

Storing files on Amazon S3 with Alpakka AWS S3 connector
S3 (Amazon’s Simple Storage Service) is a popular, widely used object storage service. Uploading a file and storing it on S3 in Akka Http traditionally involves temporarily storing a file before sending it to S3 service. This process can be simplified by using Alpakka AWS S3 Connector. In this post we will take a look at those two different ways and see how they compare with each other.
Uploading a file to akka-http service
Before we store a file on a S3 bucket, first let’s take a look at how can we upload a file to our Akka-http service. In the myriad of predefined Akka-http directives we can also find a handful of File Upload Directives. For our example we will use storeUploadedFile.
https://gist.github.com/yomajkel/4c0948cc5d4f2f0ee0dec87fdde36a3d
When dealing with bigger files we might want to increase the default request timeout. This can be done with another directive just for our single endpoint – withRequestTimeout. Alternatively, Akka provides a way of modifying a request timeout on a global scale with a configuration entry (akka.http.server.request-timeout). The complete route may look like this:
https://gist.github.com/yomajkel/03b7f55d79db3e8ab15a5b5508b84095
Storing uploaded file on S3 with PutObject
Having the file locally, we can now push it to S3 bucket. Using Amazon’s AWS Java SDK, a simple fire and forget approach is rather straightforward.
https://gist.github.com/yomajkel/4b7e21473fc9d8bc5cc0c0ad82a997ac
What we need is to simply create an S3 client and a PutObjectRequest.
This approach doesn’t notify us about the result of a given request. To have that information we must implement a ProgressListener and attach it to our request object. The way it is provided in AWS SDK is not a favourable solution in Scala.
Here, a delegation pattern is in use and in Scala we rather prefer to work with closures or Futures. We can wrap the ProgressListener into a Promise and return a Future to make it Scala friendly. Below is a more complete, scala-like example:
https://gist.github.com/yomajkel/f32199eea807247a96441a983f028619
With an S3 uploading code in place we can now finish our Akka-http route:
https://gist.github.com/yomajkel/0446294622ec5792260a75156fe3a6e6
Storing uploaded file on S3 with Multipart upload
AWS SDK offers another way of uploading a file to an S3 bucket, namely a multipart upload. While an approach with PutObjectRequest makes a single request per file, multipart allows us to split a file into multiple parts and upload each part separately. To quote AWS documentation:
- Multipart upload allows you to upload a single object as a set of parts. […]
- You can upload these object parts independently and in any order.
- If transmission of any part fails, you can retransmit that part without affecting other parts.
- After all parts of your object are uploaded, Amazon S3 assembles these parts and creates the object.
Also using multipart upload provides the following advantages:
- Improved throughput – You can upload parts in parallel to improve throughput.
- Quick recovery from any network issues – Smaller part size minimizes the impact of restarting a failed upload due to a network error.
- Pause and resume object uploads – You can upload object parts over time. Once you initiate a multipart upload there is no expiry; you must explicitly complete or abort the multipart upload.
- Begin an upload before you know the final object size – You can upload an object as you are creating it.
Multipart upload offers many customisations, but Amazon recommends to use it for files of 100 MB and larger. Having anS3Client and ProgressListeneralready defined, this is how we can create a multipart upload with a high level API:
https://gist.github.com/yomajkel/7e2df63a639dc9dcf8f1edd9220b81be
(full source code is linked in useful links section).
Streaming file directly to S3 with Alpakka connector
Alternatively, we can stream the file directly to S3 bucket with an alpakka AWS S3 Connector. Alpakka connector provides a sink to which we can connect an incoming file stream. Setting it up is similar to the previous approach.
The difference is that the S3Client we create is an instance of akka.stream.alpakka.s3.scaladsl.S3Client. Because we use streams, we also don’t need to implement any Promise to know what’s going on with our transfer.
https://gist.github.com/yomajkel/5acc02830597a5a30e9eb14cb3dbcf18
Akka provides a Directive with an access to the file being uploaded as a Source[ByteString, Any] – fileUpload. By connecting this source to Alpakka sink we get a complete solution that may look like this:
https://gist.github.com/yomajkel/b5e0fff5e4fa2c5de703a4e6fad7dba0
This approach seems more natural to Akka. It also seems a bit easier to implement and saves us from dealing with Java SDK.
<h2″>Probe uploads with JProfiler
Is a nicer code the only benefit of using Alpakka S3 connector? Let’s dig deeper under the hood with JProfiler to analyze the resource usage.
