Using Akka HTTP with Sangria as GraphQL backend
Really quick introduction to GraphQL
What is GraphQL?
Many people think that GraphQL is ‘something’ related to Graph Databases, in my opinion they’re wrong. GraphQL is to Graph DB like Javascript to Java. Are based on similar concepts, but are used for completely different things.
GraphQL is a query language for API’s. Some people name it successor of REST, I’d rather say it supplementor of REST because both can work together. In this article you’ll find good comparison of both.
In short: GraphQL is a query language for APIs, optimized for performance, designed and open-sourced by Facebook. In GraphQL you can ask server for connected data and you’ll get in response only what you’ve asked for. Not more. If you need more information about this, you’ll find it on GraphQL webpage
Setup
To setup GraphQL backend server we’ll use few libraries. The first is Akka HTTP – one of the most popular HTTP servers in the Scala world nowadays. The library responsible for GraphQL implementation is Sangria. We’ll also use Slick with an in-memory database.
The source code for starting point you can find here. Feel free to fork this repository. master branch has final version of our code, but there are also branches ‘stage#’ representing states between. For easier tracking changes between stages I prepared patch files with differences. You can apply such patch (i.e. git apply stage1-stage2.patch) and your code editor will highlight all changes that were made.
The branch mentioned above has code able to run the basic server. There are all dependencies and plugins configured. I assume you’re at least little familiar with the Scala world and I don’t need to explain where to find such information in the codebase :D.
Let’s look into the code now. The basic Akka HTTP server is defined in Server file.
https://gist.github.com/anonymous/67a97ba6b4830c38f8c1a3abd27def71#file-post-scala
As you can see, route definition has only two endpoints. Every POST to /graphql endpoint is delegated to GraphQLServer, everything else is managed by graphiql.html file (placed in resources btw).
graphiql.html is a basic HTML console you can use to test your GraphQL backend. Here you can find an example to see how it should looks like. In my code I use slightly changed version of Graphiql provided by Sangria. When you run the server (sbt run) you should be able to use this console now, it’s configured to connect to our server so you can use it for testing.
Domain
In Models you can find entire domain we will be working with. In short: our domain is defined by Categories and Products related one to each other. Between them is a many-to-many relation, so in the file you can find simple case class representing this.
In Models.scala file there are also things I have to explain now. Firstly, I’ve defined type aliases CategoryId and ProductId. The reason for that is to improve the readability the code I’ll explain further.
Sangria library has not-the-best documentation, I would say. Especially when you’re working with relations it’s really easy to mess the types, to avoid this I decided to use type aliases.
There is also Identifiable trait in file. In this case I wanted to highlight support for polymorphic types provided by Sangria. Similar is for Picturemodel with factory method inside Product – I wanted to show you, how to use such kind of structures. I hope the rest of the file should be understandable and there is no need to explain it.
As you can find in application.conf the server uses in-memory database which is populated with data during start. All the things related to DB connection I placed in one file: ShopRepository. There you can find Slick Schema model definitions. There are also accessors for either single records and collections. It gives us 6 functions at this moment.
In the repository there are only two other files worth mentioning: GraphQLServer and SchemaDef. The first one is responsible for handling GraphQL calls and the second one is responsible for interpreting GraphQL queries. Both are described more detailed in the next section.
GraphQL implementation
As we saw previously, all the POST requests targeted to /graphql endpoint server delegates to GraphQLServer file. Let’s look onto this now. The server expects JSON model with the following shape:
It’d shed more light on topic when you’ve already saw the content of the file. GraphQLServer tries to read these three root objects and pass it to the executor. query is the GraphQL query itself, variables is additional data for that query. In GraphQL you can send the query and arguments separately.
You can also set name for the query, it’s what the third object is for. Imagine that query is like a function, usually you’re using anonymous functions, but for logging or other purposes you could add names. It’s send as operationName. More about that you can read here.
The most important call in this file is Executor.execute
https://gist.github.com/anonymous/b850a6ddddd0eba790ea46db1b2b0101#file-post-scala
If executor responds with success, the result is send back to the client, in other case server will responds with status code 4xx and some kind of explanation what was wrong with the query.
https://gist.github.com/anonymous/ae2564a7df71ed15f329de3cb025b36e#file-post-scala
Executor also needs few things from SchemaDef file, so let’s discuss them now.
