protocol.TransactionRaw
object EventGenerator {
lazy val transactions = List(
TransactionRaw(1, "Serbia", BigDecimal(12.99)),
TransactionRaw(1, "Serbia", BigDecimal(23.99)),
TransactionRaw(1, "Serbia", BigDecimal(11.99)),
…
)
}Finally, there’s a ProducerApp which is its entry point of the producer application:
import io.scalac.ms.protocol.TransactionRaw
import zio._
import zio.config.typesafe._
import zio.kafka.producer._
import zio.kafka.serde._
import zio.logging.backend._
import zio.stream._
object ProducerApp extends ZIOAppDefault {
override val bootstrap =
Runtime.setConfigProvider(ConfigProvider.fromResourcePath()) >>>
Runtime.removeDefaultLoggers >>>
SLF4J.slf4j
override val run =
(for {
topic <- ZIO.config(AppConfig.config.map(_.topic))
_ <- ZStream
.fromIterable(EventGenerator.transactions)
.mapZIO { transaction =>
(ZIO.logInfo("Producing transaction to Kafka...") *>
Producer.produce(
topic = topic,
key = transaction.userId,
value = transaction,
keySerializer = Serde.long,
valueSerializer = TransactionRaw.serde
)) @@ ZIOAspect.annotated("userId", transaction.userId.toString)
}
.runDrain
} yield ()).provide(
producerSettings,
Producer.live
)
private lazy val producerSettings =
ZLayer {
ZIO.config(AppConfig.config.map(_.bootstrapServers)).map(ProducerSettings(_))
}
}The core logic is defined in run, and you can see several interesting things happen:
- First, some configuration is obtained by calling
ZIO.config(AppConfig.config.map(_.topic)). The idea of theZIO.configmethod is that it receives a configuration descriptor that tells ZIO what configuration to obtain. So, if we calledZIO.config(AppConfig.config)we would be instructing ZIO to obtain the wholeAppConfigfor the application. However, for this case we don’t actually need the wholeAppConfig(we just need to obtain atopicvalue), so what’s great about configuration descriptors is that they have aConfig#mapmethod which allows us to transform the value they provide. That’s why we can doAppConfig.config.map(_.topic)and provide that toZIO.configin order to obtain just thetopicvalue. (As a side note, maybe you’re thinking now where does ZIO obtain the configuration from, don’t worry because we are going to see how that works very soon). - Next, we are creating and executing a
ZStream, which will produce someTransactionRawsby calling theProducer.producemethod from ZIO Kafka, which receives as parameters:- The topic to which we want to produce.
- The key, value pair we want to produce.
- The serializers for the key and the value: Because the key is a
Long, we provide aSerde.long, and because the value is aTransactionRaw, we provide aTransactionRaw.serde(the customSerdewe have defined above).
Notice also how we are using the logging facade from ZIO to generate some logs, by calling ZIO.logInfo. Also, we are annotating all logs (including the ones produced by Producer.produce under the hood) with the userId of the corresponding transaction by using ZIOAspect.annotated.
- Finally, we call
ZIO#provideto supply the environment our application needs throughZLayers. In this case, the application needs a ZIO KafkaProducer, so we pass aProducer.liveas an argument, which in turn needs aProducerSettingsinstance, that’s why we have aproducerSettingsvariable which returns aZLayerthat just getsbootstrapServersfrom the configuration and uses that to create aProducerSettings.
The other interesting part of the ProducerApp is that we are overriding a bootstrap value (provided by the ZIOAppDefault trait). This is a special ZLayer which can be used to customize the Runtime of a ZIO application. For our use case, we want to apply these customizations:
- Set a custom
ConfigProvider, instead of the defaultConfigProviderincluded in ZIO. For that, we can call Runtime.setConfigProviderwithConfigProvider.fromResourcePath(), which is aConfigProviderfrom thezio-config-typesafelibrary that looks for anapplication.confHOCON file in theresourcesdirectory. - Set a custom logger backend, instead of the default one included in ZIO. For that, we can call
SLF4J.slf4j(from thezio-logging-slf4jlibrary) which, as the name suggests, sets SLF4J as our logging backend. SLF4J in turn can use Log4J or Logstash as its backends. In this case we are using Log4J, and that’s why we have alog4j2.xmlfile in the resources directory, to configure the logging level and format.
