

Improving Akka dispatchers
Introduction
In this article, we will take a closer look at the core of Akka in an attempt to improve its overall performance.
To begin with, we will provide a short overview of the Akka toolkit and the Actor system. Following that we will study the life cycle of a message in order to gain a better understanding of what makes the Akka’s actor implementation tick. We will continue with a brief review of one of the common types of Executor Services that are used in Akka, while exposing its implementation details.
This will allow us to identify the main performance bottlenecks that can hinder throughput of actor systems and to attempt to provide a solution, borrowing some well known techniques from high-performance concurrent programming.
As a conclusion, a custom implementation of an ExecutorService will be presented. All of this shall be supplemented with sufficient number of benchmarks in order to convince ourselves we are on the right track to better performance.
All of the code is available on GitHub and is work that will shortly be present in the official Akka release.
Brief look into Akka internals
Akka is a toolkit comprised of a set of libraries designed to facilitate the engineering of scalable, highly concurrent and resilient systems that can span processors cores and networks. Akka achieves most of that through hiding low level concurrency primitives such as locks, semaphores and other synchronization tools behind higher level abstractions.
Actors in a nutshell
The main idea that powers Akka is a concurrency programming paradigm called the Actor Model. This model was invented by Carl Hewitt and has gained popularity and recognition in modern day computing as a mean to address concurrent programming in an effective, less error prone fashion.
The model provides an abstraction that lets one think about their code in terms of communication patterns, powered by asynchronous message exchange. This enables developers to write code without the need to concern themselves with issues such as memory visibility or mutual exclusion.
To achieve that, however, there has been significant engineering effort carried out. Often times it is useful to know the basics of what lies beneath the abstraction in order to better understand when and how to use the toolkit.
Actors are entities which communicate through exchanging messages. They provide certain guarantees when it comes to their message driven communication, thereby allowing for abstracting away problems common in concurrent programming. To accomplish that actors have:
- A Mailbox (the queue where messages go).
- A Behavior (the state of the actor, internal variables etc.).
- Messages (pieces of data representing a signal, similar to method calls and their parameters).
- An Execution Context (the machinery that takes actors that have messages to process, schedules them and executes their message handling code).
Lifecycle of a message
As messages are the main facility through which the state of an actor is accessed it is useful to get a better understanding of how they actually flow through an actor system.
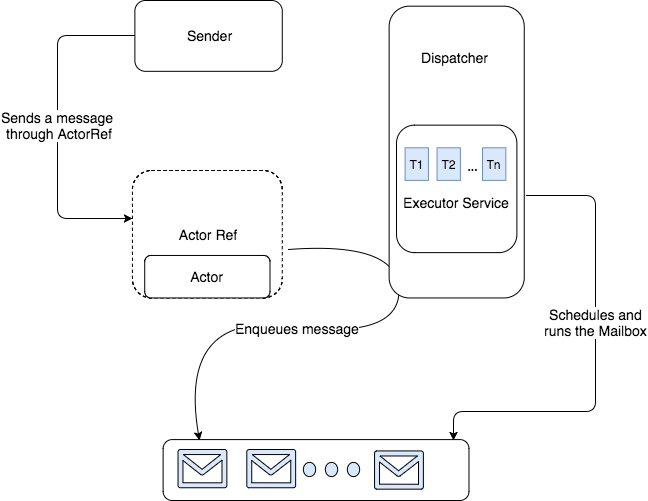
As it is apparent from the diagram, messages are sent to an actor through an ActorRef. A component called Dispatcher is responsible for placing the messages onto the actor’s Mailbox which is essentially backed by queue data structure.
The Dispatcher is again responsible for running the mailbox at a certain point. As the mailbox itself is an implementation of the Runnableinterface, it is simply scheduled onto the ExecutorService implementation backing up the Dispatcher.
At that point one of the available threads executes the run() method of the mailbox which simply dequeues the message and passes it through the message processing logic of the current actor. When we strip the details of delivery guarantees, message processing fairness and scheduling, all of this boils down to a Consumer-Producer problem backed by a pool of reusable threads.
Dispatchers
At the time of writing this blog post, there are three types of dispatchers one might use and they exhibit quite different characteristics:
- Default Dispatcher – an event-based dispatcher that binds a set of Actors to a thread pool. It is the default dispatcher used if one is not specified.
- Pinned Dispatcher – it will guarantee that each actor will have its own thread pool with only one thread in the pool.
- Calling Thread Dispatcher – runs invocations on the current thread only, which is useful in tests where concurrency needs to be eliminated in order to ensure full determinism. We are not going to go into the details of the configuration options for a Dispatcher as this is explained in the Akka docs.
One very important setting to take into consideration, however, is the throughput configuration parameter. It will become clear why this is important later in the article. For now, all you need to know is that this parameter defines the maximum number of messages to be processed per actor before the thread jumps to the next actor.
Default is set to 1 for maximum fairness. Setting the value higher minimizes thread context switches and will improves throughput. On the other hand, it might harm average actor latency as some actors will have to queue and wait for available CPU time.