SchemaDef is the most important file in our example project. It contains our Schema – what we are able to query for. It also interprets how data is fetched and from which data source (i.e. one or more databases, REST call to the other server…). In short our SchemaDef file defines what we want to expose. There are defined types (from GraphQL point of view) and shape of the schema a client is able to query for.
Defining types
The Models file contains classes for our domain, now we have to expose it. But we cannot use the same case classes, we have to define types what are understandable by Sangria. It’s worth pointing out that there doesn’t have to be a 1-1 mapping between our Sangria and DB models. This abstraction allows us to freely hide, add or aggregate fields.
Let’s discuss it on this simple class:
https://gist.github.com/anonymous/5387dbdd03e3d6c1509693687fb9b25b#file-post-scala
Now we have to define proper ObjectType for this case class. We have to map all the fields like this:
https://gist.github.com/anonymous/e71446e4410d20350314ffdcb76ddf82#file-post-scala
Let’s look onto it line by line:
ObjectType[Unit, Picture] tells us that it’s ObjectType for our Picturecase class. But what is the Unit there? It’s Context type. In our example we’re using Unit because we don’t need it at all, but in complex, production schemas probably you will. Context is an object that flows across the whole execution. Usually it doesn’t change state, but if you need you can store some helpful data there to use in following sub queries.
Often developers put there object responsible for the access to the data source but you can use it in other way. For example (especially if you use middleware) you can put there users permissions’ list for easy access in the next processing step. To be clear: Context lives only during one execution, I mean: from request to response.
Two next lines define name and description for our type. Server also exposes documentation for schema, so don’t be shy and document your types!
Next we’re defining fields. Each Field, has name, type and resolver. Typically you can use resolver as function that read the value from provided case class and context.
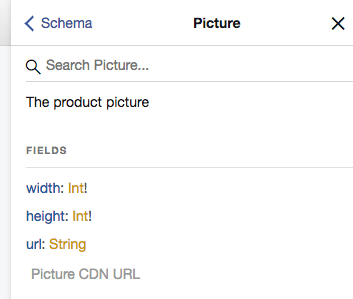
In our example above we’re mapping width and height exactly like in case class, but for url we’ve added also a description.
Let’s look at the produced schema. Run the project and open the browser at https://localhost:8080, on top-right you have Docs tab, open it now and search for Picture type. You should see something like this:
Easy like this. But it could be even easier. Sangria provides some macros that read the case classes and creates proper object types for it. For example, you can define type for Picture like this:
https://gist.github.com/anonymous/a51e9c6585e71bce9d7905fa0d67ad01#file-post-scala
deriveObjectType is included in package sangria.macros.derive so don’t forget to import this. Macros are handy for simple cases, but they can only extract data from case classes, not read your mind. So the rest you will have to add manually. For instance documentation: you have to put all the information manually.
https://gist.github.com/anonymous/d77fbe380fbd1f2d70b38c73850fd133#file-post-scala
The code above will produce exactly the same object type for picture like we made few lines above.
Let’s look on types defined in SchemaDef once again. There you can find also definition of Identifiable type we’ve used as parent for both: Product and Category.
To define such interface you should use InterfaceType instead of ObjectType and then you can pass it to proper object type. In the definition of ProductType there is also IncludeMethods("picture") what tells the macro which additional functions we want to expose in our schema.
Please look on the last two constants defined in the file. QueryType is one more ObjectType, but it defines our root schema, it defines what we allow to fetch for, actually… it’s used in the Schema at the last line and passed to Executor.
What the QueryType has inside? There are three fields exposed: allProducts, product and products.
For now we don’t touch categories. allProducts returns list of products ListType(ProductType) and use ShopRepository (provided as context) and its function with the same name (allProducts). Easy like this. ListType, IntType and similar basic types are already defined by Sangria so you don’t have to do it yourself.
https://gist.github.com/anonymous/92cba7cc73987b22af214ab9c23e354e#file-post-scala
In the example above we’re also expecting arguments. arguments property is always a list of Argument hence you can see :: Nil at the end.Argument("id", IntType) means it expects argument of type Integer and name id, the same argument we are passing to the ctx.product function in the resolver, so we can even extract it as variable instead of keep it inline.
It’s worth of extracting especially, when you want to reuse it in the in other types. You can replace the code above with the following.
https://gist.github.com/anonymous/cfa9784858dacbd6ff84ecb196e2b4b5#file-post-scala
That’s all for this step. You can run the server, open the console and play with that. Remember, at this step we have only three fields exposed.
