

What is Apache Kafka, and what are Kafka use cases?
Application architecture is shifting from monolithic enterprise systems to more robust, resilient, flexible, and scalable event-driven approaches. Microservices architecture that applies reactive principles is the best way to develop modern systems more efficiently, but traditional approaches for communicating between them are still through their REST APIs.
However, as your system evolves and the number of microservices grows, communication becomes more and more complex, and the architecture might start to resemble spaghetti code, with services dependent on each other or tightly coupled, slowing down development teams. This model can exhibit low latency but only works if services are made highly available, which is sometimes very difficult.
New architectures aim to decouple senders from receivers, with asynchronous messages such as message-driven architecture and more specific event-driven architecture where thinking in events that are facts is simpler than thinking in the state. However, not only is the final state important, but it is also important to give tracking and analysis to the incoming data and how they reach that final state in terms of intention.
This is very useful for microservices because decoupling senders from receivers make them easier to construct and maintain over time and allows you to create logic to process those messages.
In this context, new tools such as Apache Kafka have become more relevant because its centric architecture can help keep latency low, with additional advantages such as message balancing among available consumers and centralized management. It also avoids the need for microservices orchestration, new failover requirements, and resilient design patterns.
Apache Kafka is the most popular event streaming platform, used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. This tool is perfect for microservices because it solves many of the issues of microservices orchestration while enabling the attributes that microservices aim to achieve, such as scalability, flexibility, efficiency, and speed. It also facilitates inter-service communication while preserving ultra-low latency and fault tolerance.
Let’s concentrate on Kafka, what this tool is, what are Kafka use cases and how it can achieve all of these benefits.
What is Apache Kafka?
Kafka was created around 2008 by Jay Kreps, Neha Narkhede, and Jun Rao who at that time worked at LinkedIn. It was a fiercely open-source project, now commercialized by Confluent, and used as fundamental infrastructure by thousands of companies such as Airbnb, Netflix, Twitter.
“Our idea was that instead of focusing on holding piles of data like our relational databases, key-value stores, search indexes, or caches, we would focus on treating data as a continually evolving and ever-growing stream, and build a data system — and indeed a data architecture — oriented around that idea.”
Jay Kreps — Confluent Co-Founder
Kafka came up with a solution to the problem with continuous streams of data, as there was no other solution at that moment that could handle such data flow.
Kafka is a distributed streaming platform for building real-time data pipelines and real-time streaming applications. It works like a publish-subscribe system that can deliver in-order, persistent messages in a scalable way.
Features
- Kafka is a distributed streaming platform for a publish-subscribe messaging system
- The messaging system lets you send messages between processes, applications, and servers, by:
- Storing streams of records in a fault-tolerant durable way.
- Processing streams of records as they occur.
- Kafka is used for building real-time data pipelines and streaming apps
- It is horizontally scalable, fault-tolerant, fast and runs in production in thousands of companies.
Originally started by LinkedIn, it was later donated as an open-source project to Apache in 2011.
Main Concepts and Terminology
- Event
- Broker
- Producers & Consumers
- Topic & Partitions
- Offset
- Consumer Group
- Replication
Event
An event records the fact that “something happened” in the world. It is also called a record or message. Reading or writing data to Kafka, happens in the form of events. An event has a key, value, timestamp, and optional metadata headers. Here’s an example of an event:
Event key: “Alice”
Event value: “Made a payment of $200 to Bob”
Event timestamp: “Jun. 25, 2020 at 2:06 p.m.”
Broker
Servers: Kafka is run as a cluster of one or more servers that can span multiple data centers or cloud regions.
Clients: These allow you to write distributed applications and microservices that read, write, and process streams of events in parallel, at scale, and in a fault-tolerant manner even in the case of network problems or machine failures.
