

What is HTTP protocol? Introduction to HTTP for Testers
If you’re testing web apps then you need to know what the purpose of HTTP protocol is and how it works. Actually, in my first project I lacked this knowledge. However, since then I’ve realised how important it is and that’s the reason I want to share it with you. In this article I will show you the basics of HTTP protocol. For example, how the BE (back-end) and FE (front-end) communicate, where you can see the data and how you can use this knowledge to add extra information to your bug tickets.
Hopefully, with a little practice, you’ll be able to determine where the error lies (BE or FE). Which is something your developers will thank you for. So without further ado – let’s get started!
What is the purpose of HTTP protocol?
HTTP stands for HyperText Transfer Protocol. HTTP is responsible for how the browser (client) communicates with the server. It precisely defines the communication format between them. Modern browsers commonly use this protocol. For example, to read this article your browser is using HTTP as well.
But HTTP is not the only protocol used to communicate between client-server. There are a lot more. In the OSI model, a conceptual model of how information moves around the web, the HTTP protocol is on the last layer – the application layer.

7 layers of osi model
However, in this article, I’ll be skipping the other protocols and layers of the OSI model, as it’s too vague a topic. Nevertheless, it is worth knowing where the HTTP lies in this model.
The key thing to mention is that HTTP is a stateless protocol. This means that the server and the client don’t store information about any previous requests made to them. Therefore, every request needs to have all of the required information.
You’ve probably heard a lot about cookies. It’s through these that you can avoid HTTP being stateless. But we’ll be talking more about how cookies work later in the article.
How HTTP protocol works
Basically, communication between a client and server is based on an HTTP request and an HTTP response.
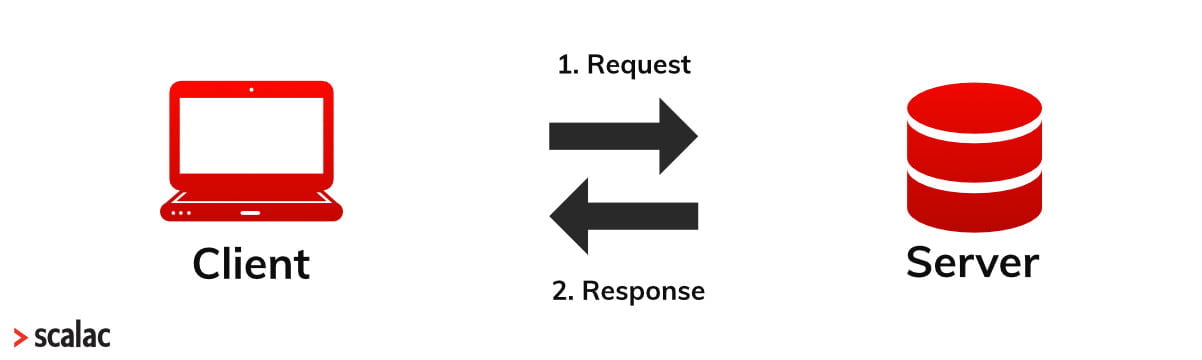
http protocol http request http response
Firstly, the client sends a request to the server – for example give me resource x. Then the server sends a response to the client – here is the resource x you demanded. But if you want to see any web page, there won’t be just one request and one response. There will be a lot of them. Because every request is associated with a specific resource.
For example, to show the main page of Scalac (www.scalac.io) the client (my browser) made 83 requests to the server.
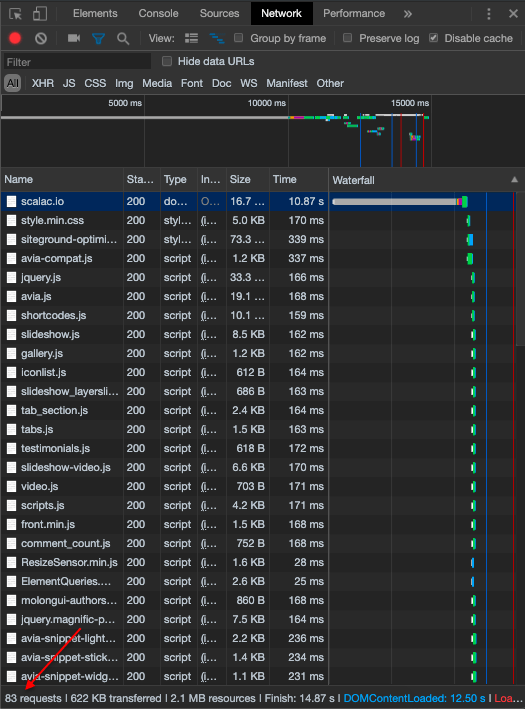
