

Custom GraphStage in Akka Streams
In this post I will try to present what is GraphStage in Akka Streams. My goal is to describe when it’s useful and how to use it correctly. I will start with outlining key terminology, then proceed with simple example and after that the main use case will be covered. For the latter the most upvoted issue of akka-http will serve.
At the end, I will show how to properly test GraphStage. Besides of learning API you’ll gain deeper understanding how backpressure works.
Basic terminology
When reading various materials about Akka Streams I see that common understanding of some terms are taken by granted. I think it’s not always the case, therefore I want to build up our terminology step by step. I just assume that you are already familiar with concepts of Flow, Source and Sink as they were explained in previous post.
Downstream and upstream
Let me explain downstream and upstream with the following graph:
https://gist.github.com/anonymous/191ed16cf45c3249eb6bad3af98fd3f2
Terms downstream and upstream are relative so you need to know what is your reference point. Let’s say we are talking about flow1 – then its upstreamis source while its downstream is flow2 and anything “on right hand side” of flow2.
Basically, it’s about direction in which data flows – places where messages are seen earlier are called upstream and places where they’re seen later are called downstream. That being said we can proceed to fundamental fact:
- Upstream may
completeoffaildownstream. When upstreamcompletesit means that it has no more data to send and by emitting such message informs about this fact its downstream. Conversely, when upstreamfailsit means that it was forced to abort its processing due to an error and propagates this error to its downstream. - Downstream may
cancelupstream. Cancellation means that downstream is no longer interested in incoming data and by emitting such cancellation asks upstream not to send more data.
ProcessingStage and Shape
ProcessingStage is a common name for all building blocks that build up a graph.
Shape is determined by number of inlets (input ports) and outlets(output ports). Besides of that it reveals nothing about processing semantics. Let’s take a look at two examplary shapes:
https://gist.github.com/anonymous/285f072b75f665cdf77323f42052cae3
Shape1 described above is called FlowShape. It has one inlet and one outlet. All Flows (e.g. map or filter) are of shape FlowShape. Shape in general may have arbitrary number of inlets and outlets, so the following one is an example of different Shape:
https://gist.github.com/anonymous/c0d5e54b4c49cb0c24496b5970d9d0c1
Shape2 from above has two inlets and one outlet.
What is GraphStage
You can think of GraphStage as an implementation block behind any ProcessingStage of RunnableGraph. Such broad definition implies that any Flow may be implemented as GraphStage. We will try to do that in next section.
Example of simple GraphStage
Let’s try to implement GraphStage responsible for filtering. Here’s a minimal code to have it done (full code with all imports and implicit may be found in accompanying repo for this and all following snippets):
https://gist.github.com/anonymous/26267382ee7cf4e5e1e2b5f4a4cd917d
Above implementation may be run with such code (full code):
https://gist.github.com/anonymous/8d774070008eea5c08aca84bdb9e3cb1
OK, you pasted some code, it works as expected, now let’s analyze how we actually achieved that.
GraphStage API
Implementing GraphStage boils down to implementing two methods. The first one is:
def shape: S <: Shape– each element of execution graph is of definedShape.
Another method is:
def createLogic(inheritedAttributes: Attributes): GraphStageLogic
Here we implement the logic of GraphStage. You should put all state variables within GraphStageLogic as this is the only part that is not reused between different materializations of stream. Our simple FilterStage is stateless – its processing logic depend solely on input elements. Therefore all we see in its GraphStageLogic are two calls of setHandler.
There are 2 types of handlers:
InHandler
Handler for inlets. You have to implement one method: def onPush(): Unit. There are other methods you may override, but let’s ignore them for a while. onPush is called when new element has been received on inlet. Usually implemented in terms of grab and push. grab(inlet) returns element recently pushed to inlet. push(el, outlet) pushes element to given outlet.
OutHandler
Handler for outlets. You have to implement one method: def onPull(): Unit. There is another method you may override, but we’ll leave it out for a while. onPull is called when demand for element has been signalled for this outlet. Usually implemented in terms of pull which allows to propagate demand upstream.