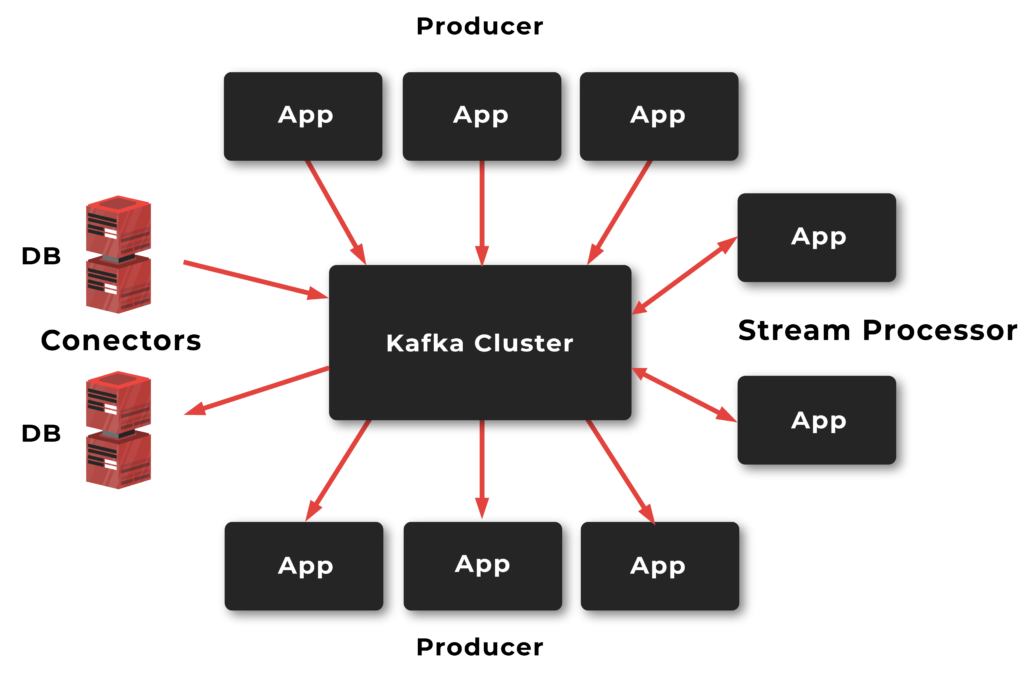
Producer and Consumer
Producer: this writes data to the brokers.
Consumer: this consumes data from brokers.
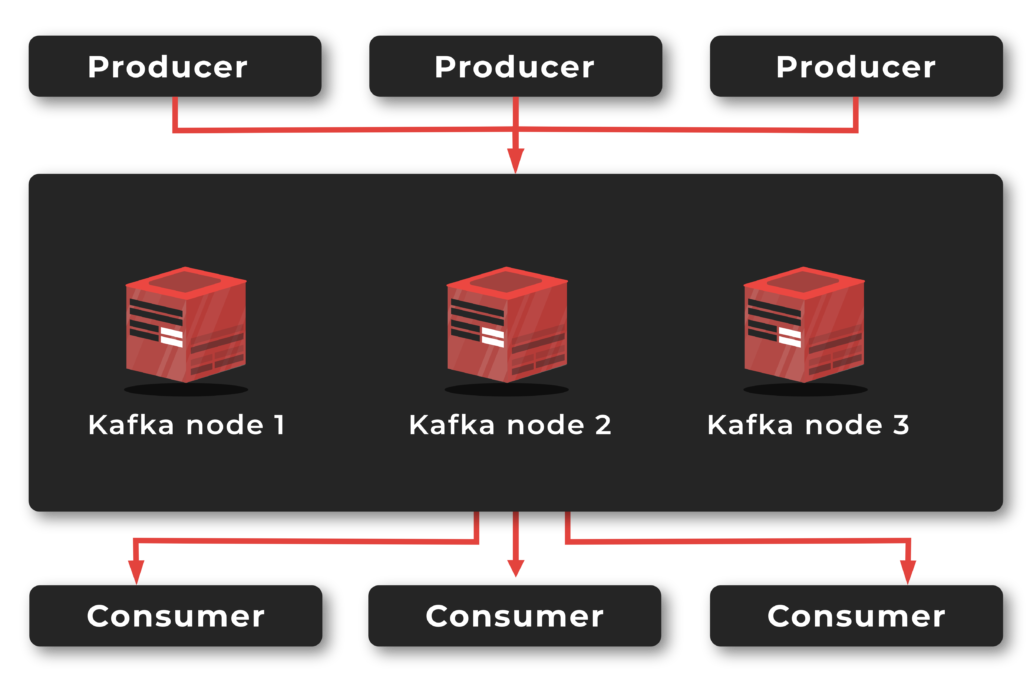
Apache Kafka clusters can be run on multiple nodes.