Deeper look into thread pools
As already mentioned, a Dispatcher relies on a collection of threads in order to execute the message handling code. In theory any pool can be plugged in as long as it is implementing the ExecutorService interface. In practice, however, the two most often used implementations are the ones coming to Scala from Java:
ForkJoinPool– A thread pool implementation which relies on lock-free queues and work stealing. All threads in the pool attempt to find and execute tasks submitted to the pool and/or created by other active tasks (eventually blocking waiting for work if none exist). This enables efficient processing when most tasks spawn other subtasks (as do mostForkJoinTaskjobs), as well as when many small tasks are submitted to the pool from external clients.ThreadPoolExecutor– A thread pool which uses a shared thread safeLinkedBlockingQueueto store submitted tasks and relies on a configurable number of threads to process them. This pool is a typical example of a producer consumer pattern.
If we look closer at the ThreadPoolExecutor, which is often used when implementing separate blocking dispatchers, we can see that its internals are rather intuitive.
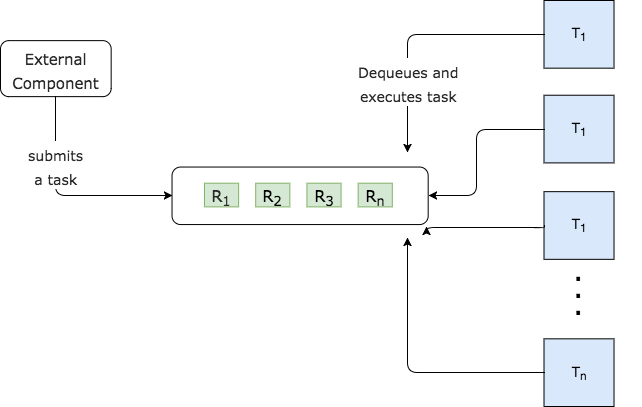
It maintains a set of threads which all wait on the shared queue, blocking until work is available.
Whenever a Runnable is dequeued by a thread, it is executed by this very same thread. There are no rules around the particular assignment of tasks to threads. That is, threads execute tasks on first come, first served basis. In order to ensure thread safety, the queue used in ThreadPoolExecutor is from the java.collections.concurrent. It guards its internal state through selective use of locks instead of relying on more sophisticated lock-free algorithms.
Main Bottlenecks of Current Implementation
After getting an idea of some of the basic implementation details behind the actor machinery of Akka, it is time to take a step back and think carefully about the parts of this architecture that can be performance bottlenecks.
For anyone who has worked in the field of concurrent programming and is familiar with the internals of the JVM as well as the architecture of our modern processors several main points of concern emerge.
- CPU cache invalidation – modern CPU performance can be vastly improved through minimizing cache ping-pong.
- Use of locks – the extensive use of synchronization can hinder performance severely.
- Thread contention – multiple threads accessing one shared resource leads to degraded performance.
We will take a look at each of these points and identify where they appear in the current solution as well as illustrate the powerful impact that alternative solutions can have on performance.
CPU cache invalidation
Modern CPUs are incredibly fast. As a matter of fact they are so fast in terms of instruction execution that most of the time the main bottleneck of a program lies within the rate at which data is delivered to the actual physical cores. In order to hide that latency modern processors employ a hierarchy of caches that differ significantly in terms of size, speed and purpose.
Most of the systems we run our programs on are shared-memory multi-processor ones. Such a system typically has a single memory resource (RAM) that is accessed by 2 or more independent cores. Latency to main memory can vary between 10s to 100s of nanoseconds. Just to put that in perspective, consider the fact that within 100ns it is possible for a 3.0GHz CPU to execute around 1200 instructions.
The various cache subsystems within our processors have been carefully engineered to hide that latency. Some of the caches are small and very fast and are serving a separate core. Others are much larger, slower and are shared among cores to facilitate their communication.
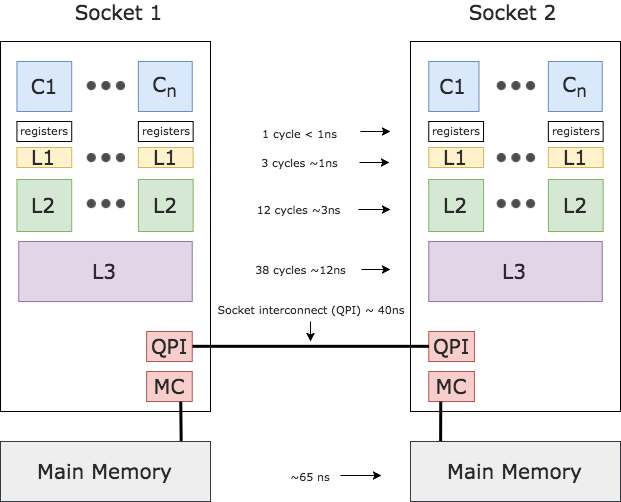
That being said, on a single socket system, a cache miss might cost you the opportunity to execute 500 instructions. We can double that on a multi socket system in cases where the memory request needs to cross the socket interconnect. Although most developers consider these details rather theoretical, the latter prove to be important in applications characterized by high level of concurrency (e.g. anything built on top of Akka).
