

ZIO SQL: Type-safe SQL for ZIO applications
This article was inspired by a great blog post by Adam Warski, who wrote a comparison of Slick, Doobie, Quill and ScalikeJDBC a few years ago. As ZIO SQL just had its first non-production release, I wanted to add ZIO SQL to the mix and see how it compares to others. Therefore, in the Tour of ZIO SQL section, I have used the same examples as Adam did, so it’s easier for readers to compare the libraries. However, I won’t spend too much time covering the other libraries, we’ll just make a quick review of how queries are constructed in each of them. You can find code snippets for this blog in my fork of Softwaremill’s original repo. (Updated 2/13/2022 for ZIO SQL 0.1.2 release that contains the new way of defining tables)
Introduction
When it comes to accessing relational data, Scala developers nowadays have lots of interesting choices. Slick, Doobie or Quill are all great, production ready, battle tested libraries that have survived the test of time. So do we even need another library? Does ZIO SQL offer something that others don’t? If you’re eager to find out what makes ZIO SQL special and see this library in action, keep reading.
Who is ZIO SQL for?
I find it interesting that every library takes a slightly different approach to solving the problem of accessing relational data. Especially when it comes to writing queries, users usually have to choose between these two options:
- Having a type-safe domain-specific language (DSL) which doesn’t much resemble SQL and therefore has a steeper learning curve.
- Having an ability to write SQL as
String, but at the cost of limited or no type-safety.
Now, let’s take a quick look at some of the most frequent choices and quickly explore their approach to writing queries.
Slick
Slick lets you define a meta-model for your table. Using values representing your table and methods representing columns, you can use Slick’s DSL, which feels quite intuitive for simple examples.
class Persons(tag: Tag) extends Table[(UUID, String, Int)](tag, "persons"){
def id = column[UUID]("id", O.PrimaryKey)
def name = column[String]("name")
def age = column[Int]("age")
def * = (id, name, age)
}
val persons = TableQuery[Persons]
( for( p <- persons; if p.age > 18 ) yield p.name )
//or
persons.filter(_.age > 18).map(_.name)In general, writing queries in Slick resembles working with Scala collections, rather than working with SQL. However, queries are typesafe. Using String when comparing age would result in compile type errors.
In more complex examples, such as when you join multiple tables, users have to deal with nested tuples and using the DSL gets a little bit more complicated. The good news is that you can also write a query in Slick as a raw String.
sql"SELECT name FROM persons WHERE age < 18".as[String]Obviously, in this case you’re losing type safety as Slick doesn’t use any macros to parse String or anything like that. If you misspell SELECT or map the result to Int, your program will fail at runtime.
Doobie
Doobie doesn’t require writing any meta-model. It actually doesn’t abstract over SQL at all. With Doobie you write SQL directly and then you map to your model representation.
val age = 18
sql"""SELECT name FROM persons WHERE age > $age"""
.query[String]
.optionWhile writing String is just not typesafe, Doobie offers query type checking capabilities.
val y = transactor.yolo
import y._
val query: Query0[String] =
sql"""SELECT name FROM persons WHERE age > 18"""
.query[String]
query.check.runSyncUnsafe()You can incorporate this check, for example, into your unit tests. Output of check lets you know if you made a syntax typo. It also gives you recommendations about the model representation which you map your query to, like a nullable column mapped to a non-optional type, unused column, type mismatch and more. Anyway, this is not a compile type query checking, as it’s happening at runtime, but it’s still a nice feature.
Quill
Quill generates a query at compile time. Let’s take a look at an example of how we can write our query of adults.
final case class Person(id: UUID, name: String, age: Int)
ctx.run(
quote {
query[Person].filter(_ > 18).map(_.name)
}
)When you hover over your query description, you can see the actual SQL query that you’ll eventually end up executing on the database!
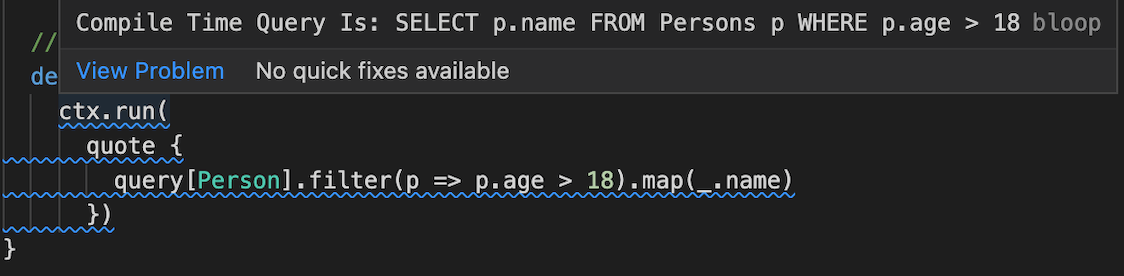
On the other hand, when it comes to this Quoted DSL, in my opinion, some getting used to is required and there isn’t much resemblance to SQL itself.