Topics and Partitions
Topics are partitioned, meaning a topic is spread over a number of “buckets” located on different Kafka brokers. This distributed placement of your data is very important for scalability because it allows client applications to both read and write the data from/to many brokers at the same time. When a new event is published to a topic, it is actually appended to one of the topic’s partitions. Events with the same event key (e.g., a customer or item ID) are written to the same partition, and Kafka guarantees that any consumer of a given topic-partition will always read that partition’s events in exactly the same order as they were written.
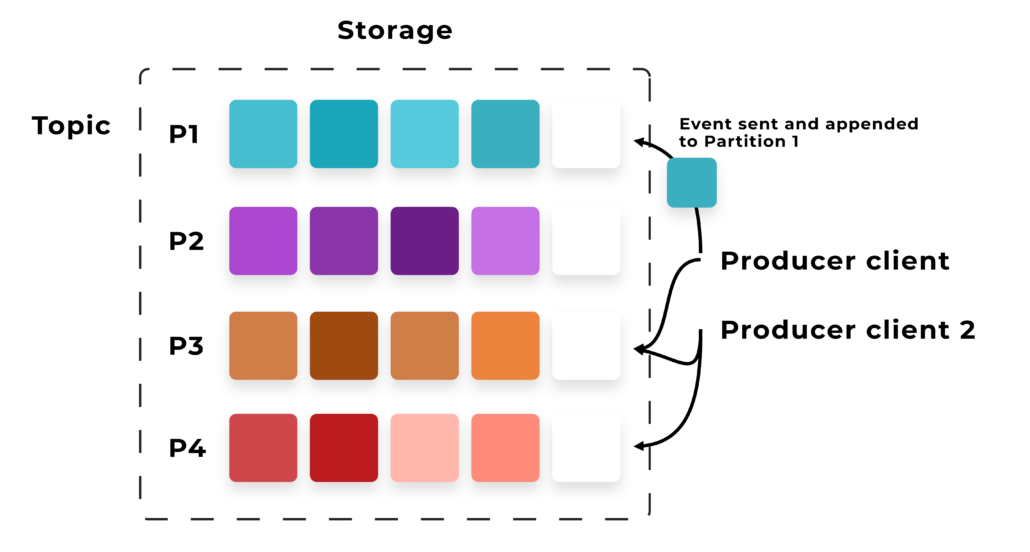
This example topic has four partitions P1–P4. Two different producer clients publish, new events independently from each other to the topic by writing events over the network to the topic’s partitions. Events with the same key (denoted by their color in the figure) are written to the same partition. Note that both producers can write to the same partition if appropriate.
Let’s recap this:
Topics
- A Topic is a category/feed name where records/messages are stored and published from.
- To send a record/message you send it to a specific topic, and to read a record/message you read it from a specific topic.
- Why topics: In a Kafka Cluster, data comes from many different sources at the same time. Ex. logs, web activities, metrics, etc. So Topics are useful in identifying where this data is stored.
- Producers write data to specific topics and consumers read data from specific topics.
Partitions
- Topics are divided into partitions, which contain records/messages in an unchangeable sequence (immutable).
- Each record/message in a specific partition is assigned and identified by its unique offset.
- One Topic can also have multiple partition logs. This allows multiple consumers to read from a topic in parallel.