If we have to bring all of that information a level higher in terms of abstraction we start thinking about threads and the JVM. Whenever a Runnable is supplied to an ExecutorService the former is executed on a thread. Under the hood our operating system’s thread scheduler tries quite hard to maintain something called affinity. That is the OS will attempt to execute the thread on the same core/socket it used to execute it in order to be able to reuse the data stored in the CPU caches.
For example, imagine we have a system that has two cores C1and C2 and we want to schedule one thread T. When the thread is ran on C1 its local data is loaded into the cache. Once the thread is scheduled again, it will be much better for that to happen on C1 rather than C2 in order to avoid the latency penalty of accessing main memory or the L3 cache. This is what the OS is taking care of.
We can follow the same logic at a higher level. That is, if our Runnable instances maintain some state, it is much better to attempt to always run them on the same thread rather than on a different one in order to avoid cache invalidation and subsequent load instructions.
Such data loading operations are often times triggered by memory fencing instructions such as a volatile read/write and are present event in cases when our state can completely fit in CPU caches.
In order to illustrate that better, lets look at a practical example and benchmark two distinct scenarios. Consider the following code. We have two chess rooks that are part of two different chess games. A rook is modeled by the class:
https://gist.github.com/anonymous/4198b24837421df3b7916c86c330699a
The more experienced eye might spot that calling the updatePositionmethod can exhibit a race condition. Do not concern yourself with that as it is not the main point here. In addition to that, we have a chess player class.
https://gist.github.com/anonymous/2f1236f431b114e714cd55f0fc381557
The job of the player is to update the position of the rook. We have designed a simple JMH benchmark in which we have two instances of the ChessPlayerclass and two of the Rook one. We then measure two distinct scenarios. In the first one we have professional chess players.
Each of them is playing two concurrent games, thereby updating one of the rooks and switching its attention to the other one. In the second scenario, we are simulating beginner chess players. Instead of playing two concurrent games, these guys prefer to focus exclusively on one rook. As a result of that what we end up with is two players, each updating one of the two rooks and not touching the other.
https://gist.github.com/anonymous/8d396dd847d207ce7ac3c1a5e05fe218
We then create an executor service and schedule two chess players. The end sum of both scenarios is the same – each rook is moved a certain amount of times. We benchmark the throughput that is achieved in both situations and present it in terms of moves per second.
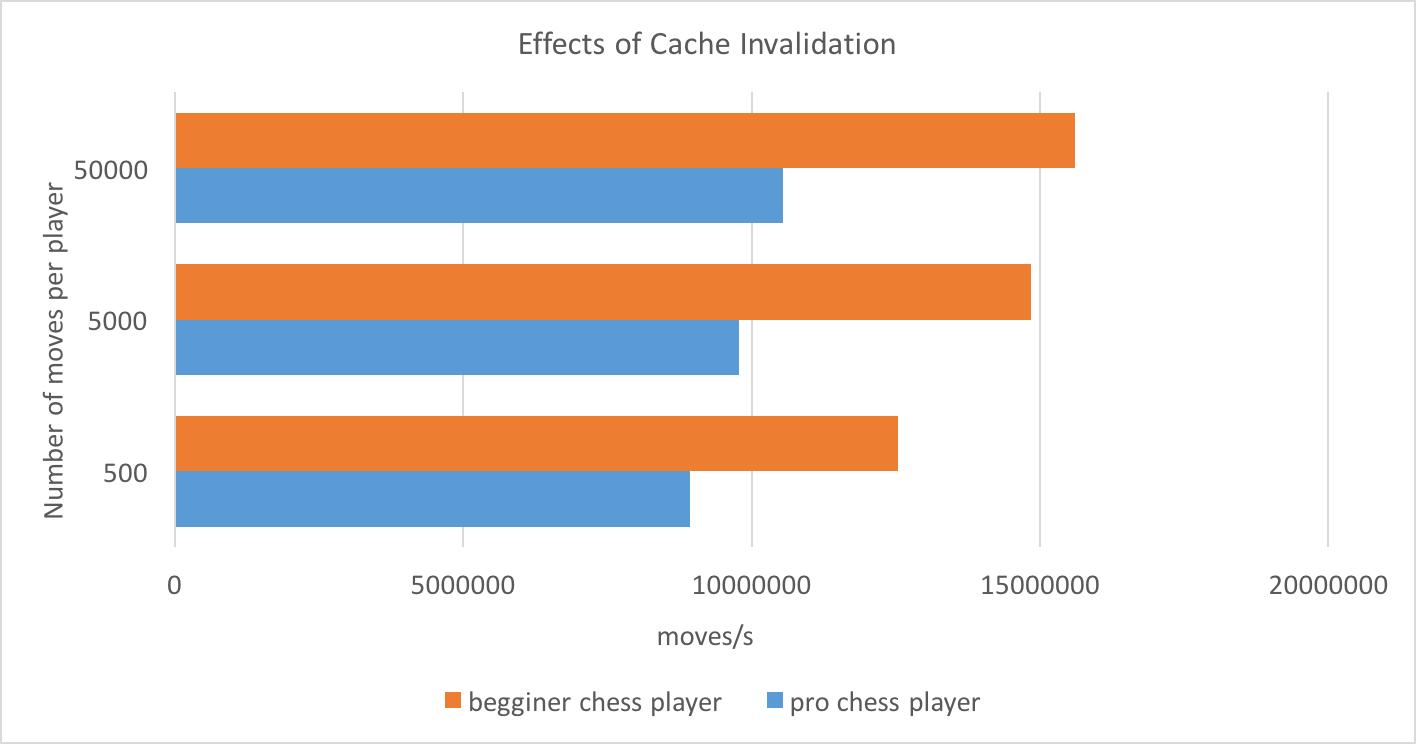
It is pretty clear that the beginner chess players surpass the professionals in terms of throughput of moves. The reason for that is rather simple. Each Rookobject maintains a state consisting of two volatile variables – xPos and yPos. Each beginner player is associated with a thread and only one rook. The player stays on that thread and deals with one rook until it executes all of its moves.