Notice that, because Runtime.setConfigProvider and SLF4J.slf4j return ZLayers, we can combine them, using operators such as >>>.
Exploring the processor module
The processor module contains several classes as well. The first one is AppConfig which will represent the configuration for the processor application:
package io.scalac.ms.processor.config
import zio.config.magnolia._
final case class AppConfig(
consumer: AppConfig.Consumer,
producer: AppConfig.Producer,
enrichment: AppConfig.Enrichment
)
object AppConfig {
lazy val config = deriveConfig[AppConfig]
final case class Consumer(bootstrapServers: List[String], topic: String, groupId: String)
final case class Producer(bootstrapServers: List[String], topic: String)
final case class Enrichment(host: String)
}Notice that, as was the case with the producer module, we are deriving a config descriptor by calling deriveConfig[AppConfig].
Next, we have a CountryCache service, which takes care of caching information about countries in memory:
@accessible
trait CountryCache {
def get(countryName: String): UIO[Option[Country]]
def put(country: Country): UIO[Unit]
}By the way, you can see we are using the @accessible annotation from the zio-macros library, which just generates accessor methods. If you want to understand more about accessors (and also ZLayers), you can take a look at the “Mastering Modularity in ZIO with ZLayer” ebook in the Scalac blog.
Let’s see now the live implementation of the CountryCache service:
final case class CountryCacheLive(ref: Ref[Map[String, Country]]) extends CountryCache { self =>
override def get(countryName: String): UIO[Option[Country]] =
(for {
_ <- ZIO.logInfo(s"Getting country details from cache.")
cache <- self.ref.get
result <- ZIO.succeed(cache.get(countryName))
} yield result) @@ ZIOAspect.annotated("countryName", countryName)
override def put(country: Country): UIO[Unit] =
(ZIO.logInfo("Caching country.") *>
self.ref.update(_ + (country.name -> country))) @@ ZIOAspect.annotated("countryName", country.name)
}
object CountryCacheLive {
lazy val layer: ULayer[CountryCache] =
ZLayer {
Ref.make(Map.empty[String, Country]).map(CountryCacheLive(_))
}
}You can see CountryCacheLive is pretty straightforward, it just contains a Ref[Map[String, Country]] to store information about countries in memory, and it’s using some nice logging features from ZIO we have already explained.
Next, we have an Enrichment service, which takes care of enriching raw transactions:
@accessible
trait Enrichment {
def enrich(transactionRaw: TransactionRaw): IO[EnrichmentError, TransactionEnriched]
}Here is the model for EnrichmentError:
package io.scalac.ms.processor.error
import zio.http._
sealed trait EnrichmentError { self =>
import EnrichmentError._
override def toString: String =
self match {
case CountryApiUnreachable(error) => s"Country API unreachable: ${error.getMessage}"
case UnexpectedResponse(status, body) => s"Response error. Status: $status, body: $body"
case ResponseExtraction(error) => s"Response extraction error: ${error.getMessage}"
case ResponseParsing(message) => s"Response parsing error: $message"
}
}
object EnrichmentError {
final case class CountryApiUnreachable(error: Throwable) extends EnrichmentError
final case class UnexpectedResponse(status: Status, body: String) extends EnrichmentError
final case class ResponseExtraction(error: Throwable) extends EnrichmentError
final case class ResponseParsing(message: String) extends EnrichmentError
}And here is the live implementation of the Enrichment service:
final case class EnrichmentLive(countryCache: CountryCache, httpClient: Client) extends Enrichment { self =>
override def enrich(
transactionRaw: TransactionRaw
): IO[EnrichmentError, TransactionEnriched] = {
val TransactionRaw(userId, countryName, amount) = transactionRaw
for {
_ <- ZIO.logInfo("Enriching raw transaction.")
