Scala/Akka Actors, CQRS/ES, and IoT
TL;DR
In this article, I will summarize my experiences while working on an Internet of Things project for the first time. I’ll also be explaining how adopting the Actor model (Akka), Command Query Responsibility Segregation and Event Sourcing patterns brought a lot of benefits, such as:
- Providing consistent microservices scalability
- Obtaining a minimum viable product (MVP) in a short time-frame by using microservices archetypes that provided validated templates with CQRS, Event Sourcing and Actor models in mind
- Having technological flexibility, such as, for example, on the storage side, not needing to early optimize on DB selection/commitment.
- Generating independent deployment-ready artifacts for continuous integration and delivery.
Introduction
Scala Akka Actors, CQRS/ES, and IoT
One of the main challenges for Internet of Things newcomers and startups is achieving scalability, and, to be more specific, the elasticity to adapt to customer and environmental demands. I realized this four years ago when I was working for a startup that had great hardware knowledge and a talented team of electronic engineers. A little more than a year before I was hired, they had been in a hurry to quickly implement a solution for industrial, security and educational use cases. And to achieve that, they had had to quickly hire a team of software engineers. A year later, they had created a Python monolith that behind the scenes also used some Java backend services to handle all the work related to asset management services, a rules engine, asset location services, and dashboards (which needed to be built for each industry use case). At that time, they were actually very happy with themselves because their first solution had passed some potential customers’ evaluations/proof of concepts, so they had continued to add more features and to evolve the solution. However, as always happens with software, what works in the lab doesn’t mean it will work in production, particularly with higher real-world demands.
The First Attempt
The main goal was to create a platform that would be able to manage and track different types of entities (people, products) moving between different locations. In order for these movements to happen, these entities needed to be first authenticated and authorized. The company customized some RFID tags and RFID reader cards that were designed to adapt to different use cases. In addition, the idea was to have a central place where managers would be able to define these movement rules in a more flexible way. A lot of effort was invested in defining a rules engine that would be able to handle all kinds of possibilities and dependencies to make these decisions.
The initial solution approach was to allow for a mixed cloud/local(edge) solution deployment. They visualized having some core services (developed using Java/Spring) to handle the most critical concerns. Things such as asset management services and a rules engine (to approve or deny “entity” movements) were created at this level. Each RFID reader, used to connect each RFID tag with the services, locally ran some libraries to emit JSON events that were transmitted to the Java/Spring API. In the following graphic we can see a high level diagram of this scenario;
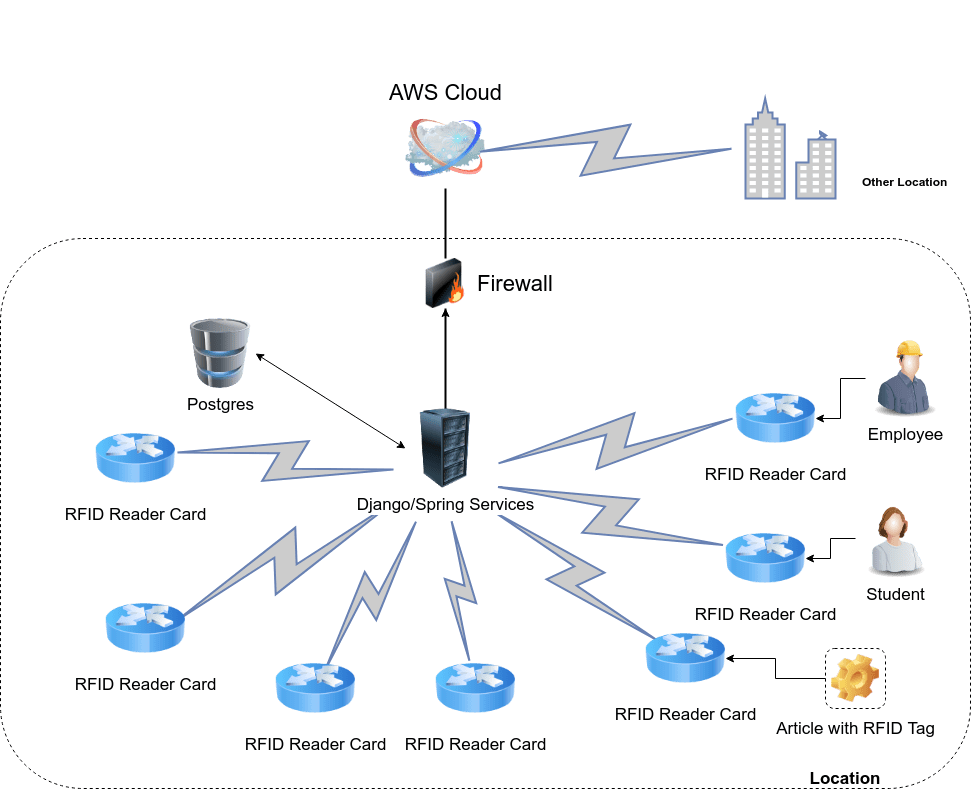
An important aspect to consider was the dependency between the Authorizer Service and the Rules Engine Service. The Authorizer service made some basic metadata and security checks before passing the business request to the Rules Engine service. In the end, after evaluating all the associated rules for the related entity, the request was approved or not.
