Avoiding Unnecessary Object Instantiation with Specialized Generics
In this post, we will look at how primitive Scala types such as Int and Long are represented down to the bytecode level. This will help us understand what the performance effects of using them in generic classes are. We will also explore the functionalities that the Scala compiler provides us for mitigating such performance penalties.
Furthermore, we will take a look at concrete benchmark results and convince ourselves that boxing/unboxing can have a significant effect on the latency of an application.
Basic concepts
Scala has tremendously powerful type system that allows us to express complex concepts. In addition to that language and compiler designers have put significant amount of engineering effort into making sure that the expressiveness of the language does not come at the expense of its performance.
Furthermore a lot of lessons that have been learned in the past (primarily from Java) have been put into practice.The result of that is a language that has a logical and coherent type system.
One clear example of that is the fact that Scala does not have the concept of primitive types in the same way Java does. Most of us know that Java defines 8 primitive types – short, int, long, double, float, boolean, char and byte.
One of the benefits of working with the so called primitive types is that they are not instantiated as objects and most of the time can live entirely on the stack. This has a number of important implications, probably the most notable being the fact that the cost of object instantiation and subsequent garbage collection is decreased. This is particularly important in systems that need to be highly performant and provide quite predictable latency characteristics.
Garbage collection cycles often incur what is known as “stop the world” events, which can significantly decrease the level to which the performance of system running on the JVM can be predicted. This is why most of the time working with primitive types when dealing with critical sections of latency sensitive systems is preferred.
Unfortunately, a logical gap exists in Java’s type system. Because of the fact that primitive types cannot be contained in generic containers and the way in which generics work in Java (through type erasure), for each primitive type, a wrapper type exists.
For example we do have the type int which has the wrapper type Integer. And because generic collections types such as List<T> can only hold wrapper types, every time we try and add an int type to a List<Integer>, we end up converting the primitive to a wrapper object automatically. This process happens transparently and is called autoboxing.
The problem with autoboxing is that every time we do this conversion a new instance of Integer (or whatever the wrapper class might be) is created. This instance however does not live on the stack but is instead allocated memory on the heap. This does come with all the performance implications mentioned earlier.
Scala takes a different approach and does not partition its type system into primitive and wrapper types. After all, this is part of the reason why its type system is referred to as an “Unified Type System”. Instead all primitive types (Int, Double, Long) are defined as classes that extend AnyVal. What happens upon compilation is that the bytecode generated represents them as primitive types, thereby avoiding heap memory allocation.
This is indeed a clever way to provide a very unified view of types while still preserving the benefits that JVM primitives provide. Unfortunately however, when it comes to using these AnyVal types in generic types, things cannot be optimized that easily.
Generic classes and boxing
If we have a class with a type argument, and we parametrize it to use any of Scala’s primitive types like Int or Long, we are faced with the problem of boxing. The bytecode that will get produced upon execution on the JVM will actually create a wrapper object that will contain the value of the int and allocate it on the heap instead of keeping it only on the stack.
Lets looks at an example. Imagine you want to model a rook that can occupy a position on a chess board. A piece of code that places a rook on a every square of a 2048 by 2048 board might look like:
https://gist.github.com/zaharidichev/ca07069b0bd2856b06dbef8b1ef4f18c#file-specialization-non-generic-scala
Once compiled all of the Int objects will be treated as primitive int types and will in fact live on the stack, thereby not occupying any heap space. To prove that to ourselves, lets look at the bytecode that the Scala compiler generates.
https://gist.github.com/zaharidichev/a5cd8e0049334052f0d5e30856374d86#file-specialization-non-generic-bytecode-scala
This is the code which gets executed when the for expression yields on each generated square. The code is called 2048 * 2048 times. Looking at the operations, it is clear that we do not allocate any heap objects for the passed Int coordinates.
