Hadoop vs Spark: What’s the difference?
Intro
Data is the new oil. We hear this all the time these days. But whether it’s true or not, we know the real value that comes from processing data. Each year we can see new tools springing up created for just that purpose. Of these, Apache Hadoop and Apache Spark seem to be the most popular. But which one should you use? And which is best used to process clickstream data or to create ML predictive modeling? Can they be used together? What are the pros and cons of each? In this article, we will try to answer all of these questions by examining these two tools from a few perspectives.
What is Hadoop?
Apache Hadoop is a project created by Yahoo in 2006, later on becoming a top-level Apache open-source project. The Apache Hadoop software library is a framework that allows distributed processing of large data sets across clusters of computers using simple programming models. It uses MapReduce to divide the data into blocks and to assign the chunks to nodes across a cluster. Later the data is stored, processed in parallel on each node to produce an output.
Hadoop has several components:
- Hadoop Distributed File System (HDFS) which allows files to be stored in a Hadoop-native format and thanks to parallelization gives a lot of options when it comes to scaling
- YARN, a scheduler coordinating applications at runtimes
- MapReduce, an algorithm responsible for processing data in parallel
- Hadoop Common, a set of common libraries supporting other modules
Apart from that, Hadoop also includes:
- Sqoop, responsible for moving relational data into HDFS,
- Hive, an SQL-like interface that helps to write and execute queries on HDFS,
- Mahout, which provides an implementation of some ML algorithms.
Hadoop natively utilizes Java. Fortunately, nowadays you can find client applications written in languages other than Java. Thanks to this, you will be able to easily adapt Hadoop to your projects.
What is Spark?
Apache Spark, which like Apache Hadoop is also an open-source tool, is a framework that can run in standalone mode, on a cloud, or an Apache Mesos. It’s designed for fast performance and uses RAM (in-memory) for its operations.
While Hadoop writes & reads data from HDFS, Spark does this with RAM using a concept known as a Resilient Distributed Dataset.
Spark has five main components:
- Its Core, which is a common library for a project containing functions such as task dispatching, scheduling, IO operations, etc.,
- Spark Streaming, which enables live data stream processing from many sources,
- MLib, which is a library containing ML algorithms,
- GraphX, which is a set of APIs used for graph analytics,
- SparkSQL, which is a component allowing SQL-like commands to be run on distributed data sets
Even though Spark’s interface was written in Scala, you could also write Spark jobs using other languages as well. Integration with libraries such as PyTorch or TensorFlow is also pretty easy.
Comparison
Architecture
At the start of the process, all of the files are passed to HDFS. Later on, they are divided into chunks. Each of these chunks is replicated a specified number of times across the cluster.
This information is passed to the NameNode – the node responsible for keeping track of what happens across the cluster. The NameNode assigns the files to several data nodes, on which they are then written.
When the application is implemented in one of the supported languages, then the JobTracker, which comes from MapReduce, is responsible for picking it up and allocating the work to TaskTrackers, listening on other nodes.
Later on, YARN allocates the resources that JobTracker spins up and monitors all the results from the MapReduce processing stage, which are then aggregated and written back to disk in HDFS.
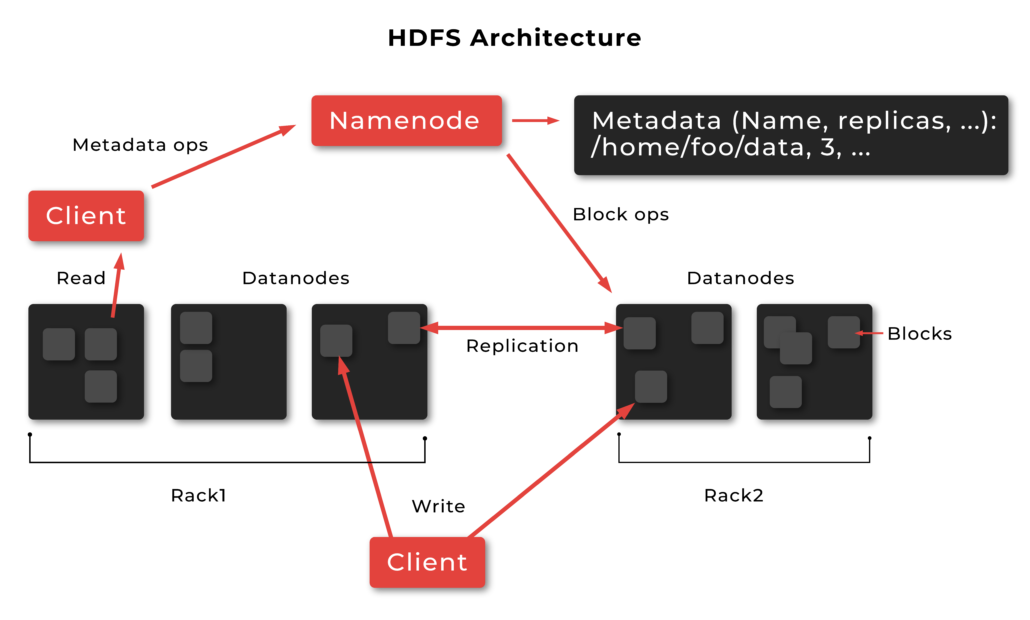
Design by Scalac, info from http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
The way Spark operates is similar to Hadoop’s. The key difference is that Spark keeps the data and operations in-memory until the user persists them. Spark pulls the data from its source (eg. HDFS, S3, or something else) into SparkContext. Spark also creates a Resilient Distributed Dataset which holds an immutable collection of elements that can be operated in parallel.