There are example queries you can use:
https://gist.github.com/anonymous/24d8592159eb82995ceb2e21f543cdd1#file-post-text
You can also pass some values as variables, you can use such query in that case:
https://gist.github.com/anonymous/c223b74ab833371cca16e74a921dca3c#file-post-text
But then you have to provide values as JSON in the the Query variablesinput, like this:
https://gist.github.com/anonymous/f52a71f8fbec325e9e1944b3d3acc202#file-post-json
So far, so good. But what about performance? What if we execute a query like this?
https://gist.github.com/anonymous/2f110649bf7db655a8ce6f9b0f9d055c#file-post-text
As we remember, resolver for products field fetches data directly from database. In this case it fetches three times same results. To optimize this, Sangria provides Fetchers and DeferredResolvers
Fetchers and Deferred Resolvers
Fetchers and Deferred Resolvers are mechanisms for batch retrieval of object from their sources like database or external API. Deferred Resolverprovides low-level efficient API but, on the other hand, it’s more complicated in use and less secured.
Fetcher is a specialized version of Deferred Resolver. It provides high-level API, it’s easier to use and usually provides all you need. It optimizes resolution of fetched entities based on its ID or relation, it deduplicates entities and caches the results, to name but a few possibilities.
Let’s implement one for Product:
https://gist.github.com/anonymous/ae3764bff1bd9ff87a8ed6eb6a5ac8f9#file-post-scala
and change fields in QueryType to use this:
https://gist.github.com/anonymous/ad4c8c2dabccbbbf2f70365edfab4efb#file-post-scala
We’re still using repo.products to fetch products from database, but now it’s wrapped in Fetcher. It optimizes the query before call. Firstly it gathers all data it should fetch and then it executes the query. Caching and deduplication mechanisms allow to avoid duplicated queries and give results faster.
Ok, if we have our fetcher defined, we push it to lower level.
https://gist.github.com/anonymous/c66b27f554b800d78495b84512695f7c#file-post-scala
Such resolver have to be passed into the Executor to make it available for use. As you can see, we use the same fetcher in two fields, in the first example we’re providing only one ID and expecting one object (defer function) in the second case we’re providing a list of IDs and expecting a sequence of objects (deferSeq). Look at the Sangria docs if you’re interested in other cases.
Since, we’re using ShopRepository.products to fetch single entity or entire list, we don’t need product function anymore.
To extract ID from entities, Resolver uses HasId type class. You have few choices how to provide such class for your model. Firstly you can explicitly pass it.
https://gist.github.com/anonymous/2ec8c8bfd52eae28101cb991597a140e#file-post-scala
On the other hand, you can declare implicit constant in the same context so fetcher will take it implicitly. For example you can use generic HasId for every child of Identifiable trait and import it to the context.
https://gist.github.com/anonymous/e205fab88f8b727f51105e48bc31c39d#file-post-scala
The third way is the way I’ve chosen. Providing HasId implicitly inside Model, like this:
https://gist.github.com/anonymous/7999b1760a8c999b79ab2d92d7225a09#file-post-scala
BTW you can read more about type classes in another good article on our blog.
Applying the last changes should makes your code similar to branch stage2. In repository there is also code responsible for Category entities, but we will skip it here – it’s pretty similar .
Implementing Many-to-Many relation
Time to implement relation between Product and Category models. One-to-Many is much easier to manage but I chose to make some extra miles.
Our plan is to make us able to execute such queries:
https://gist.github.com/anonymous/43ae29bea8d0b19d4c3bd001a0eef592#file-post-text
In short, we want to get all categories related to proper product, and in opposite – all products in category. To make this plan done we have to:
- Define relation between entities using
Relationclass, - extend already defined
Fetcherto find the entities based on that relation, - add proper fields in exposed schema,
- finally we need to implement function which will fetch proper records from database.
Let’s make it happen.
Defining a relation between Product and Category will be the first thing to do, so let’s look how it works in Sangria
Basic Relation costructor’s signature looks like that:
https://gist.github.com/anonymous/942993ba61789d06ddf8a276cb2cb857#file-post-scala
T in this case, is the type of model for which we’re defining relation, RelId is type of Id of related model.