Furthermore this is the only thread touching the state of the rook that the player is focused on. The latter prevents unnecessary cache invalidation for the sake of keeping the volatile state coherent across threads.
In the situation where the professionals are executing the moves, however, the caches of the CPU are invalidated much more often due to the fact that two distinct threads are accessing data (rook’s positions) which needs to be flushed from core local CPU caches in order to be visible to other cores.
We can relate all of that to Akka Dispatchers as well. A Dispatcher is effectively backed by a thread pool while an actor mailbox is an implementation of Runnable. Whenever an actor gets scheduled by the dispatcher a thread from the pool picks that mailbox off the shared queue within the thread pool and runs it.
This, however, does not guarantee any actor to thread affinity as thread pool workers compete for work as in a classic producer-consumer fashion. As a result of that actors get executed on different threads depending on the runtime state of the system.
As actors are supposed to be stateful creatures by design (e.g. guarding state that is mutated through message exchange), it comes as no surprise that bouncing an actor from thread to thread results in quite a lot of load instructions to slower caches or main memory.
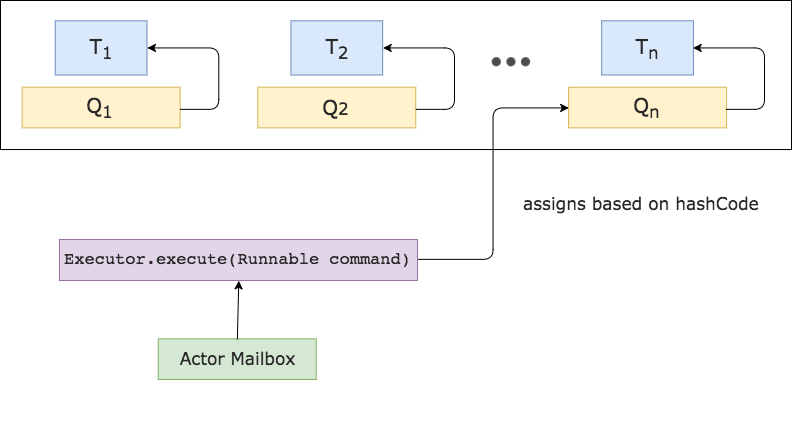
The way we avoid that in our proposed pool implementation is to create a separate queue for each thread. The queue onto which a Runnable is placed to await execution is determined by using the .hashCode of the Runnable. As already mentioned an actor’s mailbox is effectively a Runnable.
As each actor maintains a consistent mailbox, we can guarantee that every time an actor’s mailbox is scheduled (through being passed to the .execute method of the pool), it will be handled by the same thread it was handled the previous time it ran. This solves the problem of unnecessary cache invalidation and as already shown in our chess game example improves throughput significantly.
Use of locks
Most of the time people writing concurrent programs rely on synchronization techniques to guard state that is shared between threads. On the JVM this is often achieved through the use of the synchronized keyword. The effect of this is that access to a code block wrapped in synchronized is serialized.
That is, one thread needs to leave the critical section before another one can enter. Under the hood this is achieved through the use of the implicit lock of the object where the code resides. This provides us two things that are very important in concurrent programming:
- memory visibility – the guarantee that a change done by a thread will be observed by every other thread that enters the critical section of our program.
- atomicity – the notion that a complex action comprising of several operations appears as a single one that has either happened or has not.
These two things are incredibly important when it comes to writing correct concurrent programs. For example consider the following piece of code.
https://gist.github.com/anonymous/0e485cce0301724b0e3974e3fb0f1023
The absence of memory visibility guarantees in the code above can be quite problematic. If T1 and T2 both update the internal variable v, it is not guaranteed that even after T1 has finished executing the increment method T2 will see the changed state right away. This may lead to T2 acting on stale data and ultimately overwriting T1’s update.
https://gist.github.com/anonymous/f6fa825f3a5f37df0d6549c65e68abfa
One might think that simply making the variable volatile will solve the problem. To a certain extend that is true. The volatile keyword ensures CPU caches are kept coherent and forces memory visibility (albeit at the expense of performance).