As you can see, every row is a request for a resource. You can check this for yourself on any web page. If you’re using Windows, open your browser and press the F12 key. On Mac press cmd+alt+i. Then go to the network tab and open any website.
A resource could be an HTML page, CSS file, font, picture or file with a JavaScript code.
HTTP headers
To each request, the client attaches HTTP headers. The server also does the same to each response. Headers are used to send metadata about resources.
Headers take the form:
header-name: header-value
In the table below, I’ve put the most common headers you’ll meet and what they mean.
| Header | Description | Example |
| Accept | In the request, the client can say what response format he accepts. | Accept: application/json |
| Content-type | Determines what type of data is sent. | Content-type: application/xml |
| Host | Informs the server which domain we want to send the request to. | Host: www.somewebsite.com |
| Server | The server informs clients what software they use to handle the response | Server: nginx |
| User-agent | Informs what client was used to send the request. | User-Agent: Mozilla/5.0 |
| Cache-control | This header is used to manage the cache process. | Cache-control: no-cache |
| Cookie | In this header, the client sends cookies to the server. | Cookie: cookie-name=cookie-value |
| Set-cookie | In this header, the server sends cookies to the client. | Set-cookie: cookie-name=cookie-value |
What is cache?
Cache is a mechanism that allows web pages to load faster. Some of the resources are stored in your browser memory. And this memory is called cache. Below is an example of how it works.
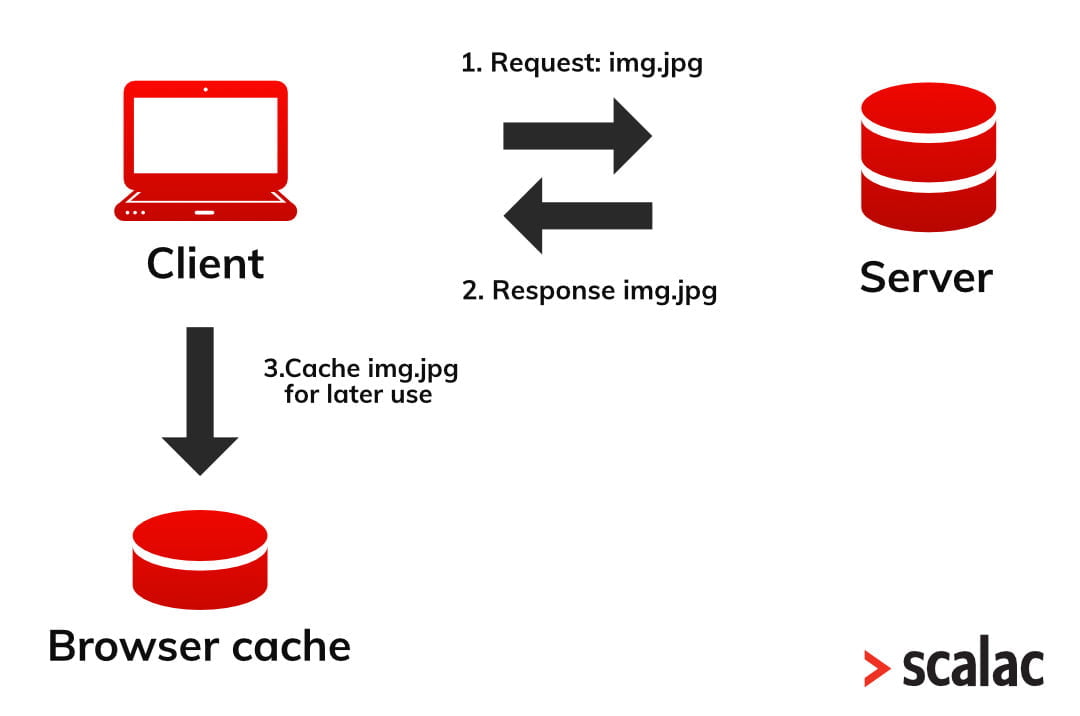
Your browser needs img.jpg to display any image on a web page. So your browser first has to request it from the server, and the server responds with the resource. This is where the role of the cache begins. The browser saves the img.jpg in the cache for later use. And when you visit this web page again, your browser won’t need to send a request to the server for the img.jpg resource. Because the browser will be able to just take the resource from its cache.
However, in order for the browser to cache any data, it must be programmed in the code, or it won’t know by itself what to cache.
Here’s a request to www.scalac.io with caching disabled.
![]()
Here’s a request to www.scalac.io with caching enabled.
![]()
As you can see, with the cache enabled, there are 9 fewer requests and the page loads 2.35s faster.
You can enable or disable the cache in the developer tools. But it will work only with developer tools open.

