

Apache Spark 101
During our last internal Backend Guild meeting we discussed the topic of Apache Spark. This post is to fill the details we missed and to organize the knowledge so it might be useful for people willing to start with Spark.
Full source code is available on GitHub.
Big Data Challenges
It all starts with the data.
We live in the age of Big Data. With the dropping prices of storage companies are gathering more and more data, hoping to get an upper hand in their markets. As a result the requirements put on IT systems changed. Systems need to hold more information, have a bigger throughput while allowing real-time data streaming and feature extraction.
The bar for modern systems was never as high as today.
In order to meet those requirements we need a new generation of tools and Apache Spark is one of them.
What is Spark?
![]()
Apache Spark is an open source, top-level Apache project. Initially built by UC Berkeley AMPLab it quickly gained wide spread adoption. Currently having 800 contributors coming from 16 organizations.
Spark aims to leverage existing infrastructure for fast and efficient data processing at scale. The goal is to build an engine versatile enough to run any computation with ease on any cluster. Although written primarily in Scala, it also offers support for Python and R.
It also comes with a set of libraries to aid you with some common needs: Spark SQL (to query your data with SQL), Spark Streaming (to work with streamed data), MLlib (for machine learning) and GraphX (when you need to efficiently process large graphs).
Sparks has many applications throughout the industry – Relationship Extraction, Time Series Analysis, Anomaly Detection, Simulations of all kinds, Security Analysis, Drug Discovery and much more.
Does Spark meet the Big Data Challenge?
Considering that Spark is used in companies like Amazon, Baidu, Groupon, IBM, Samsung Research, TripAdvisor and Yahoo! clearly the answer is yes. But how does it do that?
At it’s core Spark is an abstraction over map-reduce paradigm making it easier to use with real life problems, while keeping the efficiency and compatibility with existing infrastructure.
It all starts with the concept of an RDD – Resilient Distributed Dataset. RDDs are an abstraction over data. They can be viewed as a pointer to a dataset. Having the pointer we can ask Spark to apply some computations on the data we are pointing to, but it’s up to the engine to decide when, where and how to apply those changes.
Datasets in Spark are called resilient, because Spark always knows the initial state of the set and the computations being performed, so in face of a failure the engine is able to recompute any intermediate set. Datasets are also distributed, because Spark knowing the underlying hardware infrastructure is able to spread the data evenly among worker nodes.
RDDs borrow concepts from Functional Programming. They are immutable – when we order an operation to be applied over the dataset the old one isn’t updated nor destroyed. Instead we simply get another RDD pointing to the data after transformation. They are also lazy – computation is performed not when we ask for them, instead they are collected and called only when it’s necessary to return the results.
In Spark developers role is to chain RDD operations together according to some business logic in order to get the final result. It’s the engines responsibility to run them efficiently, thus freeing devs from thinking about platform details.
When working with RDDs underneath Spark is building a Directed Acyclic Graph (DAG for short) of our computations, where RDDs are the nodes and computations are the vertexes. When we call an action, Spark will use this DAG to decide what is the optimal way to run our computations.
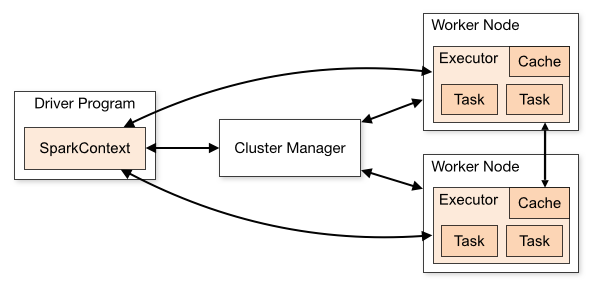
The last thing to mention here is the division between driver and nodes. Spark apps wouldn’t be much faster than average if they wouldn’t be distributed and running in parallel. Spark clusters very often contain many worker machines and one leader to manage the work being done.
This approach is also visible in Spark – there’s the driver code which is usually responsible for initialization/returning the results and is run sequentially. Node code on the other hand is run in parallel on worker nodes and is responsible for data transformations on RDDs.
Getting our hands dirty
Now, having the basic understanding, let’s figure out how to use it in practice.
Defining the problem
All solutions start with a problem. Here’s one for us.
Based on git commit history suggest who could have said the given phrase or word. We would like to keep the search fuzzy, that is it should allow typos and match similar words. We won’t make it a predictive model. Instead we will care only about data we already have.
Our app will be called “Who Said That?”.
The purpose of this post is to introduce Spark so our solution will be rather naive and we won’t try to come up with some groundbreaking algorithms. Written text analysis is a vast topic, far bigger than a blog post or even a book and I’m not an expert to take on this subject.
Getting the data
Before we can do any processing we first need to get the data. In our case it’s quite simple:
git log >> git_log.txtAs often the more data we can get the better, so let’s combine data from many git repositories.
Analyze the information
Let’s take a look at what we’ve got and search for patterns to exploit.
A typical dataset from git will look something like this:
commit 1dcd5698da59c1d3ff8bdaefccef7fba3f3d6fca
Author: mr x <x@example.com>
Date: Thu Jan 28 12:22:52 2016 +0100
I did this
I did thatWhat we will need to extract is the author information and the commit messages. Then we will have to combine authors and messages. Fair enough.
Inspecting the data we can see also other patterns:
- some words are more common than other: like
feature,bug,ticket,merge,fix… - even unique, valuable commit messages are repeated in the source, for instance by merge commits
- sometimes authors use different machines/users to commit their code, we could merge those authors together
- blog repo history is dominated by few people doing bulk of maintenance work while pushing a lot commits, authors usually send just the main text in one commit and then few patches – this might skew our model towards “heavy commiters”