- Partitions allow clients to parallelize a topic by splitting the data in a particular topic across multiple brokers
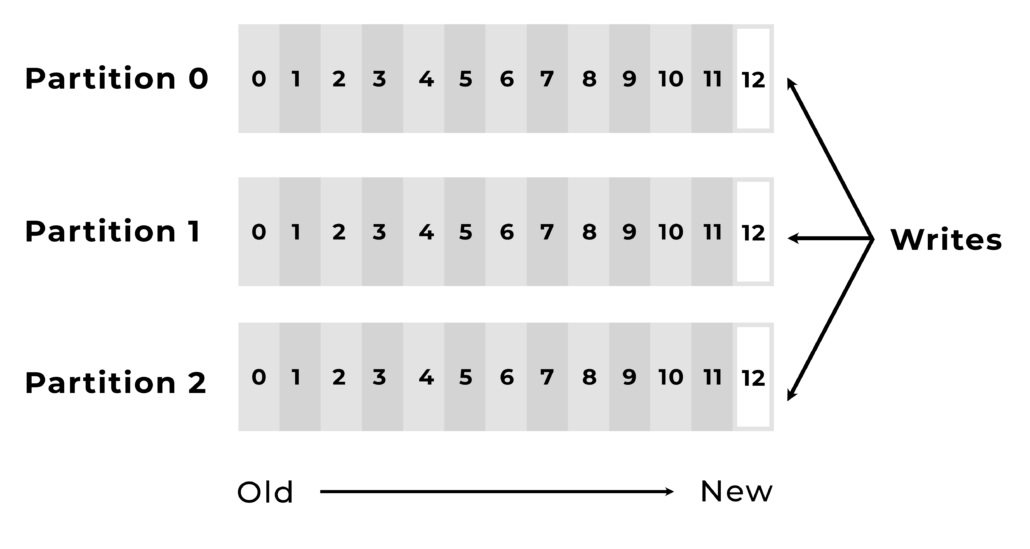
Here we can see how records/messages are chained in time into partitions.
Offset
Records or messages in the partitions are each assigned a unique (per partition) and sequential id called offset. Consumers track their pointers via (offset, partition, topic) tuples to identify the next records.
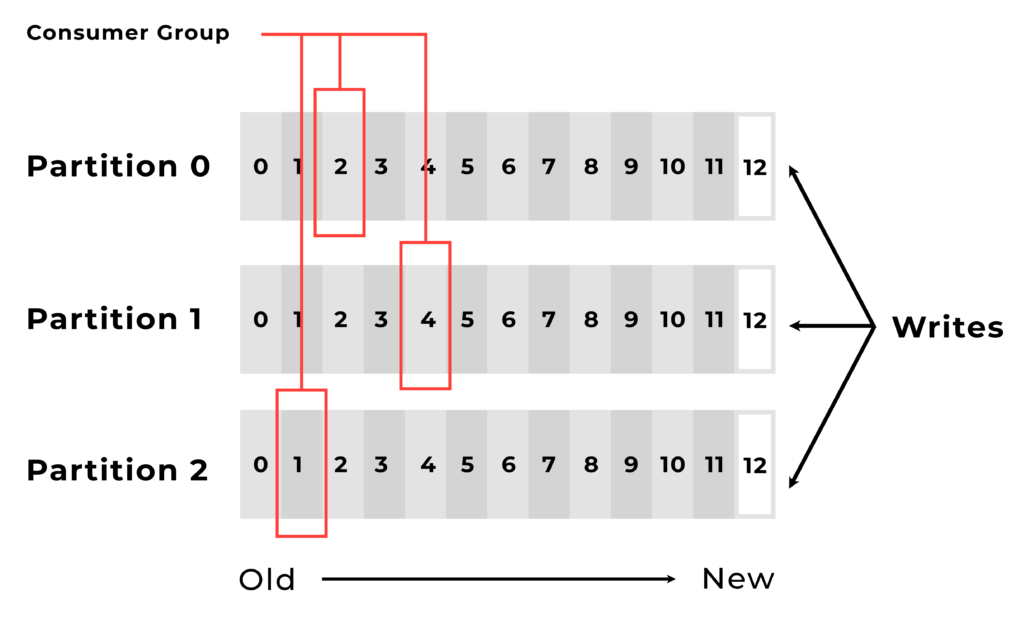
Here multiple clients have different offsets.