The increment method is, however, still not atomic. Namely, if T1 begins to execute the method it first needs to load the current value of v, increment it and then store it. These are effectively three instructions. Suppose that T2 has started executing the same method and their instructions overlap. What can happen is T2 overriding T1 values, which is a typical example of a race condition – a common problem in concurrent programming.
The way to ensure that this does not happen is through the use of synchronized or through explicit locks. Unfortunately this has severe performance penalties that can be quite apparent in highly concurrent systems. It is well known that a mutex lock/unlock can take nearly 25ns – enough time for some CPU’s to process 300 instructions.
Because synchronization serves as a memory barrier, we need to add to that the effect of CPU cache invalidation. What we end up with is quite significant cost to pay in order to keep our code correct.
Fortunately substantial amount of research has been carried out on the use of lock-free concurrency primitives (such as Compare-And-Swap instructions) in the design of thread-safe data structures. Lets take a look at a simple example which illustrates the performance benefits that we can achieve when making use of such approaches.
https://gist.github.com/anonymous/5e4f6af12c0cb4b12a04657d8cc75e25
Above is an example of a LockBasedRook. Each time the updatePositionmethod is called the implicit object lock is acquired while the operation of updating the coordinates is being carried out. This ensures both memory visibility as well as atomicity. Moreover it serializes the attempts of threads to enter the critical section of code and forces them to queue and wait for the lock to be available for acquisition.
https://gist.github.com/anonymous/30f587ea9b250e9409aa01b5ebb4c093
Our LockFreeRook on the other hand utilizes a spinning CAS loop in order to update the coordinates and avoids acquiring, holding and releasing a lock. This is a much more lightweight way of ensuring that we have correct concurrent behavior as it relies on compound atomic operations built in the hardware itself.
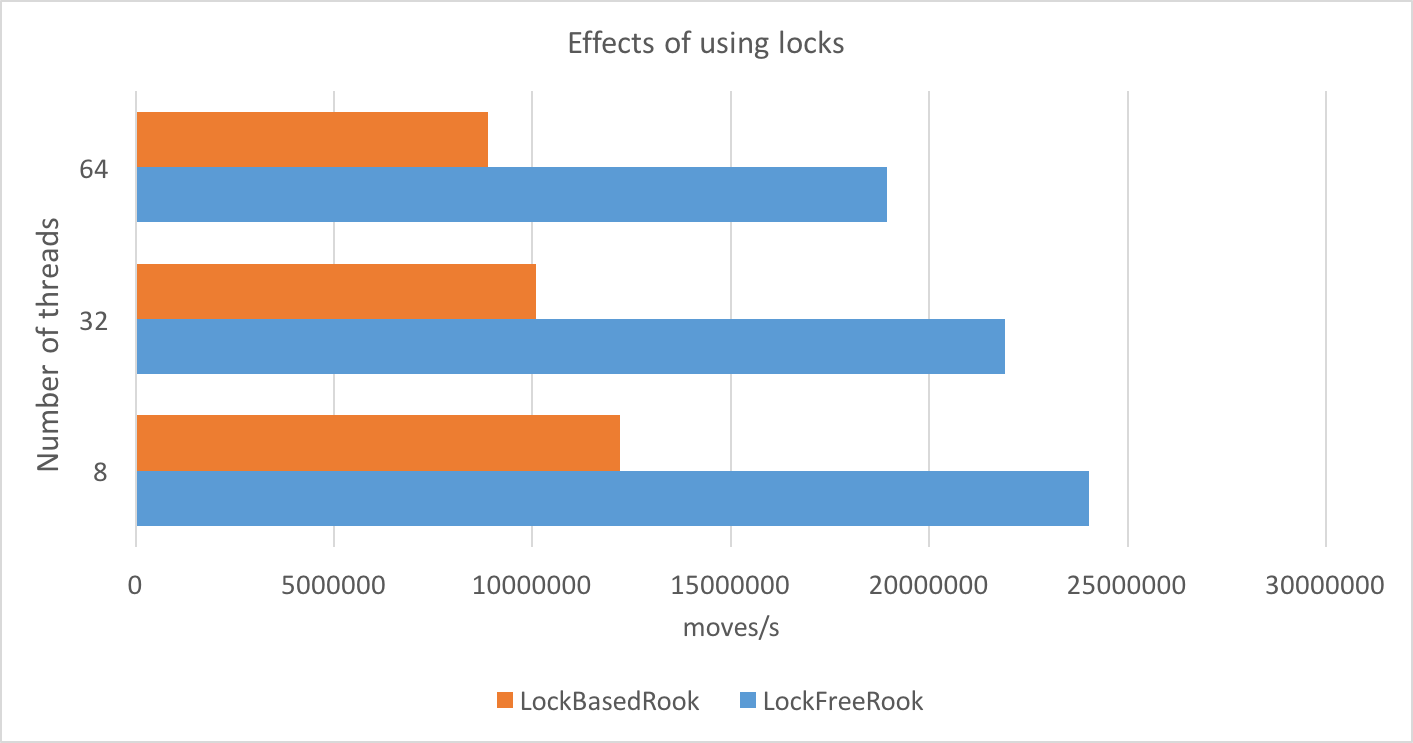
It can be seen from the benchmark results above that the lock-free implementation is superior in terms of performance compared to the lock based. This clearly shows the penalties brought by synchronization. Furthermore, it is obvious that as we increase the number of threads competing to acquire the lock we observe faster performance degradation.