Imagine now however that we want to modify our code a bit in order to allow the developer who uses our Rook class to choose any type of the coordinates x and y. Perhaps the chess board is so big that its width and height do not fit in the 32 bits that are available in an Int. Or perhaps someone wants to use a custom type to express the position. An easy way to provide that functionality is to modify our code to use generics.
https://gist.github.com/zaharidichev/6ed84ad20d4fc29aecb8bb4c07e8dbc6#file-specialization-generic-scala
This provides us with the flexibility to choose our own representation of the xand y coordinates. However, flexibility comes at a certain price:
https://gist.github.com/zaharidichev/2ebb9cbd7c1ea0d9c173adfdcb09880a#file-specialization-generic-bytecode-scala
If we take a look at the generated bytecode, we can clearly see that we are calling BoxesRunTime.boxToInteger for each of the position arguments when creating a Rook[Int]. If we ignore Integer and Long pools, and we do a bit of simple math, we can convince ourselves that for a board of size 2048 in one direction, we are creating 2048 * 2048 * 2 = 8388608 objects on the heap.
Each of these objects incurs a number of performance penalties which can prove to be quite harmful in a system that is latency sensitive.
Impact on Memory Footprint
If we really want to be sure that the latter is true, we can delve deeper and profile the two different programs. Lets look at the state of the heap of the two versions of our little Rook placement program. In the generic version, when we map the heap with jmap -histo, we observe the following:
We have allocated 8827741 Integer objects that live in the heap. This actually amounts to 141.2 MB of data. Not such a great amount of memory footprint, but you can guess how this can increase tremendously for applications that are dealing with a lot more data.
As a result we might incur a lot more GC pauses and degrade the overall performance of the application. In comparison to that, we can observe that using the non generic version of our program, which works only with Int types, we have significantly less Integer objects living in the heap memory:
To put it simply, we have decreased the memory footprint of the Integerobjects from 141.2MB to 27.7MB. Of course there is some additional integer allocation coming from the Scala collection framework itself and the fact that we are using for comprehensions.
This, however, is not a topic of the discussion at hand and therefore we ignore it. If you want to dig deeper, you can look at the full bytecode representation and try to understand for yourself what is really happening under the hood when we use generators such as start to end or start until end.
Scala Specialization to the rescue
One possible solution that we can think of is to provide separate implementations for all the different types that we need. That being said, we can have IntRook and LongRook. This will solve our performance problems and will allow the runtime to avoid boxing the primitive types into wrappers.
Although this might sound like a plausible solution, it really comes at the price of bloating the code base with a number of classes that are largely the same. All in all it does not seem like the best solution in practice. Thankfully, the Scala compiler provides with a feature called specialization.
What this allow us to do is to mark the T type as @specialized. Upon compilation this will generate concrete implementation for all the primitive Scala types and will avoid the boxing problem. Following is a code snippet that uses the @specializedannotation to do that.
https://gist.github.com/zaharidichev/7001829baa3e18c922cac0b1239e04e9#file-specialization-specialized-scala
Note that we specialize just for Int. This means that an Int version for the class will be generated by the compiler and will be used whenever we parametrize our Rook instance to use positions of type Int.
If we omit the type parameter of the specialized annotation and just use @specialized, the compiler will generate additional class versions for all primitive types such as Rook[Double], Rook[Boolean], etc. To convince ourselves that this is what happens, we can take a look at the bytecode representation:
https://gist.github.com/zaharidichev/67dd9278344640c5580518674aba4f66#file-specialization-specialized-bytecode-scala
We can see that in the preceding sequence of bytecode ops the class that is getting instantiated is in fact PlacingRooks$Rook$mcI$sp, which is the Int specialized version of our Rook case class. The other observation that can be made is that there is no sign of any boxing as the class is compiled to work directly with int primitive types.
Performance Considerations
As already mentioned, boxing and unboxing can have quite significant impact on the performance of a piece of code. It mainly has two performance hits:
- Increases the size of the heap thereby causing longer and more frequent GC cycles. This in turn introduces jitter in the latency of the system. The latter can render a system with quite strict latency requirements unresponsive for a period of time.
- Introduces object instantiation overhead which simply causes our program to take longer to complete. Whenever we are dealing with a lot of objects, this can have significant effect on how fast our Scala code runs.