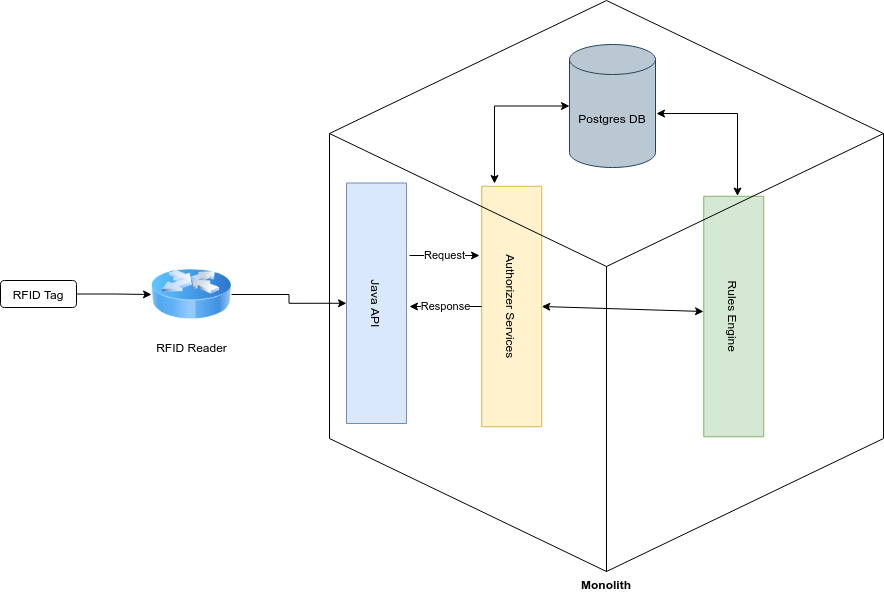
When the number of sync requests per second increased beyond 150, both the Authorizer and the Rules Engine started to have issues and delays with the shared DB, which became more evident when different reports and dashboard queries were run at the same time. It finally got to the point where the services froze and Spring needed a complete manual restart to recover.
A new perspective with Actors and Microservices
At that moment, I already had some exposure to some articles and case studies about how the Actor model, particularly with Scala Akka, could help in making some solutions with better scalability. I also had some background knowledge from Udi Dahan’s work on CQRS from the .NET world, and I decided to give it a go with this combination: Scala Akka and CQRS/ES. At that time I was just a Scala beginner, but one other person in the team had some experience with it, and together we first worked on creating a plan to re-implement the Authorizer and Rules Engine with Scala Akka. The idea was to represent all of the different Entities as Akka Actors, with even the RFID readers being represented as actors. However, the priority was to work on making these entities ( represented as products, workers, students, etc) respond to commands from the Authorizer service and to let the Rules engine become a kind of an FAAS to make decisions, based on each request parameter. So to do this, we decided to separate the concerns and we took the following approach:
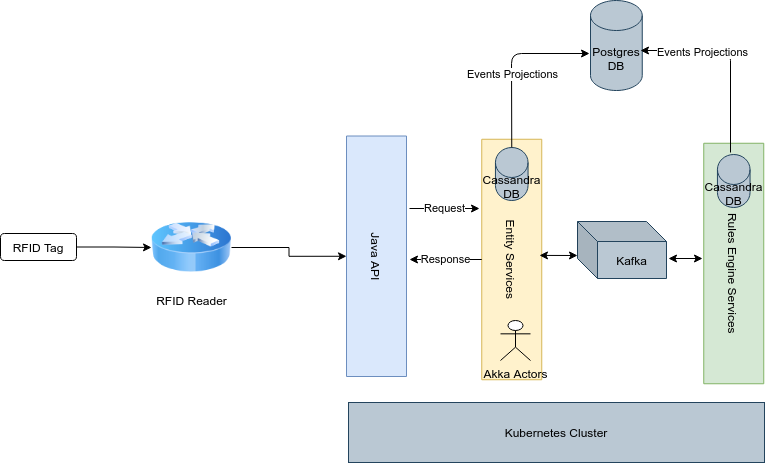
This time, both the Entity and the Rules Engine services were implemented using CQRS and in the case of the Entity Service, Akka was used to model/hold each entity state (especially the entity location). Lightbend (now Akka) released Lagom (https://github.com/lagom/lagom) as a new framework for developing microservices in Scala and it helped to make our journey a lot easier. Some of the features we used were:
- Akka Persistence: this helped a lot with our actors’ state recovery.