If we have to bring that back into the realm of the ExecutorService, we see that ThreadPoolExecutor uses a LinkedBlockingQueue by default. This particular queue implementation is using (albeit quite selectively) locks in order to guard its shared state, causing threads to block and wait.
In contrast our proposed ExecutorService implementation uses a fast, lock-free multiple producer-single consumer queue which eliminates the use of locks and relies entirely on CAS primitives to achieve thread-safety. As a result of that we see almost double increase in throughput when comparing our executor to the default provided in the Java Standard Library.
Thread contention
Thread contention is something that can degrade performance as well. Irrespective of whether we are using locks or we rely on lock-free algorithms whenever two threads update a shared resource, we can observe performance penalties due to variety of reasons. Some of these reasons have already been discussed (cache invalidation) and others have not (CAS loop retry). The default ThreadPoolExecutor exhibits the following characteristics:
- shared queue – all threads within the pool operate on a shared queue which causes quite a lot of contention
- locks – additionally this queue is using locks internally so that further impedes performance.
Of course even when we get rid of the problems that locks bring, we can still see performance penalties due to contention. For example, let us consider the following piece of code.
https://gist.github.com/anonymous/1c65a73919e19d6a6f6f00ad766bef31
Our benchmark consists of a number of WorkProducer objects that produce WorkItem instances and push them onto a queue. We first measure the throughput in a scenario where the producers share a single queue and then compare that with the case where each producer has its own queue.
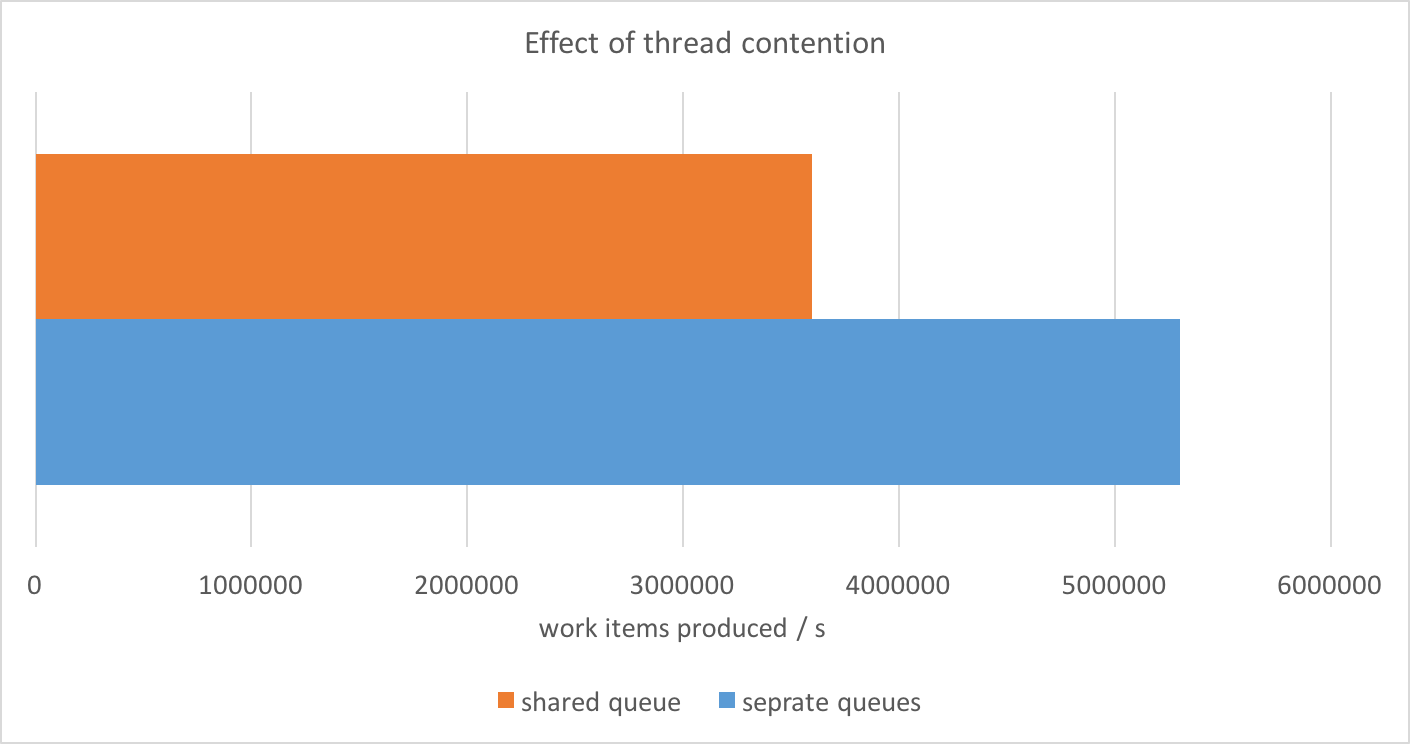
To eliminate the effects of locking, this benchmark uses the very same lock-free multiple producers-single consumer (MPSC) queue that is used in the thread pool implementation that we propose. With 32 producers, we can see that the striped (separate queues) version achieves much higher throughput compared to the shared queue one.