Not only that, but Spark also creates a Direct Acyclic Graph to visualize all of the steps and relationships between them.
Users can also perform other actions such as transformations, final steps, or intermediate steps on RDD.
From SPark 2.0, users can use DataFrames which are like RDDs but they put data into named columns. This makes them more user-friendly. Thanks to SparkSQL, users can query DataFrames using similar syntax to native SQL.
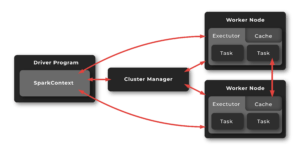
Design by Scalac data from https://spark.apache.org/docs/latest/cluster-overview.html
Performance
Even though it might seem counter-intuitive to look at both tools, compare their performance and the way they process data, we still may choose the faster option. Hadoop boosts its performance by accessing data stored on HDFS. However, this still cannot compete with Spark’s in-memory processing as Spark has been found to run 100 times faster when using RAM and 10 times faster on disk.
As the research shows, [1] [2] [3] Spark was 3x faster and needed 10x fewer nodes to process 100TB of data on HDFS. Spark has also been found to be faster with machine learning applications, such as Naive Bayes and k-means.
The main reason for this is that Spark does not read and write intermediate data to disks but uses RAM. On the other hand, Hadoop stores data on a lot of different sources and then processes the data in batches using MapReduce.
These arguments all put Spark in the leader position. Yet, if the size of data is larger than the available RAM or if Spark is running on YARN with other shared services, its performance might degrade and cause RAM overhead memory leaks. In that case, Hadoop would be the more logical choice.
Cost
Comparing the costs of Spark and Hadoop we need to look at the wider picture. Both tools are open-source and free. Apart from that we still need to take development, maintenance, and infrastructure costs into account. The general rule of thumb for on-prem installations is that Hadoop requires more memory on disk and Spark requires more RAM, meaning that setting up Spark clusters could be more expensive. Additionally, since Spark is the newer system, experts in it are rarer and therefore more costly. Another option is to install them using a vendor such as Cloudera for Hadoop, or DataBricks for Spark, or run EMR/MapReduce processes in the cloud with AWS.
Another concern might be in finding experts that can help you with the technology. As Hadoop has existed longer on the market, it is easier to find a specialist than with Spark.
Fault tolerance
If we speak about fault tolerance then both solutions provide a decent level of handling failures.
Hadoop achieves it by its design – data replication across many nodes. If an error occurs then it fetches the missing data from another location as needed. The main node has the traceability of other nodes built-in. If a single machine goes down, the file can be rebuilt from other blocks elsewhere.
For the same purpose, Spark uses RDD. This consists of a lineage that remembers how the dataset was constructed and, since it’s immutable, can rebuild it from scratch using DAG tracking of the workflow.
Security
In terms of security, Hadoop is the winner. Spark’s security is weakened by its design. Spark’s security model is not enough for production systems as it only allows authentication via shared secret or event logging but this is not enough when it comes to production.
Although both tools can rely on Kerberos authentication, Hadoop’s security control for HDFS is much more fine-grained. Another project also available for changing HDFS security levels is Apache Sentry.
Machine Learning
As Machine Learning is a process where in-memory computing works best, Spark should be the obvious choice here as it’s faster. For this purpose, it has MLLib, which is available in Scala, Java, R, and Python. The library contains regression and classification algorithms as well as allowing you to build custom ML pipelines.
