

How We Reduced Costs and Simplified Solution by Using Apache Druid
At Scalac we always try to use appropriate technology to meet the requirements given by the business. We’re not afraid to change them once we realize they’re not fit for purpose. By making these changes we learn, we grow, we evolve. In this article, we want to share what we learned during the migration from Apache Spark + Apache Cassandra into Apache Druid.
Why did we decide to do it?
What you can expect after the change?
How did this change reduce costs and simplify our solutions and why did we fail to deliver expectations with the first architecture?
Let’s find out together!
The Law of Expectation
Defining expectations is a crucial part of every architecture, application, module or feature development. The expectations that were presented to us were as follows.
We need to process and deliver data to the UI in near real-time.
Since our project is based on Blockchain, we want to react to all of the changes as soon as they are made. This can be achieved only in real-time architecture. This is one of the most important decisions to be taken at the beginning of the project because it limits the range of technologies we can take with us.
We need to be able to display aggregated data with different time granularities.
To improve performance and readability on the UI, we want to return aggregated data. This should make displaying the data more responsive and lightweight. The solution should be flexible enough to allow us to configure multiple time-ranges because they are not yet defined and may depend on the performance or layer findings.
We need to introduce a retention policy.
Since the data after a specific time are meaningless for us, we do not want to keep them forever and we want to discard them after 48 hours.
We want to deploy our solution on the cloud.
The cloud is the way-to-go for most companies, especially at the beginning of a project. It allows us to scale at any time and pay for the resources we are using. Often just a small number of developers start a project, so there is no time to focus on machine management. The entire focus should be on something that brings value to the business.
We want to be able to display data about wallets and transactions.
Since this project is all about Blockchain, we want to display some information on different levels. The most detailed is at the transaction level, where you can see data exchange and payments between different buyers and sellers. Wallet groups multiply transactions for the same buyer or seller. This allows us to observe the changes in the Blockchain World.
We want to display TOP N for specific dimensions.
In order to display wallets that have the biggest participation in day-by-day payments in Blockchain, we need to be able to create tables that will contain wallets sorted by the amounts of data changes or payments during a certain time.
Let’s take Spark along with us!
Since the road for creating real-time architecture was a bit dark for us at the time, we decided to take Apache Spark along with us! Nowadays, Spark is advertised as a tool that can do everything with data. We thought it would work for us… but we couldn’t see what was coming. It was dark, remember?
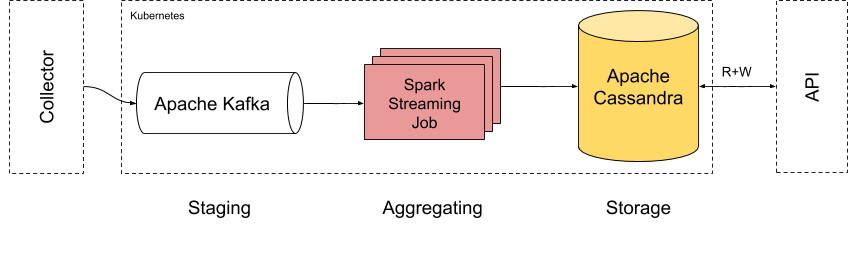
Architecture
Initially, we came up with the above architecture. There are a couple of modules that are important, but they are not crucial for further discussion.
- Collector – This was responsible for gathering the data from different APIs such as Tezos and Ethereum, unifying the format between these two and pushing these changes to Apache Kafka in the form of JSON. Additionally, since we were dealing with streaming, we needed to know where we were, so we would be able to resume from a specific place so not to read the same data twice. That’s why Collector saves the number of processed blocks to the database – Apache Cassandra in our case. We had it in place, we simply used it for a slightly different purpose.
- API – This was a regular API, simply exposing a couple of resources to return results from Cassandra to our UI. It is important to know that it was not only the window for the data in Cassandra, in this API, we could also create users, roles and write them back to the database.
Motivation
It’s always important to ask yourself why you are choosing these technologies, what you want them to do for you. Here are the motivations for the tools that we decided to use:
Why did we decide to use Apache Kafka?