As already discussed, our alternative thread pool implementation relies on separate queues for each thread. This achieves two things. Firstly it is aimed at ensuring thread affinity (runnables are scheduled on the same thread they were scheduled before). Secondly it improves resource contention, thereby increasing throughput significantly.
The Affinity Pool
As a result of all of this work the AffinityPool was born. It is a high-performance, non-blocking ExecutorService implementation that utilizes lock-free, striped (per thread) queues as well as thread affinity in order to minimize contention and CPU cache misses. This results in significant throughput improvements compared to the most commonly used ThreadPoolExecutor and ForkJoinPool implementations.
It is supposed to be used in systems that maintain long-lived actors encapsulating frequently mutated state. Situations in which number of unique actors is less or equal number of cores are the ones in which the most impact on performance is seen.
This change has been proposed as a PR for Akka, has been merged in masterand shall hopefully be available in one of the coming releases. As with every high-performance system, it is essential that code is benchmarked and measured in order to determine the right configuration parameters for the AffinityPool accordingly.
Implementation Details
The AffinityPool maintains a set of threads that poll separate queues. Whenever a Runnable is passed to the execute method of the pool the queue onto which it should be put is determined according to its .hashCode.
There are two ways this can happen. In systems with lower number of unique actors, the pool determines Runnable placement via maintaining an atomic counter and a map which stores pairs in the form of runnable hash code -> index of work queue. The execute method first checks whether there is an entry in that table containing the hash code of the Runnable. If there is, the value is obtained and the exact queue is resolved.
The absence of such entry indicates that this is a Mailbox that the pool has not seen before. In that case we increment an atomic counter and obtain the index this way. The purpose of that is to ensure even distribution of work among threads without relying on the uniformity of the values produced by hashing algorithms. This is particularly useful when there are not a lot of unique actors and we aim to achieve maximum fairness in terms of work distribution.
https://gist.github.com/anonymous/a7c9191186d97303b737d9f8ac52a56c
As can be seen if the size of the recorded unique actor mailboxes is larger than the fairDistributionThreshold, we resort to a much faster implementation of the work distribution algorithm.
This is achieved by piping the hashCode of the Runnable through an sbhash function that improves the uniformity of the distribution. Given more unique actors, we can rely on the law of large numbers to ensure that we have somewhat even distribution of work while avoiding more expensive look-ups and updates of the map.
Important configuration options
As already mentioned, when designing a high-performance system, it is of essential importance to benchmark as much as possible. We have provided several important configuration parameters for the pool that can be tuned carefully after proper measurements have been taken.
task-queue-size– This value indicates the upper bound of the lock-free queue of each thread. Whenever an attempt to enqueue a task is made and the queue does not have capacity to accommodate the task, the rejection handler created by the factory specified in “rejection-handler-factory” is invoked.idle-cpu-level– Level of CPU time used, on a scale between 1 and 10, during backoff/idle. The trade-off is that to have low latency more CPU time must be used to be able to react quickly on incoming messages or send as fast as possible after backoff backpressure. Level 1 strongly prefer low CPU consumption over low latency. Level 10 strongly prefer low latency over low CPU consumptionfair-work-distribution-threshold– The value serves as a threshold which determines the point at which the pool switches from the map based to hash based work distribution scheme. For example, if the value is set to 128, the pool can observe up to 128 unique actors and schedule their mailboxes using the map based approach. Once this number is reached the pool switches to hash based task distribution mode.If the value is set to 0, the map based work distribution approach is disabled and only the hash based is used irrespective of the number of unique actors.
Comparison to default implementations
In order to determine the effects of combining all of these techniques in the AffinityPool, we designed a benchmark which aims to simulate a real life situation. This benchmark is used to compare the performance of our pool to the default ThreadPoolExecutor and ForkJoinPool options that come with Scala. For that purpose we created two actors.
https://gist.github.com/anonymous/96a4cb469274d4c161bb8650283bc7c7
The UserServiceActor maintains an in memory db of users while the UserQueryActor sends queries to the service actor and stores the results in a map that it maintains internally. We created 4 pairs consisting of one query and one service actors. The benchmark measures the exchange of 400000 queries between each pair and records the throughput at each iteration.