All inlets and outlets may be represented as Final State Machines. Consequently some operations are not valid in some states. When you call operation which is invalid for current state an exception will be thrown.
More information about it and detailed FMS diagrams may be found at Port states section of Akka documentation. To understand why API looks like this and consequently to be able to use it in a correct way we need to think about its relation to backpressure.
Backpressure
Excerpted from Akka documentation:
Backpressure, in general, is a method where a consumer is able to regulate the rate of incoming data from a corresponding producer.
It nicely sums up the ultimate goal of backpressure. Such statement also suggest that consumer needs to have some mean to “regulate the rate of incoming data”. It can does so by sending control messages up to the producer by special channel. Now you should start to feel why API needs to have onPulland pull methods.
Those methods refer not to data elements themselves but to this special channel that is used to propagate demand up to producer. Therefore we can say that demand flows from downstream to upstream as opposed to data which flows from upstream to downstream. It can be illustrated as a diagram (taken from akka docs, original):
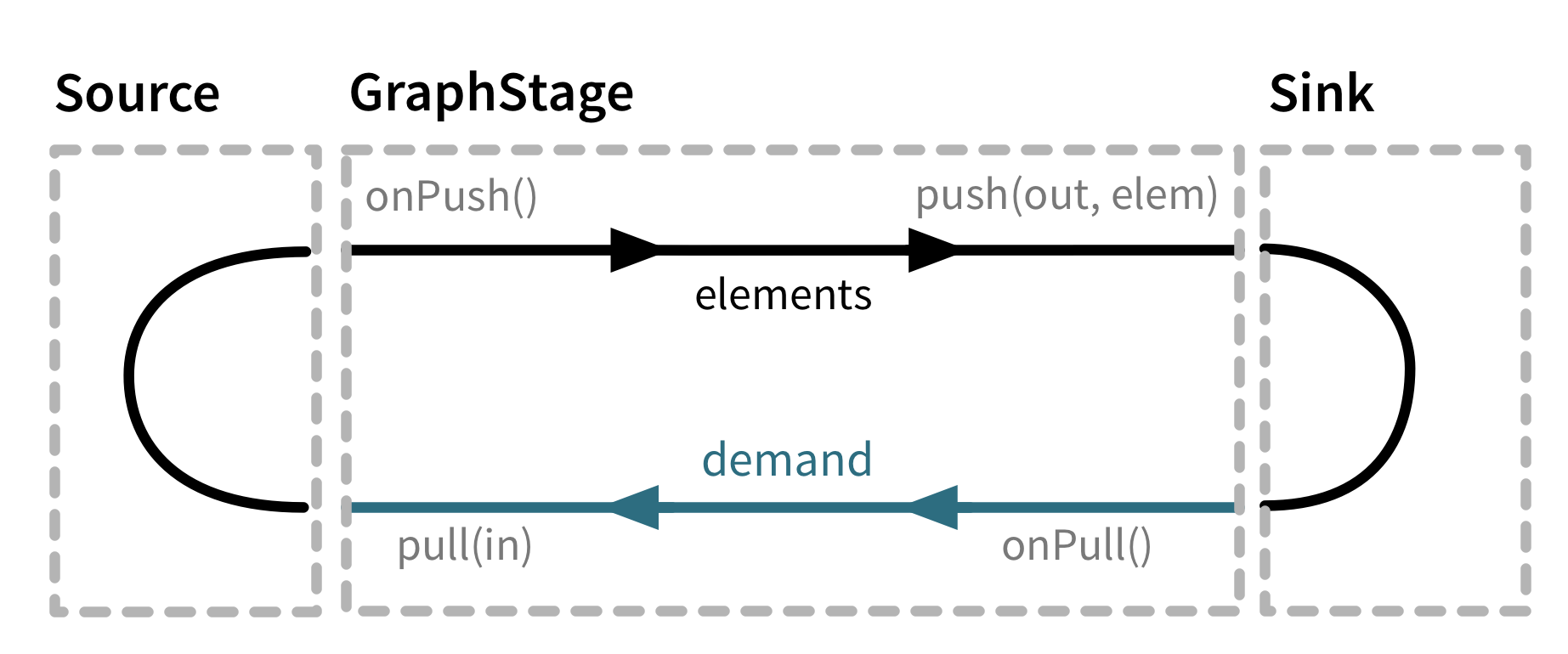
Thread safety
GraphStageLogic callbacks are thread safe the same way as Actor’s receive method is thread safe. That means they are never called concurrently and they can safely modify state of GraphStageLogic. On the other hand similar restriction to Actor one applies – Future’s callbacks should not close over state.