So what about ZIO SQL?
According to the website, it’s “Type-safe, composable SQL for ZIO applications”.
Indeed, the goal of ZIO SQL is to bring you the best of both worlds. It lets you write type-safe and composable SQL queries in ordinary Scala.
case class Person(uuid: UUID, name: String, age: Int)
implicit val personSchema = zio.schema.DeriveSchema.gen[Person]
val persons = defineTable[Person]
val (uuid, name, age) = persons.columns
select(name).from(persons).where(age > 18)For now let’s just focus on a query on the last line – don’t worry, we will get to describing the table schema later. This query very much resembles SQL itself and it’s also type-safe. Trying to select columns from some other table results in a compile time error. Also, query typos are impossible, as you are using Scala functions.
There are four databases currently supported: PostgreSQL, MySQL, MSSQL Server, Oracle – with PostgreSQL being the most feature-complete out of the four. Support for more databases is coming in the future.
How does ZIO JDBC fit into the picture?
ZIO JDBC is a new library that has just recently started to be developed so it’s a lower-level library than ZIO SQL. Let’s take a look at an example.
val query = sql"select name from persons where age > 18".as[String]
val select: ZIO[ZConnectionPool, Throwable, Chunk[String]] = transaction {
selectAll(query)
}We’re back in the world of writing String. In fact, you can use ZIO SQL to describe your query and render it to the String. So in the end, ZIO SQL and ZIO JDBC could cooperate. At the moment, one of the modules of ZIO SQL is the JDBC module which could in the future be replaced by ZIO JDBC. So users could use ZIO SQL for its typesafe, sql-looking DSL and ZIO JDBC for connection pool, transactions and other JDBC related stuff. And again, if you’re dealing with some unusual, not yet supported, db specific query, with ZIO JDBC you can execute it directly as a String.
Tour of ZIO SQL
Now that we know whether ZIO SQL is interesting for us or not, let’s do a tour of the library and see it in action.
Define meta model.
We’ll be working with 3 tables representing a city, its metro system and a specific metro line.
Before we can start using DSL, we need to describe our tables and extract columns, which we’ll then use when constructing queries. For table descriptions, we’ll use just simple case classes.
import zio.schema.DeriveSchema
case class City(id: Int, name: String, population: Int, area: Float, link: Option[String])
implicit val citySchema = DeriveSchema.gen[City]
case class MetroSystem(id: Int, cityId: Int, name: String, dailyRidership: Int)
implicit val metroSystemSchema = DeriveSchema.gen[MetroSystem]
case class MetroLine(id: Int, systemId: Int, name: String, stationCount: Int, trackType: Int)
implicit val metroLineSchema = DeriveSchema.gen[MetroLine]Case classes are great at describing table structure. Each field of a case class represents one database column. Field name is a column name, field type is a column type and name of a case class is turned into snake case and used as a table name. We can also express nullability of a column with a simple Option. In order for ZIO SQL to be able to automatically create values representing table and columns, we need to also provide implicit schema for our case class. We can do that by calling DeriveSchema.gen[T] macro coming from ZIO SCHEMA library. Next, let’s extract actual tables and columns.
trait TableModel extends PostgresJdbcModule {
val city = defineTable[City]
val (cityId, cityName, population, area, link) = city.columns
val metroSystem = defineTable[MetroSystem]
val (metroSystemId, cityIdFk, metroSystemName, dailyRidership) = metroSystem.columns
val metroLine = defineTable[MetroLine]
val (metroLineId, systemId, metroLineName, stationCount, trackType) = metroLine.columns
}For each of our tables, we need to call defineTable[T] which gives us value representing the table and where T is our previously defined case class. We call columns method on a table value to get tuple of all the columns. Worth mentioning is also that defineTable method is overloaded with a variant that takes table name as a parameter defineTable[City]("cities"). We can also let the library do the smart pluralisation – based on English grammar rules – by calling defineTableSmart[City].
TableModel extends the PostgresModule which comes from zio.sql.postgresql.PostgresJdbcModule import. If you are using another database, you just need to extend an appropriate module – like e.g. OracleJdbcModule.
Architecturally ZIO SQL uses modules represented by traits. Core project defines an SqlModule which consists of SelectModule, InsertModule, TableModule and more. These contain database agnostic DSL. Built on top of that is a JdbcModule which adds the abilities to execute queries, render them to string, launch transactions and so on. Database specific functionality is then built into database specific modules which also take care of translating ADT into a String query.