At the very beginning, we wanted to create a buffer in case Spark would be too slow to process these data, to not lose them. Additionally, we wanted to separate two different tools from each other. Direct integration between Data Source and Spark might be hard and deployment of any of these components could break the entire pipeline. With Apache Kafka between them, it’s unnoticeable. Since the entire solution was designed to work with Blockchain, we knew that we couldn’t lose any transactions. Thus Kafka was a natural choice in this place. Additionally, to fulfill also the requirement for different time-series to be handled. We knew that we could read the same data, from the same topic by multiple consumers. Apache Kafka is very popular, with good performance and documentation.
Why did we decide to use Spark Streaming?
Spark Streaming was a good choice in our opinion due to the fact that it has good integration with Apache Kafka, it supports Streaming (in the form of micro-batches), it has good integration with Apache Cassandra and aggregating by a specific window is easy. Spark Streaming stores the results of the computation in the internal state, so we could configure it to precompute TOP N wallets by the transactions there. Scaling in Spark is not a problem. Spark supports multiple modes for emitting events (OutputMode) and for writing operations (SaveMode). We thought that OutputMode.Append and SaveMode.Append would be a good option for us.
Why did we decide to use Apache Cassandra?
We decided to use Apache Cassandra mostly due to fast reads and a good integration with Spark. Additionally, it’s quite easy to scale Cassandra as well. Cassandra is also good if we want to store time-series data. SQL should not be too hard for this , in our case data should be already prepared. Cassandra requires more on the writing side than reading.
1. First bump. Stream Handling in Spark.
At the beginning, we didn’t realise that one of the problems would be that Spark can read/write only from/to one stream at a time. This meant that each time we wanted to add another time dimension we would need to spawn another Spark Job. This problem had an impact on the code because it had to be generic enough to handle multiple dimensions by its configuration. Adding more and more Jobs always increases the complexity of the entire solution.
2. Second bump. Cluster requires more and more resources.
Along with the generalization of Spark Job, we had to change our infrastructure. We were using Kubernetes for this, but the problem was that with Spark we could not assign less than 1 core even though Kubernetes allows us to assign 0.5 CPU. This led to poor core utilization of Kubernetes Cluster. We were forced multiple times to increase the resources within the Cluster to run new components. At some point, we were using almost 49 cores!
3. Third bump. Spark’s OutputMode.
We didn’t have to wait too long for the first problems. That was actually a good thing! We realized that OutputMode.Append was not going to work for us. You may ask yourself: why? Glad you asked! We’re happy to explain.
We need to be able to ask Apache Cassandra for the TOP N results. In our case, it was the TOP 10 wallets by the number of transactions made by them.
Firstly, let’s think about the table structure:
Secondly, let’s think about the query:
Due to the definition of primary key + WITH CLUSTERING ORDER BY, the data will already be sorted by amount.
Thirdly, let’s insert some data into it:
Now imagine that Spark is grouping the data for a 10-minute window and it’s going to emit an event once the internal state changes. Only the change itself will be emitted.
The new transaction is coming for the wallet: WALLET_A, time: 2020-01-01 10:03:00.000 and amount: 500.
After that, Spark is going to emit an event and ask Cassandra to insert:
Normally, what we would expect is that the first row from the data we inserted would be updated, but it wasn’t because the ‘amount’ which changed, is part of the primary key. Why is this important? Because with insert operation instead of update we will have multiple rows for the same wallet. We cannot change the primary key, because we want to sort the data by the amount and so the circle closes.
Can OutputMode.Complete push us forward?
Since the road with OutputMode.Append was closed for us, we decided to change the output mode to Complete. As the documentation says, the entire state from Spark will be periodically sent to Cassandra. This would, of course, put more pressure on Cassandra, but at the same time, we would ensure that we would insert no duplicates into the database. In the beginning, everything worked well, but after some time, we noticed that with each insert, Spark was putting in more and more rows.
Let’s turn back. Spark + Cassandra does not meet our expectations.
Why did we decide to turn back and change the current architecture? There were two main reasons.