Real world Filter GraphStage
At the beginning I wrote that any node of execution graph may be implemented as GraphStage. That’s actually an understatement, because actually a lots of built-in combinators are implemented as GraphStage. (I lack knowledge here to say if it’s majority of built-in combinators or even all). Let’s take a look at akka.stream.impl.fusing.Filter:
https://gist.github.com/dariathecracker/e2072426c9c4ad20590b73cab76e1f2f
Well, it differs a little bit from our naive implemenation but the essence remains the same. The main difference here is that Akka’s implementation takes care of applying proper Supervision policy in case of failure. It’s advisable here because filter executes code injected by user which potentially may throw exceptions.
I find the fact that most built-in combinators are implemented as GraphStagequite useful as it means that you can easily inspect how they work underneath. Also, you can use them as a reference when writing your own GraphStages.
When you should consider to write your own GraphStage
The pragmatic answer to such question is when thing you need to do is impossible to achieve with built-in combinators. Here are some signs that you should think about custom GraphStage:
- you need to maintain state in order to process incoming messages. This is not a sufficient reason just by itself as you can do stateful computations using e.g.
statefulMapConcatbut this is not something that scales well as complexity grows and therefore should be used just for simple cases - you don’t pair input and output elements in one-to-one fashion. Simple example here may be
filter– you don’t know how many elements of initial Source will Sink receive. More complicatedGraphStagesmay buffer incoming messages in internal state and push them to downstream based on some criterias. It’s possible to do that because onGraphStagelevel we have access topushandpullmethods and callbacks
More involving example
Now, after I introduced the basics of GraphStage we can move to more involving example. I came across it when working on akka-http#192. The goal is to establish TCP connection to proxy host. Then we need to send CONNECTmessage and after successful response from proxy we can send and receive actual requests.
To keep our scope on GraphStage I will skip some HTTP-specific things like parsing requests. Also, instead of presenting final version of code at the beginning we will go step by step, so I will present also flawed version of code. I believe it may be beneficial to reader to see whole process instead of just end result.
Where to plug ProxyStage
Let’s start by finding place where we will put not yet built ProxyStage. It looks like this currently:
https://gist.github.com/anonymous/035161507379a1b939b30ea67c5a2890
You may wonder what is BidiFlow. This is an element of execution graph with two input and two output ports. Data elements arrive at first input (let’s call it I1), are processed and flows out at first output (O1), then the response comes back at second input (I2) and after being processed is yielded at second output (O2). Thus tlsStage can be illustrated with such diagram:
https://gist.github.com/anonymous/26f30606b7638217b3f63ffd1d152331
BidiFlow is especially useful when subsequent stages of your graph represents consecutive layers of communication. That’s why it was used for TLSStage and is commonly used in akka-http.
Now it’s clear that our ultimate goal can be achieved with such topology:
https://gist.github.com/anonymous/9b44ea94800652d25fe98991e6c42fb9
ProxyStage does not exist yet – we need to implement it. The only interesting thing that ProxyStage does is at the beginning of communication. After HTTPS tunnel is established it will serve just as transparent proxy that forwards what it receives. Let’s start with this easy part – we’ll call it NeutralStage. It may look like this:
https://gist.github.com/anonymous/98bdb98bc80f32ad216204939b921340
It can be run with:
https://gist.github.com/anonymous/1c5e7a9d54c37dae9ed07b41e9bc2e12
OK, it simply forwards messages in both directions. That’s a good starting point, now we need to send CONNECT message before we forward any other message. We can do it in bytesOut’s onPull – it will be called when transport layer asks for data:
https://gist.github.com/anonymous/64cf0ae217c6f3a118a899e310067ea8
We also introduced state variable of type State. It helps us to track current state of GraphStage. It is defined as:
https://gist.github.com/anonymous/f249cbabc1790e58f8f6f784d82c4df8
We also need to take care of incoming data elements on input I1. We append them to bufferedMsgs. As soon as we are in Connected state we can simply push what we received.