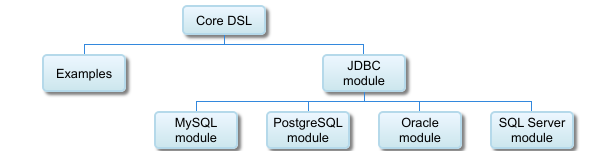
Value that describe table e.g. city has type Table.Source and values that describe table columns e.g. cityId or cityName have the type Expr[F, A, B] where B is a type of column, A is an abstract type representing the table and F is a phantom type which helps the compiler validate the DSL soundness. From now on, we will be using those Expr‘s inside our queries.
DB Connection
Let’s see how to connect to a database.
Execute method returns either a ZIO or a ZStream – depending on whether we are executing a streaming query or not – and sets the environment type to SqlDriver. That means that in order to execute a query, we need to provide SqlDriver to the ZIO program.
val query: ZStream[SqlDriver, Exception, String] =
execute(select(cityName).from(city))In order to construct SqlDriver we will need at least ConnectionPoolConfig where we set the connection URL, user, password and any other configuration if needed.
val poolConfigLayer =
ZLayer.scoped {
TestContainer
.postgres()
.map(a =>
ConnectionPoolConfig(
url = a.jdbcUrl,
properties = connProperties(a.username, a.password)
)
)
}
private def connProperties(user: String, password: String): Properties = {
val props = new Properties
props.setProperty("user", user)
props.setProperty("password", password)
props
}
val driverLayer = ZLayer.make[SqlDriver](
poolConfigLayer,
ConnectionPool.live,
SqlDriver.live
)As you can see, defining driverLayer is pretty straightforward. ZIO 2.0 introduces amazing improvements to the way we compose ZLayers. If you mess something up, the compiler will remind you what you are missing or what is redundant.
It’t also possible to use HikariCP as a custom ConnectionPool instead of the default from ZIO SQL. There’s jdbc-hikaricp module that introduces HikariConnectionPool and HikariConnectionPoolConfig which we need to provide to our driverLayer.
val poolConfigLayer =
ZLayer.scoped {
TestContainer
.postgres()
.map(a =>
HikariConnectionPoolConfig(
url = a.jdbcUrl,
userName = a.username, a.password
password = a.password
)
)
}
val driverLayer = ZLayer.make[SqlDriver](
poolConfigLayer,
HikariConnectionPool.live,
SqlDriver.live
)Simple query
Now that we have all the building blocks ready, let’s start writing some queries. First off, let’s write a query that selects only the big cities.
val bigCities = select(cityId ++ cityName ++ population ++ area ++ link)
.from(city)
.where(population > 4000000)So far so good. If you’re familiar with SQL in general, the query itself should feel very natural.
For the query, we’re using the Exprs that we defined earlier. Also, the query is completely type-safe, so if you try to select a column from some other table than city, you end up with a compile time error.
Lets execute our query now:
case class CityId(id: Int) extends AnyVal
case class City(id: CityId, name: String, population: Int, area: Float, link: Option[String])
val result: ZStream[Has[SqlDriver], Exception, (Int, String, Int, Float, String)] = execute(bigCities)
val bigCities2 = bigCities.to {
case (id, name, population, area, link) => City(CityId(id), name , population, area, Option(link))
}
val result2: ZStream[Has[SqlDriver], Exception, City] = execute(bigCities2)
result gives us a stream of rows, each one represented as a tuple. You can map over ZStream, run it to ZIO of a Chunk, get only the first element with runHead or do something else, like write elements to the console. Basically, after the query execution, you’re in the world of ZIO, so you get all the benefits of working with ZIO.
Alternatively, we can call query.to which maps type to our custom domain model. In our case, our model contains an Option as well as a newtype wrapper for ID, so we can do the mapping of column types to our model before query execution. Then, executing the query returns a stream of City.
Complex queries
An example of a more complex query consists of selecting metro systems with city names and a total count of the lines in each system, sorted by that count.
/**
SELECT ms.name, c.name, COUNT(ml.id) as line_count
FROM metro_line as ml
JOIN metro_system as ms on ml.system_id = ms.id
JOIN city AS c ON ms.city_id = c.id
GROUP BY ms.name, c.name
ORDER BY line_count DESC
*/
val lineCount = (Count(metroLineId) as "line_count")
val complexQuery = select(metroLineName ++ cityName ++ lineCount)
.from(metroLine
.join(metroSystem).on(metroSystemId === systemId)
.join(city).on(cityIdFk === cityId))
.groupBy(metroLineName, cityName)
.orderBy(Desc(lineCount))
val streamRow: ZStream[Has[SqlDriver], Exception, (String, String, Long)] = execute(complexQuery)
We extracted lineCount to a value and reused it inside select and inside orderBy clause. If we inline it, the query won’t change. I find it nice that the compilation fails when we don’t group by metroSystemName and cityName. After all, lineCount is an aggregation function, so grouping by other selected columns is required. After execution, we have a stream of flat tuples (String, String, Long) representing the name of the metro line, city and number of lines.