Firstly, we investigated why Spark was adding only new rows and it turned out that Watermark which is configured in Spark does not discard the data when they should be. This means that Spark would collect the data indefinitely in its internal state. Obviously, this was something that we could not live with and that was one of the most important reasons to change Spark + Cassandra. Spark could not produce the results for one of the most important queries, so we had to turn back.
Secondly, we noticed that maintenance was getting more complicated with each time-series dimension and the configuration for resources for Spark Cluster was not flexible enough for us. This led to too high costs for the entire solution.
The New Beginning, with Apache Druid.
You may ask yourself why we decided to choose Apache Druid? As it turned out, when you are deep in the forest, a Druid is the only creature that can navigate you through it.
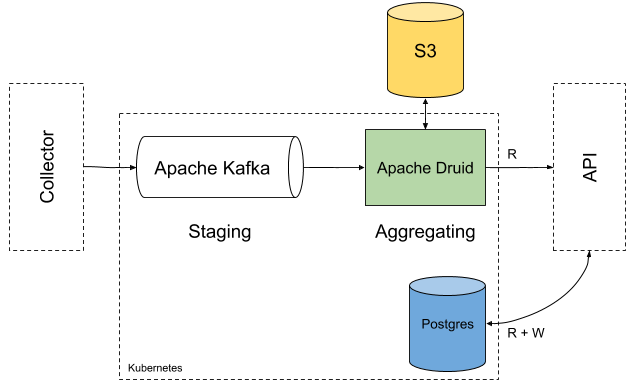
Architecture
At first glance the change is not that significant, but when you read the motivation, you will see how much good this change did for us.
Motivation
- Firstly, Apache Druid allows us to explore the data, transform them and filter what we do not want to store. It contains databases as well, so we can configure the data retention policy and we can use SQL to query against collected data. This means that Druid provides a complete solution for processing and storing the data, whereas in the previous architecture we had been using Apache Spark + Apache Cassandra. By using this tool, we could delete two components from our initial architecture and replace it with a single one, which reduced the complexity of the entire solution. Additionally, it gave us a single place to configure it all. As a trade-off, this solution is not as flexible as Apache Spark + ApacheCassandra may be. A lack of flexibility can be noticed mostly at the data transformation + data filtering more than in the storage. Even though Druid provides simple mechanisms to do this, it’s not going to be as flexible as writing code. Since we mostly aggregate by time, this is a price we can pay.
- Secondly, the configuration of Apache Druid on top of Kubernetes is much better. Druid contains multiple separated applications that handle different parts of the processing. This allows us to configure resources at multiple levels, so we can use the resources we have more efficiently.
- Thirdly, in Apache Druid, we can use the same data source multiple times to create different tables. Since we used Apache Druid mostly to fulfill the TOP N query, we re-used the same topic in Kafka twice. With and without rollup. Since the smallest time granularity that we have is 1 minute, this is how rollup was configured. This speeds up the query causes that the data are already pre-aggregated. This may have a huge impact when the rollup ratio is high. In cases when it’s pretty low, we should disable it.
- Fourthly, since there is a UI in Apache Druid, you do not need to write any code to make it work. This is different from what we had to do in Apache Spark. At the end of the configuration process in Apache Druid, we got JSON, which can be persisted and versioned somewhere in an external repository. Note that some of the configurations (such as retention policies) are versioned by Apache Druid automatically.
- Fifthly, Apache Cassandra is not the best database to store data about users, permissions, mostly website management data. This is due to the fact that Cassandra is made for fast reads, and operations of this kind can have a negative performance impact. To avoid this, these operations are not supported by design. This is why relational databases are better for this kind of data and we decided to introduce PostgreSQL for it.
What did Druid tell us?
Most likely, you don’t want to run Druid in local mode.
By default, Druid is configured to run only one task at a time (in local mode). This is problematic, when you have more data sources to be processed, essentially, creating more than one table in Druid. We had to change druid.indexer.runner.type to “remote” to make it work as expected. When you have only one task running and multiple pending, make sure that you have this option changed to ‘remote’. You can read about that here.
The historical Process needs to see segments.