Remember!
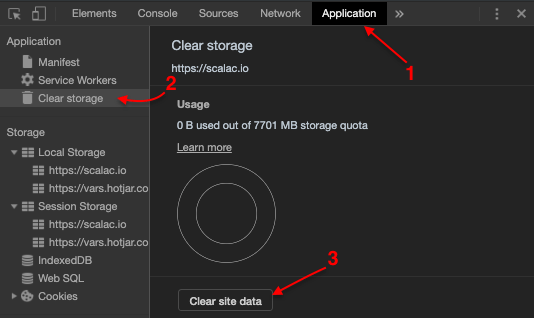
If your developer deploys new features or bug fixes in a test environment, it’s good practice to clear all of the cache in your browser before testing it. This is because a bug can still appear or a new feature may be invisible to you. Of course, another solution is to test in incognito mode. Personally,I prefer the first solution.
Below is an image on how to clear the cache in developer tools.
How cookies work
As I mentioned before, HTTP is a stateless protocol. But cookies are a workaround to this problem.
Using cookies, a server can bind a client request into one package. However, cookies should contain only public information because they can be stored in the browser memory for a very long time.
Let’s assume you log into your account and tick the remember me checkbox. The server sends a header (set-cookie: cookie-value) to your browser in response, with a cookie. The cookie is assigned to a specific domain. This means the next time you visit this page, your browser will send a request to this domain with a cookie (cookie: cookie-value). The server will then authorize you based on this cookie.
Why you need to know these 4 HTTP methods
HTTP methods help to distinguish requests made to the server. This is so we know what actions have been performed on the resource. Here are the most common methods, equivalent to CRUD (Create, Read, Update, Delete) actions. Actually, there are more methods in the HTTP protocol, but you won’t have to deal with them too often. The key is to remember just these four:
| HTTP method | Description |
| GET | the GET method is a basic request. Responsible for displaying the current representation of the resource. For example, the HTTP GET method is used to display web pages or forms. Parameters are passed in a URL address. So everybody can see them. That’s why GET should only be used to display, not to save sensitive data. |
| POST | the POST method is used when you want to add new resources. For example, creating a new account or sending files. Parameters are passed in the body. The POST method is safer than GET and should be used to send sensitive data. |
| PUT | the PUT method is used when you want to update existing resource. For example you want to change an email in your existing account. |
| DELETE | the DELETE method is responsible for deleting resources. For example, you can delete your account. |
The 5 main groups of HTTP statuses
An HTTP status is attached to every response. Basically, the status tells us whether the request has been successful or not. Statuses are made up of 3 numbers. I’m sure you’ve already seen some codes, such as 404 – not found, and 500 – internal server error. There are a lot of different status codes but we can split them into 5 groups. Here are some of the most common statuses:
| HTTP status groups | Description | Example |
| 1xx | These are informational codes. They are very rare. In fact, I haven’t come across any yet. | 101 – Switching protocols |
| 2xx | Request has been processed successfully. | 200 – OK
201 – Created 204 – Not content |
| 3xx | Redirection codes. This means the request should be directed to another address or server. For example, if Scalac changes address and you type this old one in the URL, you should see a code from the 3xx group | 301 – Moved permanently |
| 4xx | Client error codes. These appear when the problem lies on the client side. For example, you are not authorized to request the resource or you have made a typo in the URL and the resource doesn’t exist. | 400 – Bad request
401 – Unauthorized 403 – Forbidden 404 – Not found |
| 5xx | Server error codes. These codes are a serious problem. Because this can mean something is wrong with the server and it can’t process the request from the client. | 500 – Internal server error
502 – Bad gateway 503 – Service unavailable |
If you are interested in other HTTP status codes, you can see all of them with their meanings in Wikipedia.
HTTP tutorial: What is the role of the HTTP protocol in the daily work of the Tester
In the video below, I’d like you to take a look at a case from the last project I worked on. Hopefully, you’ll find this a good example of how to use the knowledge from this article. I’d also like to show you what other information you can add to your ticket to really help your developers.
Summary
Phew! This has been a long article. But I’m sure you’ve learned a lot about HTTP. Basically, if you understand most of this article, then you can say you now know the HTTP protocol. Naturally, if you have any questions, please feel free to ask them in the comments below.
See also

Authors
I am an enthusiastic Software Tester with strong analytical skills. Currently, I'm fascinated by REST API and test automation in Python. I run a blog about software testing www.toniebug.pl. I am also an instructor on Udemy. In my free time, I like to meditate and read books about philosophy, psychology, and finances.
Popular Posts in category

Looking into Scala.js

Your first microservices using Scala and Lagom
Handling Split Brain scenarios with Akka