Defining a test scenarios
But before we start looking at the profiler output, let’s define a simple test scenario with Gatling for our profiling purposes.
https://gist.github.com/yomajkel/6bae8ddbc73e870300d606087234904e
This template will send 5 requests at a time separated by 5 seconds, totalling 30 requests sending 1 MB file. We can either use an Alpakka endpoint or temporary file endpoint.
Profiling
Finally, we can take a look at the profiler readouts. On the left we see the scenario being executed for temporary file endpoint with PutObject method, followed by an Alpakka connector endpoint on the right. In between there is a Garbage Collector activity which is marked by red lines.
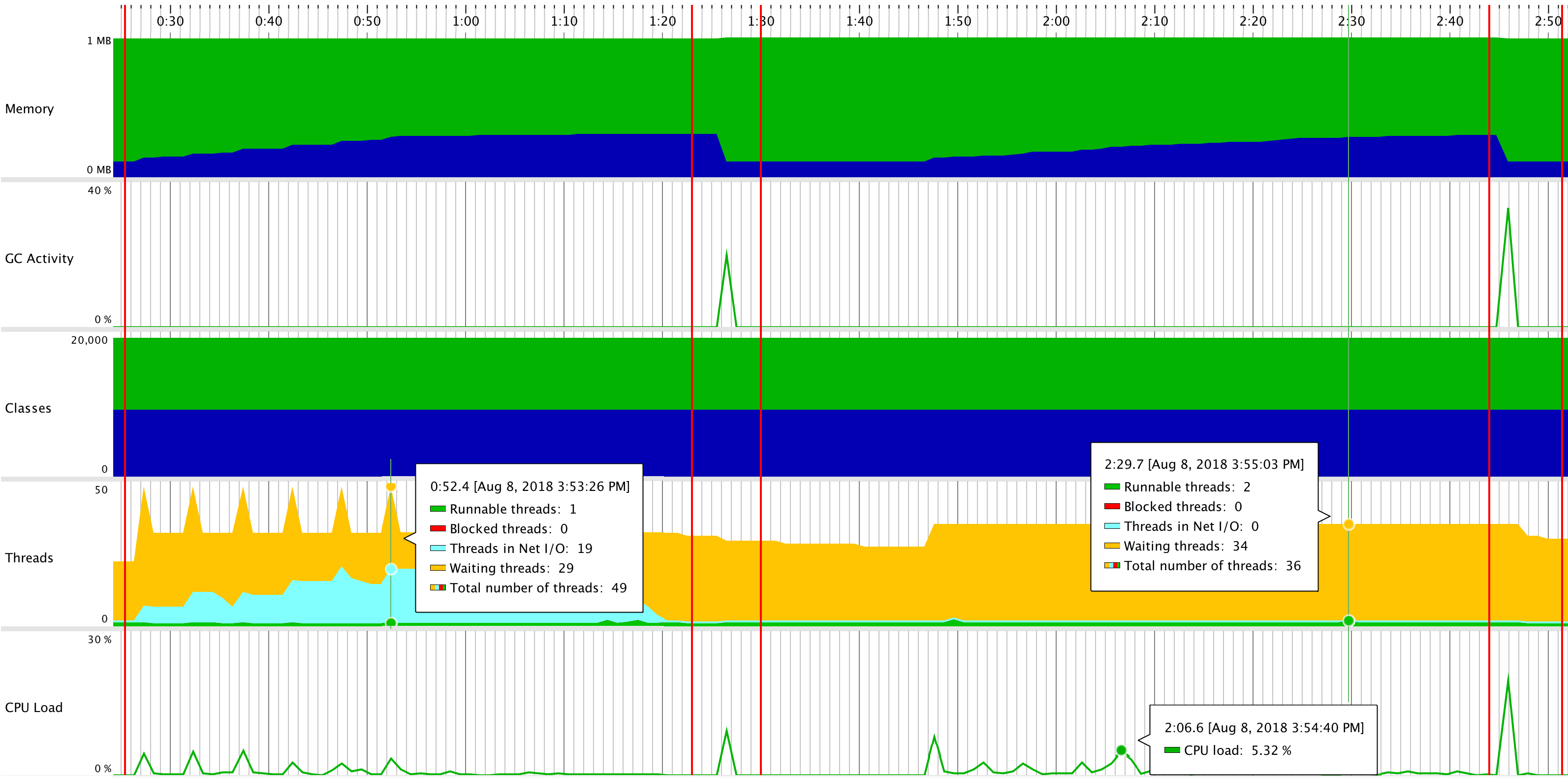
Memory usage looks very similar for both endpoints (slightly less than 300 MB used at the peak). Also the CPU statistics are similar with perhaps slightly more activity for the Alpakka endpoint (right hand side).