We encountered an issue with the Historical Process, which did not notice the segments (files) created by Middle Manager. This happened because we did not configure proper storage for the segments. Druid works in a way that the segments need to be accessible via Historical Service and Middle Manager because only the ownership is transferred from Middle Manager to Historical Service. That is why we decided to use storage from the Google Cloud Platform. You can read more about deep storage here.
What resources did we burn?
Apache Spark + Apache Cassandra | Apache Druid | |
CPU | 49 cores | 6 cores |
RAM | 38GB | 10GB |
Storage | 135GB | 20GB |
As you can see, we managed to drastically decrease the number of cores used to run our infrastructure as well as memory and storage. The biggest reason why this was possible was that we had multiple Spark Jobs running to do the same task that the single Apache Druid can do. The resources needed for the initial architecture had to be multiplied by the number of jobs running, which in our case was 24.
Summary
To sum up what we learned during this venture.
Apache Spark is not a silver bullet.
Spark allows us to do many, many things with the data. Beginning with data reading from many formats, cleaning data, transforming them, aggregating them and finally writing to multiple formats. It has modules for machine learning and graph processing. But Spark does not solve all the problems! As you can see, in our case it was impossible to produce results that could fulfill the requirements of aTOP N query.
Additionally, you also need to keep in mind that the architecture of your code, the generalization, and the complexity of it will significantly affect the resources needed to process the data. Due to the fact that we had 24 jobs to be executed, we needed a huge amount of resources to make it work.
Apache Spark is made for big-data.
When you have many gigabytes of data to be processed, you could consider Spark. One rule says that you should consider using Spark when the biggest machine does not allow you to process the data on it. Keep in mind that processing data on a single machine will be always better than doing it on multiple machines (I’m not saying faster, but sometimes this can be also seen). Nowadays everyone wants to use Spark, even if there are just a couple of megabytes of data. Bear in mind, choosing the right tool for the right job is half of the success.
There is always a tradeoff.
There are no silver bullets in the Software Development World, Spark is not one of them as you have seen above. There is always a tradeoff.
You can drive faster, but you will burn more fuel. You can write your code faster, but the quality will be poorer. You can be more flexible, generalize your code better, but it will become harder to read, extend, debug. Finally, you can pick a database that allows you to read fast, but you will need to work more on the structure of this database and writing into it will be slower.
You need to find the right balance and see if you can cope with the drawbacks that a specific technology brings along with its positives.
Use the right tool for the right job.
Good research is the key to making sure that the appropriate technology has been chosen. You need to remember that sometimes it is better to reserve a bit more time for investigation, writing a Proof of Concept before diving hard into one or other technologies. You will definitely end up wasting time having to rewrite your solution. Obviously, this depends on where you spot the first obstacles. In our example, you can see that firstly our infrastructure was quite complicated and required a lot of resources. We managed to change it dramatically by using a better tool which fitted the purpose better.
How it looks now. A working solution.
Even though this article sounds a bit theoretical, the project we took this experience from is real and still in progress.
The Analytical Dashboard that we created to visualize the data from different blockchains are based on React with Hooks, Redux, Saga on the front side, and Node.js, Apache Druid, Apache Kafka on the back-end.
On the day of writing this article, we are planning to re-write our data source component from Node.js to Scala + ZIO. So you can expect some updates, either in the form of a blog post or an open-source project at GitHub. We have a couple of Blockchains integrated, and we are planning to add more. We are also planning to make the API public so that everyone can experiment and learn from it just as we did.
Check out also our websites on:
Scale fast with Scalac – Scala development company ready to solve all your challenges.
See also

Authors
I started my journey with Software Development over eight years ago. Starting from Backend Developer, throughout Frontend Developer, and finished as Data Engineer. I've worked in AdTech companies, where shuffling hundreds of gigabytes of the data daily. I'm always trying to stay up to date with new technologies, languages, tools, and frameworks, anything that can help me with solving Real World problems because that is what matters the most.
Popular Posts in category

Looking into Scala.js

Your first microservices using Scala and Lagom
Handling Split Brain scenarios with Akka