- CQRS and Event Sourcing out of the box
- Events Projections
- Message Broker support (Apache Kafka in our case)
However, I have to admit that not everything was a bed of roses. Although Lagom made our life easier from the perspective of development, the first Lagom versions we worked with were not very “Kubernetes friendly” and we were using local Kubernetes clusters for deployment. So we had to deal with some manual work at that time to make it work in a more CI/CD-like environment with Jenkins. For the same reason, Lagom’s service locator also required some manual work to generate our own service locator.
Lessons and Conclusions
Some key findings:
- There was an increase in Requests per Second with the same hardware: with Akka, CQRS and Event Sourcing, it was possible to obtain improvements from between 10x and 50x in requests per second during performance tests using the same hardware as the original architecture. This showed that a separation of concerns (write models & read models) and lightweight actors are crucial tools to achieve these kinds of scalability levels with concurrency.
- Another important aspect that is usually overlooked in these refactorings is related to DevOps and infrastructure knowledge. We found a lot of problems during development, not with the development frameworks but with some manual work that we had to do in order to make our CI/CD process work in a more friction-less way. So getting your Kubernetes experts involved in the team from the start is a must! Because the most important challenge we had when walking this project was to deal with the deployment complexities that microservices bring to the table. However, recently new tools have arrived that can make our lives easier in the Kubernetes world for microservices deployment (GitOps, Helm, Service Meshes)
- A microservice framework was essential for getting development results with less boilerplate code. By this, I mean it was crucial to start with a standard project archetype, with clear boundaries between different layers and allowing for the service core to be clearly separated from the rest. We used Lagom because we found it the most useful in our particular case, but it could be another CQRS/ES framework. You have to be clear with your key goals before making any decision.
- Akka is a solid actor model implementation with a lot of tools that can help you produce results and focus on your core business problems. When we were working on this project,Scala Akka Streams, Akka Typed (we used Akka “Classic”) were not available (they were not completely ready at that moment); features that could have been a huge benefit to us. However, I can confirm the following properties that we leveraged:
- Each actor uses asynchronous message handling and “single message at a time” processing. This means basically that we didn’t need to worry about handling state contention in a concurrent world. Each actor is a guard of its own state, so the contention, in this case, is granular at the entity/aggregate level.
- I didn’t realize this at the beginning, but using actors, in this case, made our DB selection process less stressful. Our actors receive commands and produce one or more events that can be persisted/written in any storage we prefer. We selected Cassandra in our case because it was integrated out-of-the-box with Lagom, but it could be any other. Actually, most DB writes become append-only events so our database would be less heavily used. Surprisingly, this seems to be aligned with Akka Serverless vision, by making the DB selection, something that is no longer crucial.
- Actors keep an in-memory latest state representation, so from an event-sourcing point of view, this means fewer events replaying, even when using snapshots.
In conclusion, I encourage you to give actors and CQRS/ES a go when implementing your IoT solutions. It is a solid and proven pattern, with enough documentation to make your solution not just more resilient but also responsive. And for developers, there are frameworks and libraries all of which will make you productive in just a few days. Due to time constraints, we used REST/Json APIs for all communication, but an MQTT and gRPC implementation could also be leveraged to make it even faster with less processing consumption.
Read more on Akka:
- Akka Serverless: Analysis & Comparisons
- Monitoring Akka applications with Mesmer and OpenTelemetry
- There is More To Akka-typed Than Meets the Eye
- Making ZIO, Akka and Slick play together nicely
- Using Akka HTTP with Sangria as GraphQL backend
Read more:

Authors

I'm a software engineer with more than 20 years of experience in software development, infrastructure and business intelligence projects, in various industries (banking, telecommunications, retail, oil & gas).As a Services Practice Lead, I have experience in building and developing high impact teams, that have delivered quantifiable business value to involved customers, making these teams a key business capability for an organization. I'm also an enthusiast about leveraging functional programming with Scala and reactive technologies, learning and practicing a lot about the following technologies and patterns: ZIO, Akka, serverless, event sourcing and CQRS.