The bigger difference can be seen in Threads section. It appears that temporary file endpoint uses an I/O Thread for each request, also let’s notice the total number of threads which is 49 in peak. Alpakka S3 connector doesn’t spawn I/O Threads and the total number of threads in use is also smaller, being 36 (of which 34 are waiting).
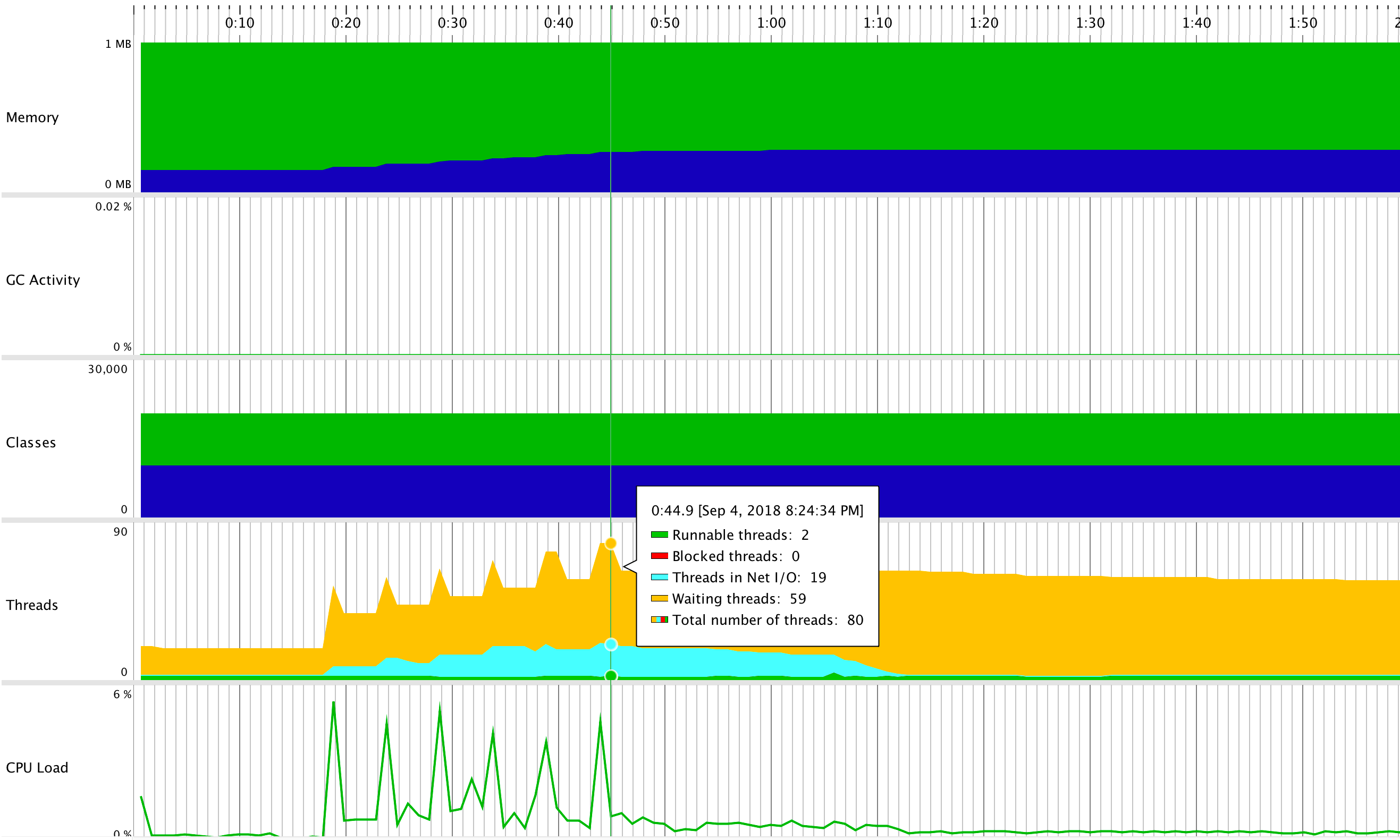
Uploading 1MB files with AWS SDK multipart upload (picture above) differs slightly from a PutObject method. The number of waiting threads is significantly larger, being 59 at the peak with the total number of threads reaching 80. We will see that this has it’s consequences in a later part of this post.
Also, let’s not forget that Amazon recommends to use multipart upload only for large files and I use 1 MB files only for illustration purpose, so that we can compare all our upload methods in similar conditions.
Stress testing
It was interesting to see what’s going on under the hood, but what really matters in production is how our endpoints behave under a heavy load.