To put that into more concrete perspective, the code was benchmarked using JMH running 20 iterations and 10 warm up cycles. What was measured was the operation of filling a board of size 2048 by 2048 with Rook objects. The average time to complete the task is measured using the specialized and the non specialized version of the class:
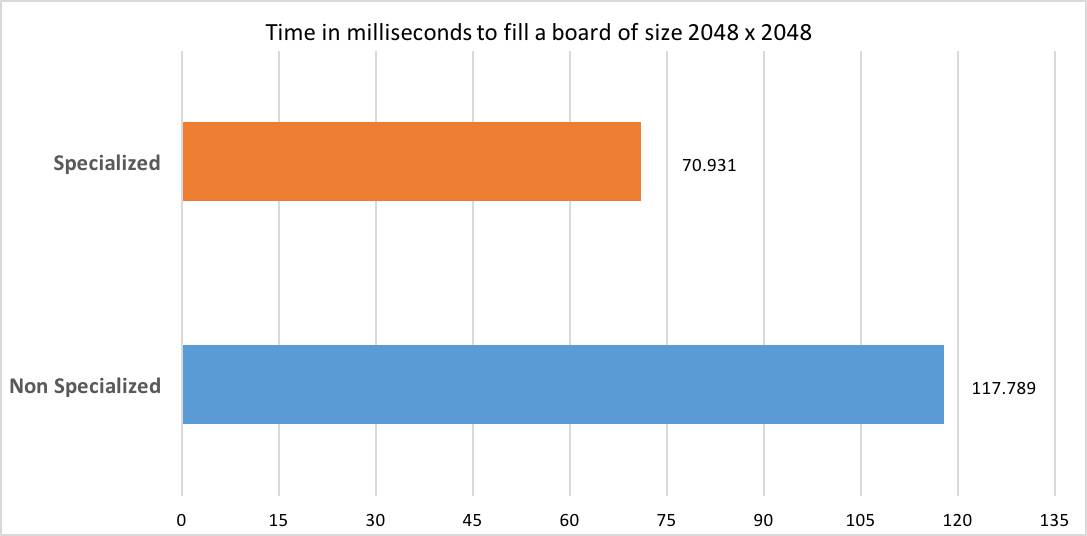
Results speak for themselves. As we can see, the non specialized version of the code is over 65% slower. Bear in mind that this is just measuring the average time. There are other profound performance implications that stem from maintaining a much larger heap.
Specialized Generics in the Standard Library
There are quite a bit of types in the standard library that can make use of specialization in order to avoid autoboxing when instantiated. One such type is the Tuple. Most of us already know that there are 22 tuple classes to cover the range of arity needed (e.g. Tuple1[+T1], Tuple2[+T1, +T2]). Below are the declarations of the Tuple class for for arity of 1 and 3.
https://gist.github.com/zaharidichev/ca72ff37df026c8231a58f0a4de0b956#file-tuple-arity-scala
An interesting observation is that Tuple1 is specialized but only for Int, Long and Double, while Tuple3 is not specialized at all. If you peek at the source code of other standard library classes, you will see that @specialized has been used quite conservatively.
The reason for that is simple – the number of generated class files grows exponentially as the number of type parameters increases. Let’s take for example Tuple3. If it was specialized for all 9 primitive types and 1 reference type that would result in 10^3 = 1000 generated classes. It is pretty clear that this quickly becomes unmanageable as the number of type parameters grows.
That being said, one needs to be careful when using @specialized as excessive specialization can have significant impact on compile time and size of the bytecode.
Summary
There are considerable performance penalties introduced by the JVM whenever primitive types and generics are combined. This is mainly due to the design decisions that have been embedded into the virtual machine itself. Although Scala does a great job covering some of Java’s problems by providing an Unified Typesystem, the performance of Scala applications can still suffer from excessive heap memory allocation.
This is why Scala had provided the @specialized annotation to be used as a hint to the compiler that generation of more specific classes from the generic ones is needed. Although this increases the size of the compiled artifacts, it can result in significant performance boost whenever used appropriately.
Links
- Git Repository for the article
- Unified Typesystem
- Autoboxing in Java
- Java Primitive Types
- JVM Garbage Collection
- Type Erasure
- The Specialized Annotation
- JMH Benchmarking tool
Do you like this post? Want to stay updated? Follow us on Twitter or subscribe to our Feed.
See also

Authors
Popular Posts in category

Looking into Scala.js

Your first microservices using Scala and Lagom
Handling Split Brain scenarios with Akka