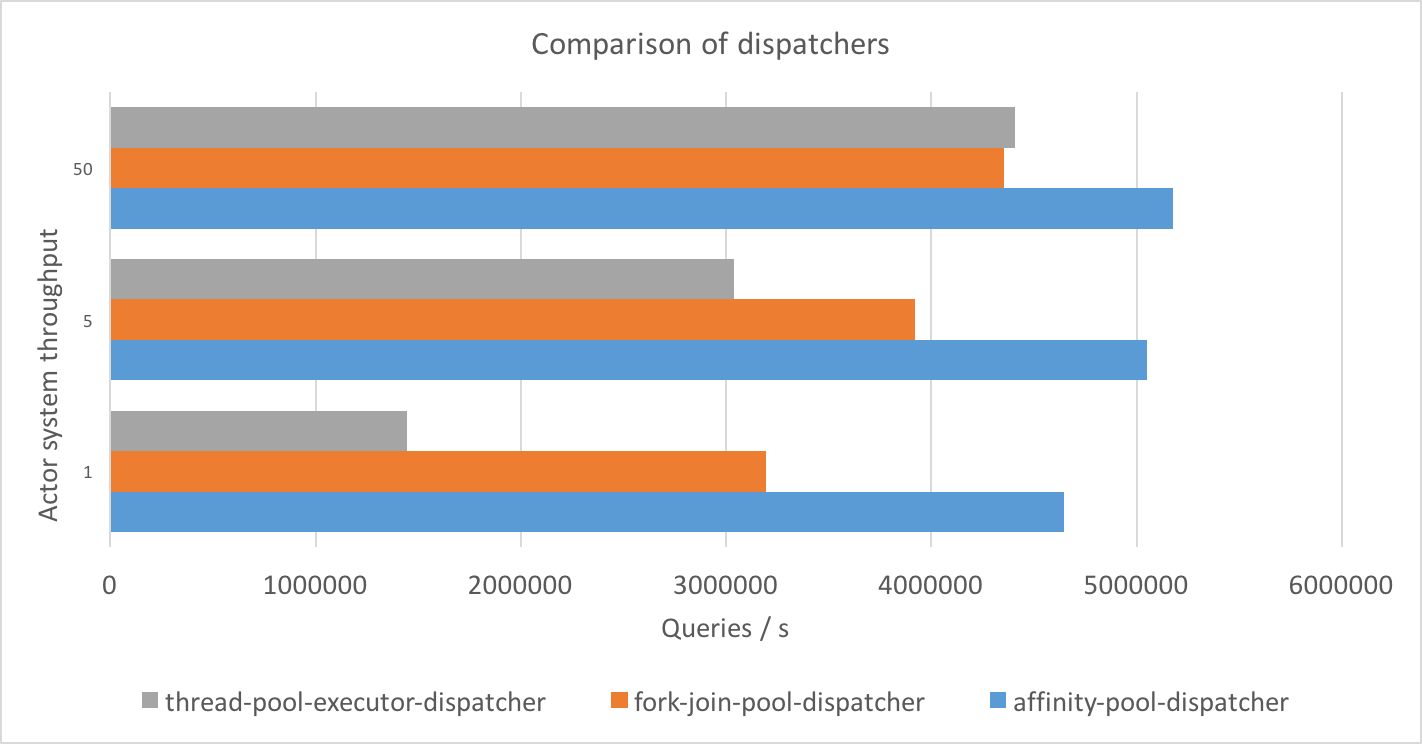
In addition to that we vary the throughput of the dispatcher. Throughput defines the number of messages that are processed in a batch before the thread is returned to the pool. The lower the throughput, the higher the fairness. Lower throughput, however, harms performance because of increased cache invalidation.
As evidenced by our benchmarks, this is much less of a problem for the AffinityPool as it uses actor to thread affinity. Overall, it can be seen pretty clearly that the performance of our proposed pool surpasses the other two that are commonly used.
Final Thoughts
Akka is a great toolkit for engineering highly concurrent systems and it is used worldwide by many successful organizations. Thankfully, it hides much of the low level nitty-gritty details that come whenever we delve into concurrent programming.
We have considered an affinity pool which aims to take Akka performance to the next level by utilizing some of the ideas that have been used for many years by high-performance system engineers. We would like to thank the Akka team for supporting this work with their recommendations and advice.
Links
- Dmitriy Vyukov’s non-intrusive MPSC queue
- Intel Sandy Bridge Architecture
- IBM’s paper on Lock-free Queues
- Configuring Akka Dispatchers
- Thread Pool Executor documentation
- Evaluating the costs of atomic operations on modern architectures
- Threads and Locks by Oracle
- Code from this article
- AffinityPool pull request on Akka’s repo
More on Akka
- User Authentication with Keycloak – Part 2: Akka HTTP backend
- Storing files on Amazon S3 with Alpakka AWS S3 connector
- Custom GraphStage in Akka Streams
- Introduction to Streams in Akka
- Handling Split Brain scenarios with Akka
See also

Authors
Popular Posts in category

Looking into Scala.js

Your first microservices using Scala and Lagom
Handling Split Brain scenarios with Akka