As an example, Hadoop MapReduce splits jobs into parallel tasks that may be too large for machine-learning algorithms. This process creates I/O performance issues in these Hadoop applications. Mahoot also is the main library for ML in Hadoop clusters. It’s based on MapReduce to perform all of its necessary operations. This is slowly being changed to Samsara which is a DSL (with Scala under the hood) designed for writing your own ML solutions.
Scalability
In this category, we don’t have any winners. Hadoop uses HDFS to take care of the vast amount of data. If it grows, then Hadoop can accommodate and scale as needed. Spark relies on HDFS when the data is too large to deal with. New clusters can expand and add more and more power, they might end up having thousands of nodes and there is no set limit.
Scheduling and resource management
For resource scheduling, Hadoop uses external tools as it does not possess its own solution. For example, YARN might use NodeManager or ResourceManager to take care of scheduling in a Hadoop cluster. Another tool for scheduling workflows is Oozie.
YARN is only responsible for allocating available processing power.
In addition, Hadoop MapReduce is compatible with plugins such as FairScheduler or CapacityScheduler. These try to allocate crucial resources to maintain cluster efficiency.
Spark contains these functions by design. The DAG scheduler handles the dividing of operators into stages. Every stage has a lot of tasks that DAG schedules and Spark needs to execute.
Spark Scheduler and Block Manager perform the job and task scheduling, monitoring, and resource distributions in a cluster.
Use cases: When to use Hadoop and when to use Spark
Below you can find some common use cases for using both tools.
Hadoop use cases
- Enormous dataset processing where the data size is bigger than the available RAM.
- Creating infrastructure for data analytics.
- Finishing jobs where results are not expected immediately and time is not a significant constraint.
- Processing batches with jobs using IO operations.
- Saving archive data analysis.
Industries and companies using Hadoop are:
- Social media (Facebook, Twitter)
- Retail / eCommerce. (Alibaba, eBay)
- Video Delivery. (Hulu)
- Games. (IMVU, Gewinnspiele)
- Online Music (Last.fm, Spotify)
- And many many more.
Spark use cases
With Spark, we can identify the following use cases where it outperforms Hadoop:
- Stream data analytics.
- Completing jobs where time and speed are important factors.
- Parallel operations handling with usage of iterative algorithms.
- Creating machine learning models.
- Combining Spark and Hadoop.
Industries and companies using Spark are:
- Education (UC Berkeley)
- Retail / eCommerce. (Alibaba, eBay, Groupon)
- Data Analytics (4Quant)
- Operations. (Falcony)
- Fitness (MyFitnessPal)
- And many many more.
When to use Hadoop and Spark
Hadoop and Spark don’t have to be mutually exclusive. As practice shows, they work pretty well together as both tools were created by the Apache. By design, Spark was invented to enhance Hadoop’s stack, not to replace it.
There are also some cases where the most beneficial would be to use both of these tools together. Both solutions would rather complement each other than replace each other or compete. For example, you could use them both for :
- streaming vast amounts of data that needs to be saved.
- creating complex ML algorithms while storing some results or output.
- fog computing.
Summary
The main goal of this article was to give the reader an overview of the two most popular tools for distributed data processing that are currently available. Hadoop is built on top of MapReduce and uses a lot of IO operations, while Spark is more flexible but more expensive for processing data in-memory.
Both tools were developed by Apache and are a great fit for its ecosystem with other components and projects. They are very often used together. It’s crucial to understand them, know their differences and similarities, so we can use them alongside each other and produce the best outcomes for our business needs.
Resources
- https://spark.apache.org/
- https://spark.apache.org/news/spark-wins-daytona-gray-sort-100tb-benchmark.html
- https://udspace.udel.edu/bitstream/handle/19716/17628/2015_LiuLu_MS.pdf
- https://logz.io/blog/hadoop-vs-spark/
- https://phoenixnap.com/kb/hadoop-vs-spark
- https://perfectial.com/blog/hadoop-vs-spark/
- https://www.dezyre.com/article/top-10-industries-using-big-data-and-121-companies-who-hire-hadoop-developers/69
- https://databricks.com/blog/2014/01/21/spark-and-hadoop.html
- https://spark.apache.org/powered-by.html
Read more

Authors
Seasoned software engineer specializing in distributed systems, functional programming, data-driven systems, and ML. Worked for various clients across industries like FinTech, Telco, AdTech, and Healthcare. On the mission to empower the Scala community. During my free time trying to connect 20+ years of being a professional athlete and entrepreneurship.