Consumer Groups
Consumers can read records starting from a specific offset and are allowed to read from any offset point they choose, this allows consumers to join the cluster at any point in time.
Consumers can join a group called a consumer group, a consumer group includes the set of consumer processes that subscribe to a specific topic.
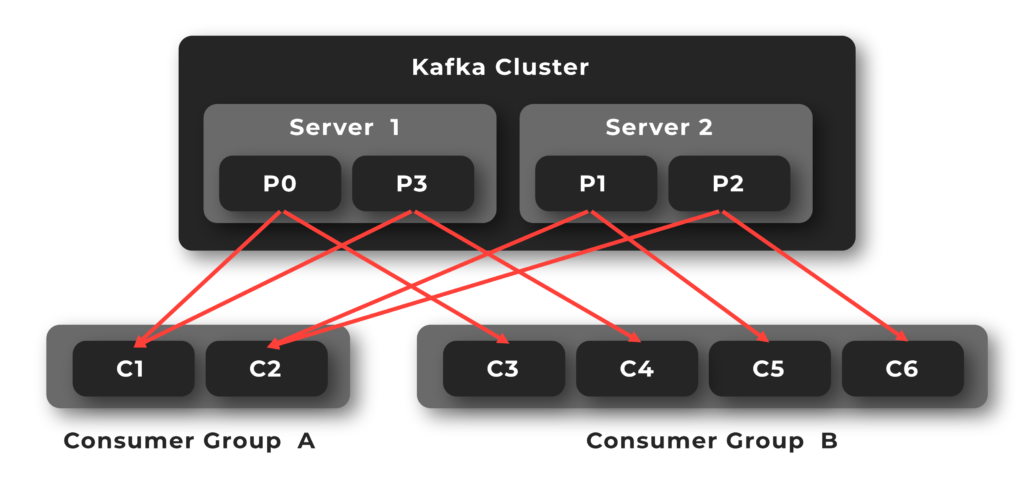
Here are two consumer groups that consume data in different ways.
Replication
In Kafka, replication is implemented at the partition level, which helps to prevent data loss.
The redundant unit of a topic partition is called a replica. Each partition can have one or more replicas meaning that partitions contain records that are replicated over a few Kafka brokers in the cluster.
How does all this work?
To sum up, Kafka allows clients to send and retrieve record messages between applications in distributed systems through the stream published. Record messages are grouped into topics. The producer sends record messages on a specific topic. The consumer receives all the messages on a specific topic from many producers. Any message from a given topic sent by any producer will go to every recipient who is listening to that topic. Kafka runs as a cluster of one or more brokers and communication between the clients and the brokers is done with a simple, high-performance, language-agnostic TCP protocol.
This is a lot of information but if you need more, take a look here or visit the confluent Kafka introduction page, where there is also an introduction to Kafka API.
Now we know basically how Kafka works, what are the use cases where Kafka can exhibit all of its potential? Let’s see.
What are Kafka use cases?
Since any data collected is very valuable, businesses today rely increasingly on real-time data analysis allowing them to gain faster insights and quicker response times. Insights in real-time allow businesses or organizations to make predictions about what they should stock, promote, etc. based on the most up-to-date information possible that they can collect.
Due to the distributed nature of today’s software, with reactive microservices architecture and the way it manages incoming data, Kafka is capable of operating very quickly and large clusters can monitor and react to millions of changes to a dataset every second. This means it has now become possible to start working with and reacting to streaming data in real time. By analyzing the clickstream data of every session, a greater understanding of user behavior is possible.
Kafka has become very popular and widely used and is an integral part of the stack at Spotify, Netflix, Uber, Goldman Sachs, PayPal, and 982 more (at the moment of writing this article). All of these use Kafka to process streaming data and understand customer, or system, behavior to derive more valuable information from the data.
Because of its characteristics, Kafka has actually become dominant in the travel and retail market industry, where its streaming capability makes it ideal for tracking booking details of millions of flights, package holidays, and hotel vacancies worldwide, taking real-time bids from different users, etc.