country <- self.countryCache.get(countryName).someOrElseZIO(self.fetchAndCacheCountryDetails(countryName))
} yield TransactionEnriched(userId, country, amount)
}
private def fetchAndCacheCountryDetails(
countryName: String
): IO[EnrichmentError, Country] =
for {
_ <- ZIO.logInfo(s"Cache miss. Fetching country details from external API.")
country <- self.fetchCountryDetails(countryName)
_ <- self.countryCache.put(country)
} yield country
private def fetchCountryDetails(
countryName: String
): IO[EnrichmentError, Country] =
for {
host <- ZIO.config(AppConfig.config.map(_.enrichment.host)).orDie
response <- (self.httpClient @@ ZClientAspect.requestLogging())
.scheme(Scheme.HTTPS)
.host(host)
.path("/v2/name")
.get(countryName)
.mapError(EnrichmentError.CountryApiUnreachable)
responseBody <- response.body.asString.mapError(EnrichmentError.ResponseExtraction)
_ <- ZIO
.fail(EnrichmentError.UnexpectedResponse(response.status, responseBody))
.when(response.status != Status.Ok)
country <- ZIO
.fromEither(responseBody.fromJson[NonEmptyChunk[Country]])
.mapBoth(EnrichmentError.ResponseParsing, _.head)
} yield country
}
object EnrichmentLive {
lazy val layer: URLayer[CountryCache with Client, Enrichment] = ZLayer.fromFunction(EnrichmentLive(_, _))
}You can see EnrichmentLive depends on a CountryCache and a Client from ZIO HTTP.
The logic of EnrichmentLive#enrich is very simple:
- Receives a
TransactionRaw, and gets thecountryNameinside it. - Looks for the corresponding
Countryinformation in the cache.- If it’s found, a
TransactionEnrichedis directly returned. - If it’s not found, the
Countryinformation has to be fetched fromrestcountries.comand put into the cache (by calling theEnrichmentLive#fetchAndCacheCountryDetailsmethod). After that, aTransactionEnrichedcan be returned.
- If it’s found, a
EnrichmentLive#fetchAndCacheCountryDetails calls another helper method under the hood, namely EnrichmentLive#fetchCountryDetails, whose implementation is also interesting:
- First, the host of the external API (
restcountries.com) is obtained from the configuration. - Then, we use
httpClientto call that external API. You can see thishttpClienthas methods to configure the URL we want to call, such asClient#scheme,Client#host,Client#path. All of those methods return a newClientinstance, and once we have the URL we want, we can call methods such asClient#get,which receives a parameter that will be added to the path (in this casecountryName), and returns a ZIO effect that describes the actual call to the external API. Another interesting thing to notice here is that you can also use aspects with ZIO HTTP clients, such asZClientAspect.requestLoggingto enable logging for requests and responses. - The next lines just check that the response status is 200 OK and extract the response body as JSON.
Finally, we have the ProcessorApp itself, which contains a run method that will consume events from Kafka indefinitely:
package io.scalac.ms.processor
import io.scalac.ms.processor.config.AppConfig
import io.scalac.ms.processor.service._
import io.scalac.ms.protocol.{ TransactionEnriched, TransactionRaw }
import zio._
import zio.config.typesafe._
import zio.http._
import zio.kafka.consumer._
import zio.kafka.consumer.diagnostics.Diagnostics
import zio.kafka.producer._
import zio.kafka.serde._
import zio.logging.backend._
object ProcessorApp extends ZIOAppDefault {
override val bootstrap =
Runtime.setConfigProvider(ConfigProvider.fromResourcePath()) >>> Runtime.removeDefaultLoggers >>> SLF4J.slf4j
override val run =
(for {
_ <- ZIO.logInfo("Starting processing pipeline")
appConfig <- ZIO.config(AppConfig.config)
_ <- Consumer
.plainStream(
subscription = Subscription.topics(appConfig.consumer.topic),
keyDeserializer = Serde.long,
valueDeserializer = TransactionRaw.serde
)
.mapZIO { committableRecord =>
val offset = committableRecord.offset
(for {
transaction <- Enrichment.enrich(committableRecord.value)
_ <- ZIO.logInfo("Producing enriched transaction to Kafka...")