During my analysis I was not using any kind of commercial grade service, neither an internet connection, but only a macbook pro (4 cores @2.9 GHz, i7) and a private office connection. I didn’t want to focus on precise numbers but instead wanted to check if there are any visible differences.
Defining a test scenario
To check how our endpoints behave under a load we will use a simple test of firing a number of simultaneous request against an endpoint.
In Gatling all we have to do is to use a atOnceUsers function instead of splitUsers. If we want to fire 200 simultaneous upload requests this is our code for injecting users:
https://gist.github.com/yomajkel/01f13e7acd6ce9abd977de61b0c2f9c9
For all our tests below we will execute a request of uploading a 10 kb file.
Testing a temporary file endpoint
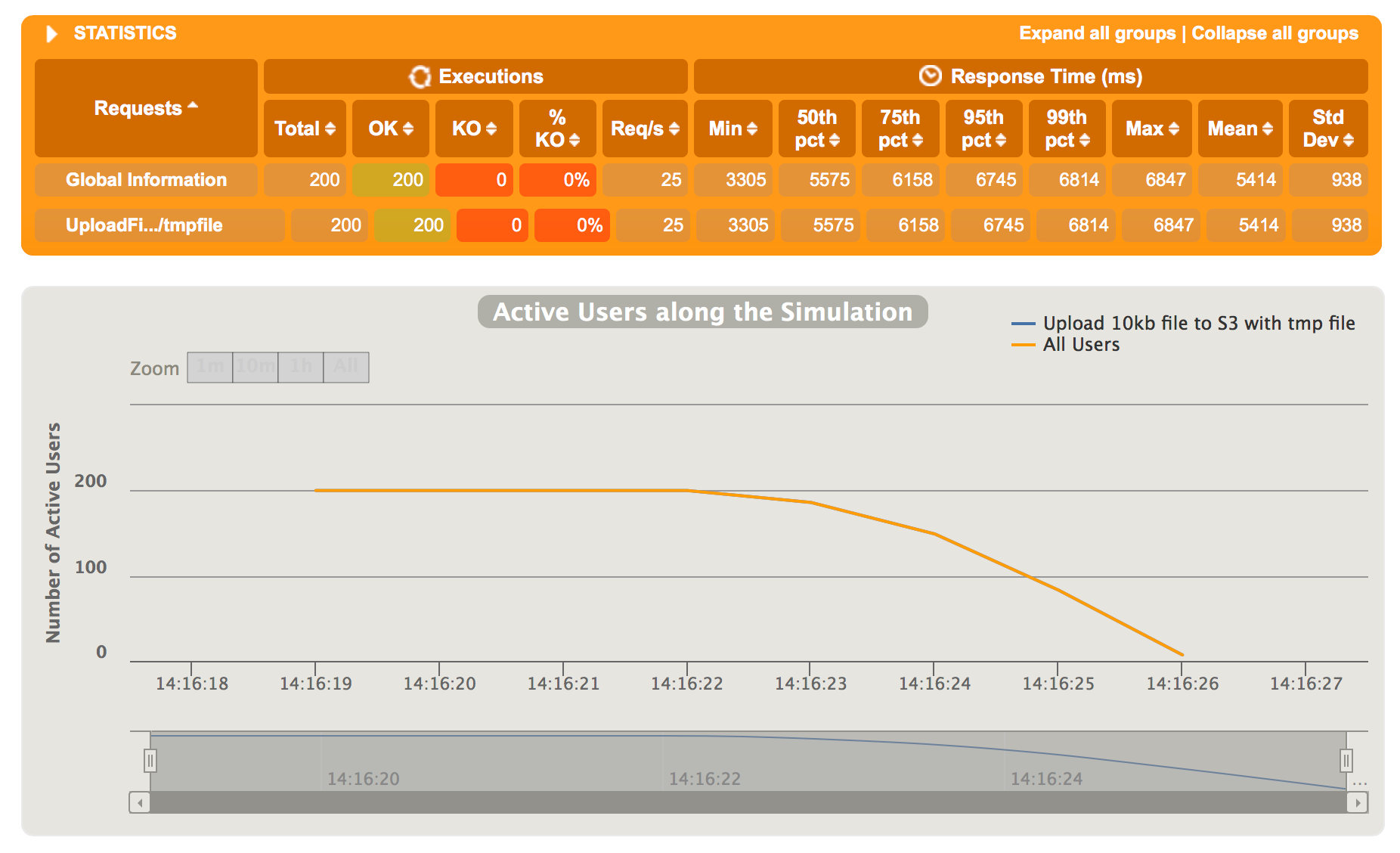
Firing 200 simultaneous requests at once looks quite good. All of the requests finish with status code 200 every time I try.