Kafka provides these main functions to its users:
- Publishing/subscribing to streams of event records
- Storing streams of records in the order in which the records were generated
- Processing streams of records in real-time
Kafka is mostly used to build real-time streaming data pipelines and applications that adapt to the data streams. It combines messaging, storage, and stream processing to allow storage and analysis of both historical and real-time data. Kafka is also often used as a message broker solution, which is a platform that processes and mediates communication between two applications as we saw previously.
Let’s take a closer look at the main Kafka use cases given by the documentation:
Messaging
Kafka works well as a replacement for a more traditional message broker. In comparison to most messaging systems, Kafka has better throughput, built-in partitioning, replication, and fault tolerance which makes it a good solution for large-scale message processing applications.
Website Activity Tracking
The original use case for Kafka was to be able to rebuild a user activity tracking pipeline as a set of real-time publish-subscribe feeds. This means site activity (page views, searches, or other actions users may take) is published to central topics with one topic per activity type. Activity tracking is often very high in volume as many activity messages are generated for each user page view.
Metrics
Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data.
Log Aggregation
Many people use Kafka as a replacement for a log aggregation solution. Log aggregation typically collects physical log files off servers and puts them in a central place for processing. Kafka abstracts away the details of files and gives a cleaner abstraction of a log or event data as a stream of messages. This allows for lower-latency processing and easier support for multiple data sources and distributed data consumption.
Stream Processing
Many users of Kafka process data in processing pipelines consisting of multiple stages, where raw input data is consumed from Kafka topics and then aggregated, enriched, or otherwise transformed into new topics for further consumption or follow-up processing.
Event Sourcing
Event sourcing is a style of application design where state changes are logged as a time-ordered sequence of records. Kafka’s support for very large stored log data makes it an excellent backend for any application built in this style.
Commit Log
Kafka can serve as a kind of external commit log for a distributed system. The log helps replicate data between nodes and acts as a re-syncing mechanism for any failed nodes to restore their data.
What are the benefits of Kafka?
Scalable:
Kafka’s partitioned log model allows data to be distributed across multiple servers, making it scalable beyond what would normally fit on a single server.
Fast:
Kafka decouples data streams so there is very low latency, making it extremely fast.
Durable:
It helps protect against server failure, making the data very fault-tolerant and durable.
Performance:
It is stable, provides reliable durability, has a flexible publish-subscribe/queue that scales well, has robust replication, provides producers with tunable consistency guarantees, and provides a preserved order at the topic-partition level.
Reacting in real-time:
Kafka is a big data technology that enables you to process data in motion and quickly determine what is working and what is not.
There are many other benefits to Kafka that could be a good reason to start using it, as the organizations that have been already mentioned have discovered. However, there are a lot of technical challenges that your organization will need to overcome in order to achieve your goals when using Kafka.
Conclusions
The main benefits of event-driven systems are their asynchronous behavior and loosely coupled structures. For example, instead of requesting data when needed, apps consume them via events before needed. Therefore, overall app performance increases. On the other hand, keeping coupling loose is one of the main key points of a microservice environment that is scalable and flexible.
In this article, we have learned that systems have changed and new thinking is required because not only is the state important but also important is how you reached that state, so the need to capture intentions is necessary for modern systems. This will help business organizations to better analyze their incoming data and make predictions or determine user and system behavior.
Kafka as an event streaming platform is one of the best tools available for high-performance data processing and message-driven systems, and as we have seen, the benefits of the use cases make it a great option for production environments for multiple propositions.
Kafka has demonstrated it is a great tool for giving organizations the ability to process real-time data in a very efficient way, allowing engineering teams to make use of its scalable abilities, based on clusters, to improve performance to meet modern demands and allow other features.
Finally and more importantly, Kafka can act as a source of truth, being able to distribute data across multiple nodes for highly available deployment within a single data center, or alternatively across multiple availability zones, and being of great help within a lot of modern architectures.
Read also

Authors
Computer Science Engineer, Scala Developer at Scalac. Functional programming enthusiast and natural-born backend developer. Football and chess lover.
Popular Posts in category

Looking into Scala.js

Your first microservices using Scala and Lagom
Handling Split Brain scenarios with Akka