_ <- Producer.produce(
topic = appConfig.producer.topic,
key = transaction.userId,
value = transaction,
keySerializer = Serde.long,
valueSerializer = TransactionEnriched.serde
)
} yield offset).catchAll { error =>
ZIO.logError(s"Got error while processing: $error") *> ZIO.succeed(offset)
} @@ ZIOAspect.annotated("userId", committableRecord.value.userId.toString)
}
.aggregateAsync(Consumer.offsetBatches)
.mapZIO(_.commit)
.runDrain
.catchAll(error => ZIO.logError(s"Got error while consuming: $error"))
} yield ()).provide(
EnrichmentLive.layer,
CountryCacheLive.layer,
Client.default,
consumerSettings,
ZLayer.succeed(Diagnostics.NoOp),
Consumer.live,
producerSettings,
Producer.live
)
private lazy val producerSettings =
ZLayer {
ZIO.config(AppConfig.config.map(_.producer.bootstrapServers)).map(ProducerSettings(_))
}
private lazy val consumerSettings =
ZLayer {
ZIO.config(AppConfig.config.map(_.consumer)).map { consumer =>
ConsumerSettings(consumer.bootstrapServers)
.withGroupId(consumer.groupId)
.withClientId("client")
.withCloseTimeout(30.seconds)
.withPollTimeout(10.millis)
.withProperty("enable.auto.commit", "false")
.withProperty("auto.offset.reset", "earliest")
}
}
}
As you can see, the whole logic is encapsulated in the run method:
- First, the application configuration is obtained by calling
ZIO.config(AppConfig.config). - Then, a ZIO Kafka
Consumeris subscribed to a specified topic, by creating aZStreamthrough theConsumer.plainStreammethod, which receives as parameters:- The topic.
- The key deserializer: In this case, keys will be
Longvalues so we needSerde.long. - The value deserializer: In this case, values will be
TransactionRawvalues so we needTransactionRaw.serde(which we have defined above).
- Now, we have a ZStream-based abstraction over a Kafka Topic, where we can process elements one by one:
Enrichment.enrichgets called in order to make aTransactionEnrichedevent.- Next, we produce the enriched transaction back to Kafka by calling the
Producer.producemethod from ZIO Kafka, which receives as parameters:- The topic to which we want to produce.
- The key, value pair we want to produce.
- The serializers for the key and the value: Because the key is a
Long, we provide aSerde.long, and because the value is aTransactionEnriched, we provide aTransactionEnriched.serde(the customSerdewe have defined above).
- After that, we aggregate the individual offsets of the Kafka records to a batch of offsets that can be committed at once, by calling
ZStream#aggregateAsync(Consumer.offsetBatches). If you need more information on howZStream#aggregateAsyncworks, you can take a look at the ZIO documentation.
- Finally, we call
ZIO#provideto supply the environment our application needs throughZLayers. In this case, the application needs:- A ZIO Kafka
Producer, so we pass aProducer.liveas an argument, which in turn needs aProducerSettingsinstance, that’s why we have aproducerSettingsvariable which returns aZLayerthat just getsbootstrapServersfrom the producer configuration and uses that to create aProducerSettings. - A ZIO Kafka
Consumer, so we pass aConsumer.liveas an argument, which in turn needs:- A
ConsumerSettingsinstance, that’s why we have aconsumerSettingsvariable which returns aZLayerthat just getsbootstrapServersfrom the consumer configuration and uses that to create aConsumerSettings. - A
Diagnosticsinstance, that’s why we are passingZLayer.succeed(Diagnostics.NoOp)as one of the parameters to theprovidemethod.
- A
- An
Enrichmentinstance, so we pass anEnrichmentLive.layer, which in turn needs aCountryCache(provided byCountryCacheLive.layer) and a ZIO HTTP Client, provided byClient.default.
- A ZIO Kafka
As a final note, you can realize that, similarly to what we did for the producer module:
- We are providing a custom
ConfigProviderthat loads configuration from anapplication.conffile in theresourcesdirectory. - We are providing a custom SLF4J logging backend.