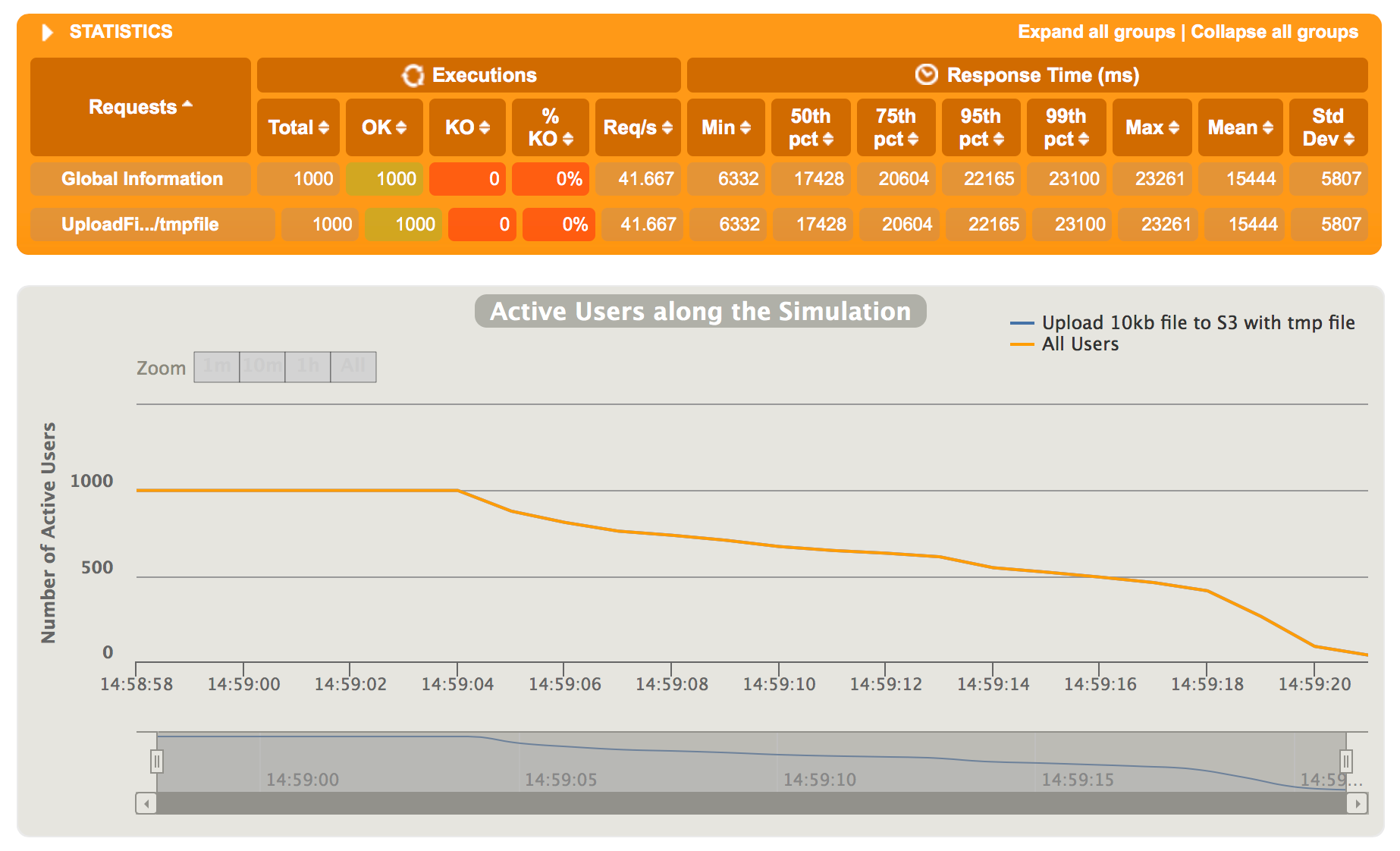
Upping the ante to 1000 requests also looks quite good. None of the requests fail as we can see below.
How many more can it handle before everything collapses? It turns out that increasing the number of requests to 1200 results in only ~900 requests completed. Increasing it even further can sometimes result in half of them failing. Here’s one of the summaries from Gatling, where we also can see the exceptions we get:
---- Response Time Distribution ------------------------------------------------ > t > 1200 ms 774 ( 52%) > failed 726 ( 48%) ---- Errors -------------------------------------------------------------------- > j.n.ConnectException: connection timed out: /0.0.0.0:9001 714 (98.35%) > j.n.ConnectException: Connection reset by peer: /0.0.0.0:9001 7 ( 0.96%) > i.n.c.s.ChannelOutputShutdownException: Channel output shutdown 5 ( 0.69%) ================================================================================
To summarize, a temporary file solution with AWS SDK can handle a significant load on a single instance. It is a good out-of-the-box solution that works well at least for small files without us having to worry too much about minor load increase. There is of course a fine line between everything working and chaotic exception throwing, so as always we should measure and monitor our service.