This kind of inspection can bring some valuable insights into the data at hand and make our work simpler. We will try to bake some of them into our simplified model.
Cleaning the data and building the relations
Knowing what we want to do and what data we have at our disposal, let’s start hacking.
First, let us add Spark to our app – modify build.sbt:
https://gist.github.com/pjazdzewski1990/31daed0d2bb468da2270
Then add boilerplate for our app:
https://gist.github.com/pjazdzewski1990/c153cfd815acd4f5b987
Before moving forward let’s explain what’s going on here. First, we create a SparkConf instance. It will hold … configuration for our Spark app. No surprise here. We will resort to defaults. Thing to notice here is setMaster. This method sets to what cluster we would like to submit our job. In our case we will work in memory on two threads.
The rest is straightforward – we feed the configuration into SparkContextwhich is the entry point for all Spark related functionality. When done, we close the context.
Let’s start with reading the data into the system and cleaning it up.
https://gist.github.com/pjazdzewski1990/fb5aec567845895e4510
https://gist.github.com/pjazdzewski1990/1f68813ea7d35808eaf5
As I said before – SparkContext is the entry point for Spark code and it’s the same in this case.
We start the processing with reading our data source (git_log.txt file). The method returns a RDD[String] ready to be processed – using an API similar to Scala’s standard collection we filter out all rows that we don’t need and then apply a common format for them. As a result of cleanData method we have another RDD[String] this time pointing to cleaned data. All the cleaning was done in parallel on our (virtual) nodes.
Note: I’ll be using the whole dataset to build the model. In real predictive models you would probably want to do some sort of cross validation to make sure your approach generalizes well on unknown data. I won’t be doing it here as in this case recognizing historical data is more important than working with future data. I also don’t want to make it more complicated that it has to be.
Building our first model
Single cleaned lines aren’t much useful if we don’t aggregate them by author. We have to do that first.
We need to go through the data and on every found author row, assign the following rows to him until we stumble on another author.
It leads to a problem. Our current dataset is an RDD[String] which means we don’t really control how the data will be spread across nodes. Counting them on nodes might lead to incorrect partial results.
The simplest way to fix it is to load the results into the driver and perform the partition of the whole set there. In order to do that we need to call collect()action, which transforms RDD[T] into an Array[T]. Actions are special operations on RDDs that trigger computations and allow us to get the resulting data.
https://gist.github.com/pjazdzewski1990/0131efac6c9d7c60a4d0
https://gist.github.com/pjazdzewski1990/62aaeaf1ddace32ba744
groupData is not being run in parallel. We sacrificed it for correctness and simplicity. Which doesn’t mean we won’t be working in parallel later on.
Having the raw data in place we can start building a model.
Building and evaluating will require that we perform many computations, so it would be useful to run them in parallel. The previous step was fully sequential, but it doesn’t mean we cannot build new RDDs from our “sequential” data. SparkContext can parallelize any sequence and it’s simple as this:
https://gist.github.com/pjazdzewski1990/3d20f4700a809dded026
Having a new RDD in place we compute similarity score.
https://gist.github.com/pjazdzewski1990/10b4c9c0ebe15b791e03
https://gist.github.com/pjazdzewski1990/f593d80194e2e665b253
The code above is rather straightforward. We transform our RDDs from sentences into words and compare each of them with our target words. We sum the scores and get all the matching words. The last step is to sort the RDD content by the score.
For starters our scoreSimilarity won’t detect partial matches, but it should be enough to gather some feedback on the algorithm.
https://gist.github.com/pjazdzewski1990/a12589745b8797402c61
Getting feedback on the model and refining it
Now it’s time for the feedback loop. I’ve been testing our model with a simple suite of some expected results. We managed to get some tests green, but there are still some problems.
First of all it doesn’t meet our conditions: matches aren’t fuzzy and for common words heavy commiters are promoted. We need to do something with it.
Let’s start with revamping our scoreSimilarity function. We will count similarity in a basic way – find a possible common prefix and count matching words. We would like to keep the result between 0 and 1, so long and short words give same scores. We also tweaked how the final score is calculated.
https://gist.github.com/pjazdzewski1990/b495b335a22c527a7ae7
This one helps us with words pairs like warn/warning, fix/fixing and so on. Now let’s modify the rest of the code to choose accuracy over lots of data.
Let’s modify findSimilar
https://gist.github.com/pjazdzewski1990/fdf1983346141132427c
This approach, although still basic, makes our test suite pass. There are still other optimizations to implement, but I will leave it as a task for the curious …
Summary
As you can see Apache Spark is a powerful and flexible library, backed with a simple concept. It’s empowering to see how difficult problems can be solved with ease using Spark. I hope you liked this post and you are ready to try Spark out.
Thanks for reading.
Links
Do you like this post? Want to stay updated? Follow us on Twitter or subscribe to our Feed.

Authors
I'm a software consultant always looking for a problem to solve. Although I focus on Scala and related technologies at the moment, during the last few years I also got my hands dirty working on Android and JavaScript apps. My goal is to solve a problem and learn something from it. While working with teams I follow "The Boy Scout" Rule - "Always check a module in a cleaner state than when you checked it out". I think this rule is so good, that I extend it also to other aspects of software development - I try to improve communication patterns, processes and practices ... and all the things that might seem non-technical but are vital to success.
Popular Posts in category
Looking into Scala.js

Your first microservices using Scala and Lagom
Handling Split Brain scenarios with Akka