Running our sample system
To run our sample system, we just need to execute:
bleep run kafka:To start our embedded Kafka.bleep run producer: To produce some raw transactions to Kafka. We will see some nice logs like these:
15:31:56.338 [ZScheduler-Worker-1] [{userId=1}] INFO io.scalac.ms.producer.ProducerApp Producing transaction to Kafka...
15:31:56.366 [ZScheduler-Worker-7] [{userId=1}] INFO io.scalac.ms.producer.ProducerApp Producing transaction to Kafka...
15:31:56.392 [ZScheduler-Worker-6] [{userId=2}] INFO io.scalac.ms.producer.ProducerApp Producing transaction to Kafka...
15:31:56.419 [ZScheduler-Worker-9] [{userId=2}] INFO io.scalac.ms.producer.ProducerApp Producing transaction to Kafka...
15:31:56.444 [ZScheduler-Worker-11] [{userId=3}] INFO io.scalac.ms.producer.ProducerApp Producing transaction to Kafka...You can see each log line is annotated with a userId, and that’s happening because we explicitly annotated our logs by using ZIOAspect.annotated.
- bleep run
processor: To consume raw transactions from Kafka, enrich them, and produce them back to Kafka. We will see some nice logs like these:
15:37:04.409 [ZScheduler-4] [{userId=7}] INFO io.scalac.ms.processor.service.EnrichmentLive Enriching raw transaction.
15:37:04.411 [ZScheduler-4] [{countryName=Austria, userId=7}] INFO io.scalac.ms.processor.service.CountryCacheLive Getting country details from cache.
15:37:04.412 [ZScheduler-4] [{userId=7}] INFO io.scalac.ms.processor.service.EnrichmentLive Cache miss. Fetching country details from external API.
15:37:05.403 [ZScheduler-4] [{duration_ms=967, method=GET, request_size=0, status_code=200, url=https://restcountries.com/v2/name/Austria, userId=7}] INFO io.scalac.ms.processor.service.EnrichmentLive Http client request
15:37:05.448 [ZScheduler-2] [{countryName=Austria, userId=7}] INFO io.scalac.ms.processor.service.CountryCacheLive Caching country.
15:37:05.448 [ZScheduler-2] [{userId=7}] INFO io.scalac.ms.processor.ProcessorApp Producing enriched transaction to Kafka...You can see again each log line is annotated with a userId. Additionally, logs from CountryCacheLive are annotated with a countryName because we specified that in the CountryCacheLive code. And, there’s also logs coming from the ZIO HTTP Client (the lines that say Http client request), and they contain additional annotations automatically provided by ZIO HTTP, such as the request URL and method.
Summary
In this article, we have seen how libraries from the ZIO ecosystem (such as ZIO core, ZIO Streams, ZIO Kafka, ZIO HTTP, ZIO JSON, ZIO Config and ZIO Logging) in combination with Apache Kafka can help us to write purely functional event-driven microservices, which are performant, resilient, configurable and observable. And, this was just a very specific example of what you can do, there’s a lot more ideas you can apply to your own projects, so make sure to give these libraries a try!
References
- GitHub repository for this document
- Introduction to Programming with ZIO Functional Effects, by Jorge Vásquez
- “Mastering Modularity in ZIO with ZLayer” ebook by Jorge Vásquez
- ZIO documentation page
More on Akka
- Websockets Server with akka-http
- Akka Streams and RabbitMQ
- TestContainers in Scala: Use Integration Tests for building your services
- Handling Split Brain scenarios with Akka
- Programming in Scala: Carbon Footprint
Read more

Authors
I'm a software developer, mostly focused on the backend. I've had the chance to work with several technologies and programming languages across different industries, such as Telco, AdTech, and Online Education. I'm always looking to improve my skills, finding new and better ways to solve business problems. I love functional programming, I'm convinced it can help to make better software, and I'm excited about new libraries like ZIO that are making Scala FP more accessible to developers. Besides programming, I enjoy photography, and I'm trying to get better at it.
Popular Posts in category

Looking into Scala.js

Your first microservices using Scala and Lagom
Handling Split Brain scenarios with Akka