Testing a temporary file endpoint with multipart upload
Firing 200 requests looks very similar to the previous method.
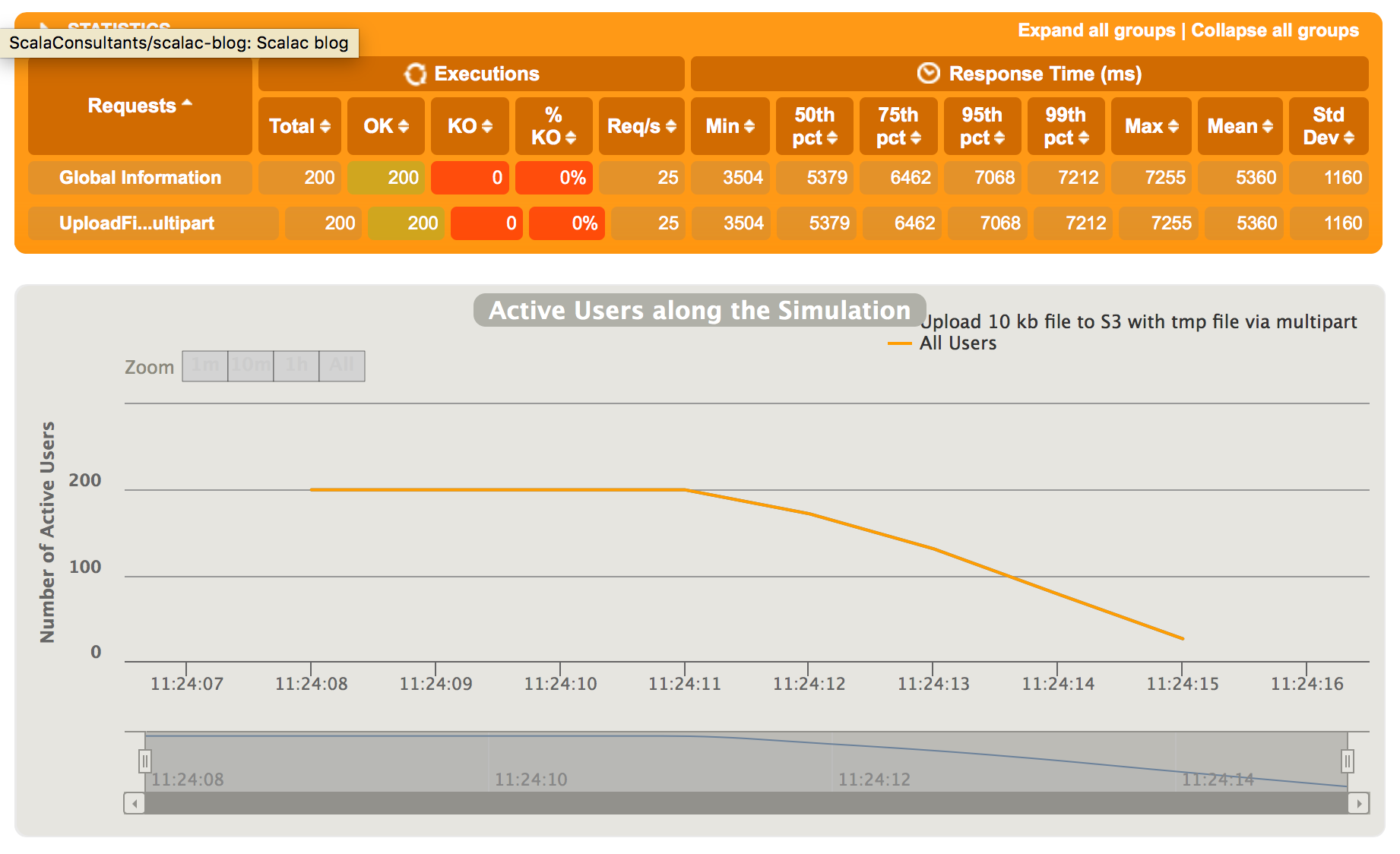
We can see the performance is practically identical to PutObject endpoint. The difference shows when we try to fire more requests. 800 seems to be the upper bound for all requests being successful and when trying a 1000 of requests a success ratio was ~80%.