https://gist.github.com/anonymous/f43793b37f20d01b44e6f902b0e7e7f9
The last piece we need to add is validating Proxy response for CONNECTmessage. If proxyResponseValid returns true we consider it a success and change internal state to Connected. Besides of that we need to remember to send buffered messages. We can do it with emitMultiple:
https://gist.github.com/anonymous/ef9c4d2a1ffd4c09ea465127720da487
Whole code may be found in HttpsProxyStage0.scala in repo. We can run this code for sample Source with:
https://gist.github.com/anonymous/e4eb5cb4d4d5663b3e67b724e1afcabf
This code will hang up. Do you have any idea why?
The problem is that we don’t pull bytesIn enough. The only place when we pull bytesIn is inside sslOut’s onPull. It was called once (Sink signals it wants to consume some data) and then in bytesIn’s onPush we don’t push it outside as “OK” response is a technical message and Sink doesn’t care about it.
In other words – our HttpsProxyStage will see one data element more for ports communicating with transport than for ports communicating with outside world. (That’s an oversimplification in case of akka-http. Because of its streaming nature we cannot be sure that response to CONNECT will come as a single data element. For simplicity in this article we assume that it will always come in one data element).
https://gist.github.com/anonymous/4c0fd74b99f57b776f24ac1ba4176c17
Let’s add pull(bytesIn) in bytesIn’s onPush (HttpsProxyStage1.scala:
https://gist.github.com/anonymous/41a4bc51b1cc158b5851f16488e8aca3
After this change it seems to work.
Reduce state variables
We gained some deeper knowledge about relations between number of data elements. Now let’s analyze if we really need bufferedMsgs. You may think that we need to do something with incoming messages in sslIn’s onPush – and the only reasonable thing to do seems to save it to internal state.
And that’s right, but key observation here is that we can avoid onPush to be called unless connection is established. We can do it by not pulling sslIn – as long as it’s not pulled no one is able to push anything to it.
After bufferedMsgs removal (HttpsProxyStage2.scala):
https://gist.github.com/anonymous/6c836b06d28cf8f54f1370d0db48efe0
When we run this code it will throw an exception: java.lang.IllegalArgumentException: requirement failed: Cannot pull port (OutgoingSSL.in) twice. Exception message is quite clear, in stack trace we can even found fault line – it’s pull(sslIn) in bytesOut’s onPull.
Seems like bytesIn.onPush is called before bytesOut.onPull which results in calling pull(sslIn) twice in row. We shouldn’t code against any specific order as we don’t control layer behind ProxyStage.
What we should do is to test the code against both cases. The problem here is that with current testing code – namely transport being a simple flow created with Flow[ByteString].statefulMapConcat we don’t have enough control over data and demand elements. Moreover, logic of ProxyStage is getting quite complex and we should do some proper testing. Having tests done beforehand will make it easier to fix the bug.