Dynamic queries
Our goal is to construct a query based on some runtime values, so let’s see how ZIO SQL handles it.
val base = select(metroLineId ++ systemId ++ metroLineName ++ stationCount ++ trackType).from(metroLine)
val minStations = Some(10)
val maxStations = None
val sortDesc = true
val whereExpr = List(
minStations.map(m => stationCount >= m),
maxStations.map(m => trackType <= m)
).flatten
.fold(Expr.literal(true))(_ && _)
val ord =
if (sortDesc)
stationCount.desc
else
stationCount.asc
val finalQuery = base.where(whereExpr).orderBy(ord)In this case, we are dealing with minimum and maximum number of stations that would form a where clause depending on whether they are available or not. Also, ord boolean value decides on final order direction. Values minStations, maxStations and sortDesc would be dynamic values coming from user input. We can see that we can easily compose multiple conditions inside where clause by folding over the List and applying && operator.
Plain SQL
ZIO SQL does not allow you to write queries as Strings. For that, you could use the ZIO JDBC that I mentioned before.
On the other hand, you don’t actually need a database connection in order to use ZIO SQL. You don’t even need ZIO. :) You can simply use the DSL to describe your query as pure data and then render it to a String. Depending on the query, you can use renderInsert, renderRead, renderUpdate or renderDelete methods.
val selectCityName: String = renderRead(select(cityName).from(city))The value of the selectCityName is SELECT city.name FROM city. Therefore, if you like, you can take this String and send it to the database some other way. Not using ZIO at all. This is a potential integration point for other libraries such as Slick, Doobie or ZIO JDBC. It’s also a way to debug your application and log ZIO SQL queries.
Transactions
When ti comes to writing transactions, each ZIO SQL query comes with a run method, which lifts query into transactional context. In other words, run introduces SqlTransaction into the environment type – similarly to how ZIO#withFinalizer adds Scope to the environment.
val transaction: ZIO[SqlTransaction,Exception,Int] = for {
_ <- insertCity(id).run
rows <- deleteCity(id).run
} yield (rows)
val deletedRows: ZIO[SqlDriver, Exception, Int] = transact(transaction)As we know, ZIO environment specifies which values your ZIO program requires, in order to be executable. We can satisfy SqlTransaction requirement by calling transact. The transaction is committed when the deletedRows succeeds and is rollbacked when deletedRows fails.
Type-safety and error reporting
While ZIO SQL heavily relies on type-level tricks, the most recent release also introduced <a href="https://docs.scala-lang.org/overviews/macros/overview.html">macros</a>. The main reason for that was to show nicer, more descriptive error messages. In the following example we want to count number of metro lines for each metro line name and city name.
select(metroLineName, cityName, Count(metroLineId))
.from(
metroLine
.join(metroSystem)
.on(metroSystemId === systemId)
.join(city)
.on(cityIdFk === cityId)
)
.groupBy(metroLineName)
.orderBy(Desc(Count(metroLineId)))However the query is not valid, because we forgot to call groupBy with a cityName column. Compilation of that code will indeed fail with following error message, which is very comprehensive for the end user, as this is the similar message to what the database client would generate.
Column(s) "cityName" must appear in the GROUP BY clause or be used in an aggregate function.Summary
ZIO SQL provides type-safe and composable DSL. Using it resembles writing SQL and compiler does query validation with nice readable error messages. The JDBC module adds ZIO integration, connection pool and transaction support to handle query execution and sql rendering.
While there’s still some room for improvements and work to be done before the library is ready for production, once a stable version is released, ZIO SQL will provide a great choice for ZIO based functional applications that need to work with relational databases in a type safe way.
ZIO SQL is the most Scalac-influenced ZIO library, with 2 top contributors and many more involved in the library.
Check out other articles on ZIO
- Functional Programming vs Object-Oriented Programming
- 7 ZIO experts share why they choose ZIO
- ZIO Test: What, Why, and How?
- Introduction to Programming with ZIO Functional Effects
- Mastering Modularity in ZIO with Zlayer
- How to learn ZIO? (And Functional Programming)
- Mastering Modularity in ZIO with Zlayer

Authors

I am a Scala developer passionate about Scala language, its expressivity and strong type system. I am big fan of ZIO, functional design techniques, type-safe DSLs and type-level programming in general. In my free time my hobbies are cycling, playing guitar and travelling with my wife.
Popular Posts in category

Looking into Scala.js

Your first microservices using Scala and Lagom
Handling Split Brain scenarios with Akka