---- Response Time Distribution ------------------------------------------------ > t > 1200 ms 894 ( 89%) > failed 106 ( 11%) --------------------------------------------------------------------------------
The exception we get from AWS SDK is
com.amazonaws.SdkClientException: Unable to execute HTTP request: Timeout waiting for connection from pool
It looks like requests get blocked trying to lease a connection from the pool and then eventually time out. I was not able to improve this state by changing any settings in host-connection-pool configuration.
It appears that multipart upload starts to fail sooner than a PutObjectmethod. The takeaway is that while there is no significant difference in response times, PutObject requires less resources and performs better when dealing with small files. It turns out that Amazon’s recommendation to use multipart upload only for large files is a good advice.
Testing Alpakka S3 connector endpoint
Here things look a little different. Triggering 50 requests at once already results in 5 of them failing.
---- Response Time Distribution ------------------------------------------------ > t > 1200 ms 45 ( 90%) > failed 5 ( 10%) --------------------------------------------------------------------------------
And it looks much worse the further we go with our testing. This is what we can expect from 500 simultaneous requests.
---- Response Time Distribution ------------------------------------------------ > t > 1200 ms 45 ( 9%) > failed 455 ( 91%) ---- Errors --------------------------------------------------------------------
Why does Alpakka stream fail for such a small amount of requests? If we look into the logs we will see a hint there.
akka.stream.BufferOverflowException: Exceeded configured max-open-requests value of [32]. This means that the request queue of this pool (...) has completely filled up because the pool currently does not process requests fast enough to handle the incoming request load. Please retry the request later. See https://doc.akka.io/docs/akka-http/current/scala/http/client-side/pool-overflow.html for more information.
When the host connection pool gets full, Alpakka will let the client know to slow down and wait until the server can handle more requests. This effectively prevents the connection pool from getting overloaded. Two questions arise from this.
How can we make this perform better? If the AWS SDK can handle much bigger load, why do we look at Alpakka stream? Let’s discuss them one by one.
Fine tuning Alpakka S3 connector
Setting connection pool limit
As we can see in the exception the BufferOverflowException occurs when the connection pool reaches a number of max-open-requests. By default it is configured to 32 but we can change it to a different number given it’s a power of 2. It may not be wise to set this number too high, but just for our testing purposes we’ll set it to 1024. Now if we execute 1000 requests all will succeed.
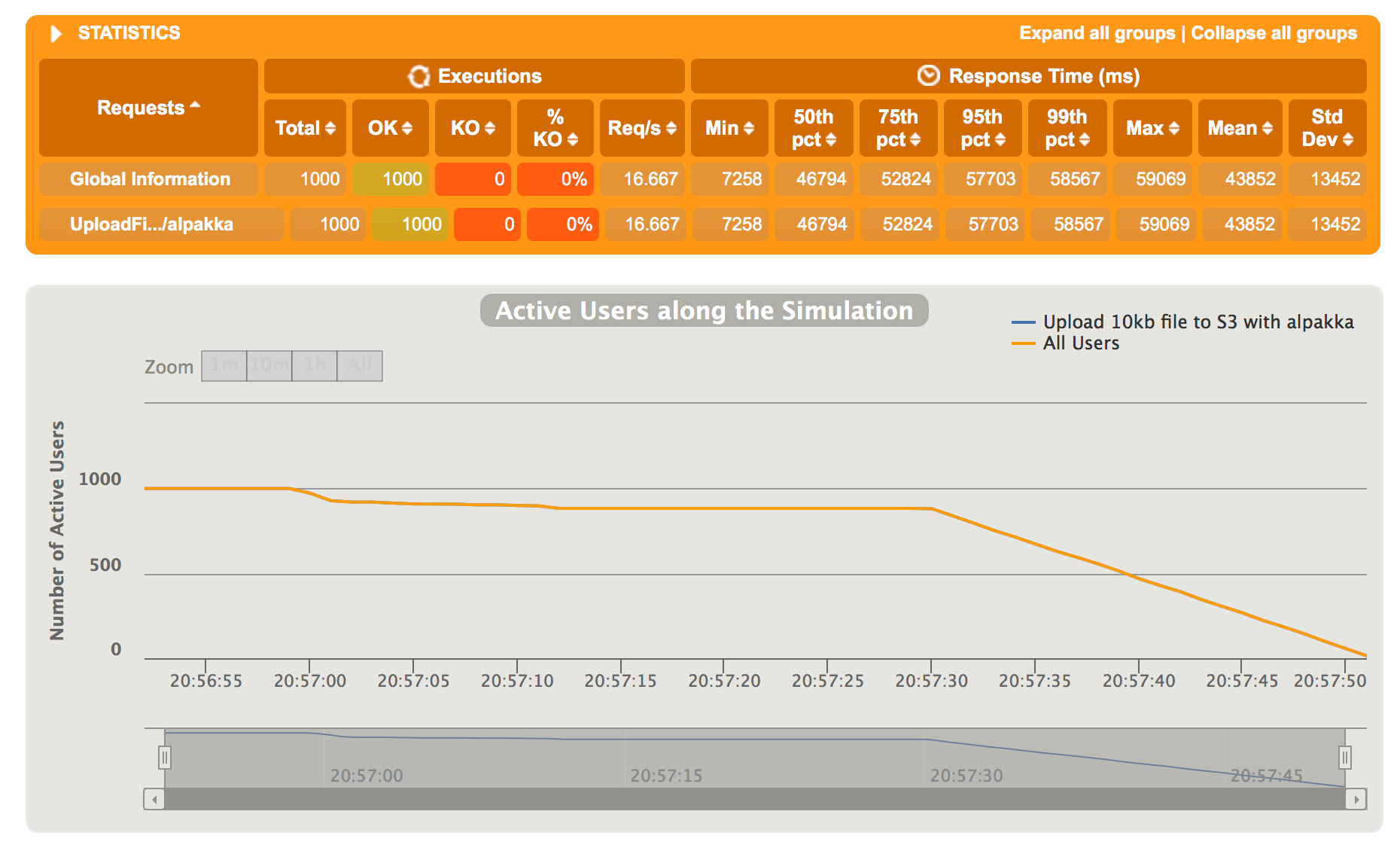
However, if we look at the response times they are 3 times worse than when using a temporary file. To quote the Akka documentation “(…) using an excessive number of connections will lead to worse performance on the network as more connections will compete for bandwidth.” So the take is that we can increase the max connection pool count, but it won’t always result in the performance increase.
This may be the case especially if there are some other dependencies involved, such as querying a database on every request, etc.