Testing
We can test custom GraphStage and akka-streams in general with akka-stream-testkit. In simple cases it’s enough to run flow you want to test – in following example named flowUnderTest – in such fashion:
https://gist.github.com/anonymous/db44ab68dc45ac03beb5045b0d912092
I want to stress out here that akka-stream-testkit gives us a huge control over all kind of messages used in Akka Reactive Streams implementation. Besides of data elements and completions we can also send and check errors or subscriptions. Let’s see how we can rewrite the last code snippet:
https://gist.github.com/anonymous/a361d4868444d3a922ac29bae02ed5b4
We replaced requestNext(9) with request(1) with subsequent expectNext(9). That way we decoupled pulling from asserting receival of expected message. Let’s take a look at the most used sink’s methods:
def request(n: Long)– pulls forndata elements from upstreamdef expectNext(element: I)– expects arrival ofelement(does not pull)def expectNext(): I– expects arrival of any element which is returned as resultdef requestNext(element: T):– does whatrequestNext(1)and thenexpectNext(element)does
Going back to HttpsProxyStage – we want to test stage of BidiShape which is little bit more complicated. We can construct transport in such manner:
https://gist.github.com/anonymous/552b0e57175a29108f26ee800acc5b95
In that way we have access to transportInProbe and transportOutFlowwhich will allow us to test different transport layer behaviors.
What we wanted to achieve is to have bytesOut.onPull called before bytesIn.onPush. We can do this with following code:
https://gist.github.com/anonymous/877e6bfd597967e38f827f199937a779
We cannot replace transportInProbe.request(1) with transportInProbe.requestNext() as it would hang up test. We want to just pull at that place and then only after “OK” response was sent HttpsProxyStage will send anything more. More tests might be found in repo.
Ultimate implementation
You can look at the eventual implementation in CorrectHttpsProxyStage in repo.
We also override onUpstreamFinish and onDownstreamFinish to achieve transparency to errors. When a stage fails it firstly cancels all inputs and only after that sends error to all outputs. This ordering is problematic in case of BidiFlow because default implementation of onDownstreamFinish is to complete stage. So if transport will call failStage it will call onDownstreamFinish of bytesOut.
Therefore onUpstreamFailure will never be called for ProxyStage as it already won’t be running when transport propagate errors to its downstream… That’s why we need to do this:
https://gist.github.com/anonymous/4841247e6c215f8874f87977bf7395c6
failStage vs throwing exception
We can see that both styles are used in ultimate implementation but there’s a slight difference between them. failStage should be used when something that was anticipated happened and we want to cancel upstream, fail downstream and then stop stage. Error should flows down the stream and may be e.g. materialized to failed Future.
In our case, it’s the server responding with something different than “OK”. It’s a situation that may happen, is out of our control and we should be prepared to this.
On the other hand, we have situations when some assertions, on which we rely on, may fail. In that case it’s advisable to throw an exception. The effect will be similar to failStage and error also will flow down the stream but the situation will also we logged to akka log as an error.
Summary
GraphStageis useful when you run out of possibilities to get what you want with built-in combinatorsGraphStageis especially useful when you want to have precise control over details how data elements and demand should flow- It takes great diligence to properly balance
pulls andpushs akka-stream-testkitis there to help you test yourGraphStageand flows in general. It’s a very powerful tool that gives you great control over how data elements and demand flow- When writing custom
GraphStages take into account failure – how you want to propagate errors and if you want to suit it to Supervision Policy BidiFlowis useful for modeling layered protocolsGraphStageAPI is a nice abstraction over Reactive Streams. Understanding this API may help you gain a deeper understanding of Reactive Streams and backpressure in general- Most built-in combinators are implemented with
GraphStage. You can study existing implementations and their tests
Links
- Repository for this article
- Implementing a Custom Akka Streams Graph Stage
- Mastering GraphStages part 1 and part 2
- Akka docs on GraphStage
- akka-stream-contrib with quite a lot of
GraphStages
Acknowledgment
Thanks to James Roper for his suggestions in PR review.
Do you like this post? Want to stay updated? Follow us on Twitter or subscribe to our Feed.
More on Akka
- User Authentication with Keycloak – Part 2: Akka HTTP backend
- Storing files on Amazon S3 with Alpakka AWS S3 connector
- Improving Akka dispatchers
- Introduction to Streams in Akka
- Handling Split Brain scenarios with Akka
Read also

Authors
Popular Posts in category

Looking into Scala.js

Your first microservices using Scala and Lagom
Handling Split Brain scenarios with Akka