In example where we have categories stored in database as list of ids like:
https://gist.github.com/anonymous/cbe0a89c5f5e64acc19b6f1838211112#file-post-scala
We are able to define relation in this way:
https://gist.github.com/anonymous/e26e8c85208fd7f405fc95b4d645008c#file-post-scala
Probably it’d fit big part of your needs, but not ours… We’ve added few extra miles and used model with many-to-many relation, so it isn’t impossible to do as in the example above. Of course we could define our schema definition and fetch all Category’s ids by Slick, while records are loaded from database. Yes, we could. But it produces additional database operation even if we don’t need such data. But there’s another way.
There is another Relation constructor we can use:
https://gist.github.com/anonymous/1697519c084b4b9fee5960f4d784f819#file-post-scala
This constructor needs additional object (Tmp) and uses this to retrieve a model and its relations.
In our example, we want to find all categories for product, so T will be Category(type of related model) and RelId will be ProductId(Id of model we’re looking relation for), so we can define our relation like this:
https://gist.github.com/anonymous/1fd177a4d580df6840f6e2d986a20cc4#file-post-scala
Note: Sangria uses Seq[IdType] in every function related to ID’s, even if function logically should work for single ID only. In some cases it could be misleading.
We used tuple (Seq[ProductId], Category) as temporary object, so it’s easy to retrieve proper data. Relation is defined, but where we’ll get such temporary object from? The most logical answer is: from data source. Yes, in our case database. We have to provide function, that gets product id as argument and return sequence of such tuples. Remember that even for single id, we use Seq[IdType].
https://gist.github.com/anonymous/d427a50ecd76d463b0b33633a5feef76#file-post-scala
So far, so good. We are in the middle of our list now. The next step is Fetcher. As I mentioned previously, one of the features of this type class is support for model ID along with relation ids. Now we have to tell fetcher, there is relation defined and it can be used when needed. We have to refactor our categoriesFetcher which now looks like this:
https://gist.github.com/anonymous/c52b3b9298cc12ea0842976ad6bf9752#file-post-scala
This basic constructor uses apply function, but to add support for relation we have to use rel or relCaching. The difference is that the second uses caching mechanisms for fetched models. Of course you can define your own mechanism but how to do this is not covered in this article.
https://gist.github.com/anonymous/9aea45ed67b10762b18f49a229ba6bc1#file-post-scala
relCaching needs two functions, the first is like in previous example: responsible for getting categories by its ID, and the second is responsible to get the categories by their relations. When we want to find categories for product, Product’s ID is extracted by RelationIds and result is passed to repo.categoriesByProducts where data is read from the database. At the end Relation maps and returns result.
We’re almost done, all we need to do is to expose categories function for product field. To define how the Product is exposed we’ve used ProductType class. All the fields are extracted by macro, but also have possibility to add more if we need. For such case is AddFields type class.
https://gist.github.com/anonymous/183fa1c6f8f80ca375208c7ce38a1c92#file-post-scala
What to explain… We just added field with name categories that expects a list of categories in the response. Resolver uses fetcher, explicitly sets a relation and passes product ID as a parameter for that relation.
That’s it. We did all to set up many-to-many relation. When you’ll do the same work for Category and Products relation, your code should be similar to ‘stage3’ branch code
If you run code from the branch you should be able to make queries like that:
https://gist.github.com/anonymous/44f74347fee51f88c3db0732a421a2fd#file-post-text
And get the response:
https://gist.github.com/anonymous/7eba2a3342f3191d698e802366839f0c#file-post-json
But what if we will execute following query?
https://gist.github.com/anonymous/92eba34ed289530dd2cd4b8cbf70c337#file-post-text
Implementing Complexity
We can analyze complexity of our query and react somehow when it reaches the limit. To give you an example: Add fixed complexity value for every field and when complexity crosses some threshold, it will respond with an error. I chose to make fixed values, but if you want, you can compute the value somehow, for example based on amount of returned records, etc.
Firstly we’ll define helper function and use it in fields
complexity field needs parameter of type Option[(Ctx, Args, Double) => Double] where Ctx in our example is ShopRepository but if you want, you can keep it generic. Because query is tree-like, we compute complexity down the tree recurrently. Now populate some values along defined fields like:
Now our exposed model looks like:
https://gist.github.com/anonymous/129474ea7f4f150dd08e8d0e27265146#file-post-scala
We also set complexity of value 30 to ProductType and CategoryType. Ok, but server has to react somehow when complexity reaches value of 300, for example. Such operation could be managed by query reducers. We can create our own QueryReducer, that checks value of complexity of query, and in case it’s greater than 300 it will throw an exception. Then we will catch the exception and respond with proper status and message.