Implementing a Host Connection Pool
We can go further to tune any Akka streams and implement our own connection pools. There is much more on this topic in Akka documentation, Host-Level Client-Side API. This approach requires some knowledge on how Akka streamswork and some extra coding. This may be the way to go if you need to customize the streaming outside of what we already discussed.
A case for Alpakka S3 connector
For our simple case of handling a large number of small upload requests AWS SDK may give us slightly more out-of-the-box. Alpakka stream on the other hand may quickly start to reject incoming requests. This may be quite surprising and undesired if coming from a background with non-“streaming first” HTTP Clients. But there are still cases where the streaming approach may save us a lot of work.
When dealing with bigger files, over 100 MB or 1 GB or more, streaming will save us a lot of storage on our server. Not having to wait for a temporary file upload also means that the streaming to S3 can start earlier than in the alternative approach.
Lastly, when we reach a connection pool limit, it may be preferred to launch another instance instead of trying to enqueue more requests. As we saw, even crunching up requests in AWS SDK has it’s limits and usually, it is better to act soon rather than allow for our server to clog up.
Conclusion
Uploading a file to S3 using a temporary file and AWS SDK is a convenient approach that can handle occasional load spikes, given we have enough space for temporary files. Alpakka S3 connector seems to be an approach requiring a little bit more effort but is giving us full control over what is going on in our service.
Streams are also suited for handling bigger files in which case we can save a significant amount of resources. With built-in backpressure from Akka streams, Alpakka may perfectly fit into your stack. On the other hand, if the service will only handle smaller files AWS SDK may be the right approach to get the job done.
As always, there is no single tool for every case, but I hope that this article will help you to make the right choice.
What are your experiences with using the Alpakka S3 connector or AWS SDK? Don’t hesitate to share it by leaving a comment below. Happy hakking!
Useful links
- akka upload service (source code from this article)
- akka-http
- alpakka S3 Connector
- JProfiler
- Gatling
- Amazon S3
Do you like this post? Want to stay updated? Follow us on Twitter or subscribe to our Feed.
Read more on Akka

Authors
I am a Software engineer with over 10 years of programming experience. Working as a backend, fronted developer and mobile apps programmer gave me insight into a full cycle of software development. I'm passionate about code quality as well as developing elegant, user-oriented solutions together with the team. I'm continuously expanding my skills in Scala and functional programming paradigms and am always eager to learn new technologies and develop new skills. I have a good understanding of agile methodologies, such as Scrum, Kanban or mix of both. I am experienced in working with Continuous Integration and Continuous Delivery. Experienced developing backend services and websites in Scala and PHP as well as proficient in iOS apps development in Objective-c and Swift.
Popular Posts in category

Looking into Scala.js

Your first microservices using Scala and Lagom
Handling Split Brain scenarios with Akka