Let’s begin from implementing Exception then:
https://gist.github.com/anonymous/3a02732fb2dbeee45f5121ca88e12b7f#file-post-scala
Now query reducer responsible for checking the complexity’s value:
https://gist.github.com/anonymous/3eb0dbe24979b3a47784bfc18b2e0a1a#file-post-scala
At the and we have to tell the Executor about our handler and reducer. Note that you can define as many reducers as you want. Add to our Executor:
https://gist.github.com/anonymous/7c4363071a56c4f8192e82ef4ebad6f3#file-post-scala
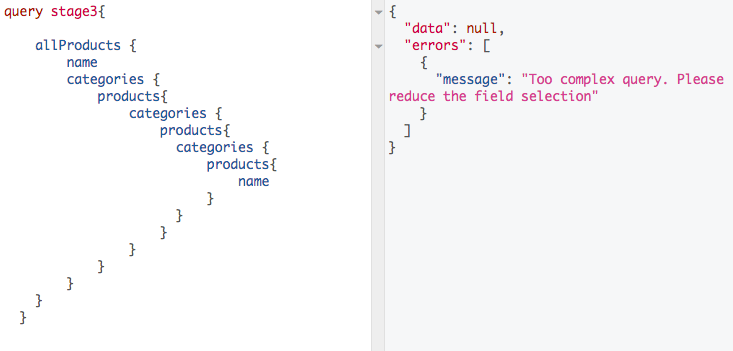
This is what we wanted to achieve. Entire article was about implementing read operations, now I want to show you how to implement really simple write operation.
Simple mutation
So far we’ve used query for getting data. If we want to add or update data we have to use mutation instead.
Assume you want to add Category with name “Foo”, you have to execute such query:
https://gist.github.com/anonymous/008e97a17e7bdb89466abaddf93f2c33#file-post-text
Note: my slick setup doesn’t support autoincrementing of ID, so you have to provide it while adding a record. Of course, this wouldn’t be necessary for a production ready system.
Let’s implement this, starting from database operation. The query above shows, that we have to add a Category, providing id and name. It also expects Category in return. Following function will manage this:
https://gist.github.com/anonymous/2ef82c27f8e425e7e4d5ef359f74b62d#file-post-scala
Time to update the schema. Instead adding another field to QueryType we have to implement a new ObjectType responsible for all mutations.
https://gist.github.com/anonymous/86767f43a02a1fe15fbf75979fa974a5#file-post-scala
We’re reading arguments id and name and then we pass these to the proper repository function. Easy like this. The last thing is to tell exposed Schemaobject that we also support mutations.
https://gist.github.com/anonymous/e8215cec4a000638d2537d13a7054a74#file-post-scala
That’s all. Now, such prepared server should supports queries like this:
https://gist.github.com/anonymous/b48ea58c99db923095331db0dd3fbaa5#file-post-text
After that we should see “FOO” in the categories listing.
Recap
In this article I wanted to show how to implement basic GraphQL server in Scala. I deliberately added some extra effort to show a little more complicated model than you can find in official examples. But it’s still only tip of the iceberg what Sangria provides.
Websocket based subscriptions, Middleware, authorization, caching to name but a few. Read the official guide to find out all the things this library offers. I know I didn’t cover all the possibilities and responded for all beginner’s question, but I hope I encouraged you to go deeper in this topic. Leave a comment for all the questions feedback :D
Links
- GraphQL
- Sangria
- Learn Sangria
- Akka HTTP
- GraphQL vs REST
- Repository with code used in this article
- Sangria examples with Akka HTTP
More on Akka
- Akka Serverless: Analysis & Comparisons
- Scala/Akka Actors, CQRS/ES, and IoT
- Monitoring Akka applications with Mesmer and OpenTelemetry
- There is More To Akka-typed Than Meets the Eye
- Making ZIO, Akka and Slick play together nicely
Read more

Authors

I’m an experienced developer who has acquired a broad knowledge. I’m always ready for new challenges and learning new skills.
Popular Posts in category

Looking into Scala.js

Your first microservices using Scala and Lagom
Handling Split Brain scenarios with Akka