Akka Serverless: Analysis & Comparisons
TLDR: Frequently Asked Questions [FAQ]
Q: What is the Actor Model
A: Imagine Object-Oriented Paradigm. Now make it distributed.
Q: Scaling? I already have that with Serverless
A: With the Actor Model you can remove latency. No need for database queries, the data is at your disposal on your server.
Q: Low Latency? Didn’t Akka already provide this?
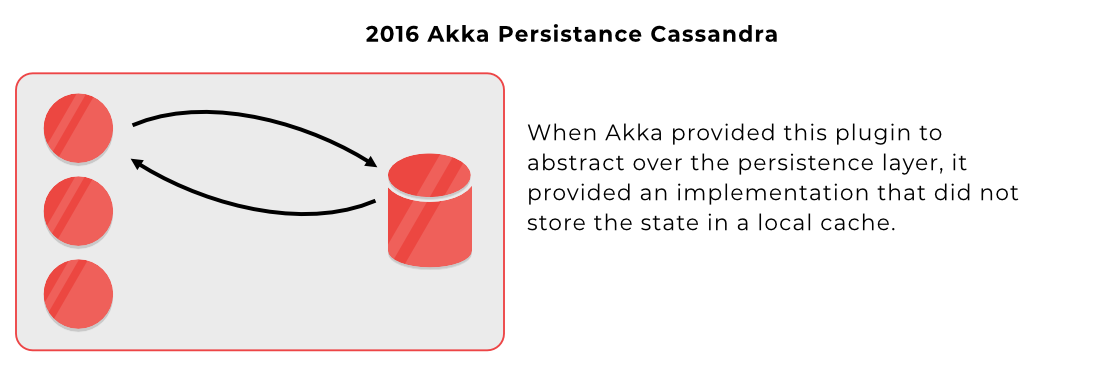
A: Akka was a no-frills product regarding the persistence layer. And commonly used plugins for managing of the persistence layer did incur in penalties regarding lack of local caching i.e.: Cassandra Persistence Plugin
Q: Can you pinpoint the key differences between Akka Serverless and Akka?
A: Automation of best practices and support for multiple languages i.e.: Javascript
Q: So Akka Serverless provides abstractions. Didn’t Flink already do this?
A: Flink did already abstract over the persistence layer. This is true. But now we not only have abstraction of the persistence layer as before. Both Flink and Akka are releasing tools that do this but also allow for multiple language support.
Q: Akka vs Flink. Who wins?
A: For a more guided experience go for Flink. It supports the Actor Model but automates best practices related to batching and caching. Persistence, it is done for you.
Q: Akka Serverless vs Flink Stateful Functions. Who wins?
A: A fair comparison between the two can be provided. However, a clear definition of competition outcome cannot be provided.
As of now, they are being released and we will need to wait for the industry feedback to achieve a clear, distinct, popular assessment. Later in this article, a conversation between the two CTOs is shown, in which they discuss each tool in detail and share, in good spirit, a conversation of hope for what the future holds.
Q: Abstraction of the persistence layer. Got it. What about Javascript?
A: With the advent of OpenAI.Codex we may be seeing a pivot in the industry towards providing API for languages which, jokingly could be described as being made for scripting only. Will we be seeing them pop up in serious data transformation projects now?
Maybe the generation of code, that currently favors popular languages like Javascript, will be the catalyst for this API creation. They are going to be used in combination with AI.
I am a Senior Developer. What’s Akka Serverless?
Then this article is for you. In this entry, we will explain who this technology is targeted at, and how to get value from it. Let’s take a few key pieces of data and iterate over them.
[
“support for Javascript”,
“mentions about Serverless 2.0”,
“all examples are focused on direct interaction with an HTTP client”
].map(`is it for me?`)We know that until this year, the Scala language had two big, clearly defined, communities.
- A community that was going to transform massive data in batches using Spark.
- A community that was going to summarize complex data in real-time using Akka.
This is like Spark adding an SDK for Javascript. Except it is for Akka.
It is meant to trigger a revolution in the industry, on the scale that we saw in 2016 with the advent of serverless in the cloud providers.
It is mainly focused on direct interaction with the end-user.
So, the following rules of thumb can be provided:
Are you planning on starting a project using Serverless technology?
Then you probably are looking for Javascript/Python/Golang developers to do the job. You can continue on this path but provide a faster response to your end-user thanks to Akka Serverless.
Do you already have a project that is using Akka but is not using Kafka?
Then the migration to this new technology may prove useful given that the automation of infrastructure will definitely impact your speed to make releases.
Are you using Akka in combination with Kafka?
This is where we draw the line in the sand.
Because it means that you are probably using Kafka to communicate with delivery guarantees via events across multiple Akka microservices. This, as of now, is not the main objective or purpose of this technology.
Akka Cloud State. Serverless 2.0
The main objective of Lightbend Akka Serverless is to start a new community that – just like in 2016 when they abstracted over the details of NodeJS servers – abstracts now over the details of an Akka HTTP server that coordinates a cluster of actors.
Akka Cloud State, not Lagom 2.0
The main objective of Lightbend Akka Serverless is not to replace Lightbend Lagom.
Lagom was created to provide automation on infrastructure in the third case we mentioned. The one where you are developing microservices using Kafka for communication.
I am a CTO. What’s Akka Serverless?
Then this article is for you. In this entry, we will explain who this technology is targeted at, and how to get value from it. Let’s take a few key pieces of data and iterate over them.
[
“support for Javascript”,
“mentions about Serverless 2.0”,
“all examples are focused on direct interaction with an HTTP client”
].map(`is it for me?`)When deciding if a technology should be incorporated into the company stack, we will need to take binoculars and look far into the future.
See this video, see the future.
OpenAI Codex needs a JS API to start working.
With this in mind, we need to ask the following questions:
- Why did Microsoft Word, as seen in the video, offer a JS API?
- Why did Lightbend(Akka) and Ververica(Flink) develop JS APIs in 2021?
The end-user of these Javascript APIs may very well be humans.
But at the same time, if we were to visit the R&D offices of the two biggest ETL platform providers, would we expect to see a team dedicated to collaborating with what OpenAI has to offer?
The end-user of these Javascript APIs may very well be OpenAI Codex.
2021 is the year of AI.
- Github is starting to offer Copilot. Powered by OpenAI.
- Flink releases JS API.
- Akka releases JS API.
I think we are not far away from typing the case of use and seeing the actor model being brought to us in front of our very eyes.
The design of an ETL used to need strict types because the codebase was growing fast. So many lines of code, they definitely needed some supervision. The computer was the supervisor. We gave the computer types, and the computer was able to dictate that everything would be alright.
The design of an ETL will need human-readable use cases. With the advent of AI, instead of adding language syntax to achieve this supervision from the computer, it is the computer that demands simplicity from us and clarity. It demands a language API that is easy to learn. Like a Javascript API. Instead of giving strict types for the computer, we give clearly defined use cases that if it manages to comply, it counts as an End to End test on its own.
FAQ
#1 What is the actor model?
Imagine object-oriented programming, and now take every instance of a class and distribute that instance across a cluster of computers.
The actor model is defined by some as the main branch from which the industry forked the concept of Object-Oriented Programming, and implemented it according to the hardware of the time. In the old days, we made programs for a single machine.
In today’s world, scaling from 3 computers to 30 in a matter of seconds can prove necessary during spikes in traffic. And the alternative the old days gave, to have one big computer that could sustain traffic at all times, can now be seen as a viable but less efficient solution when we can rent the hardware according to our needs, dynamically.
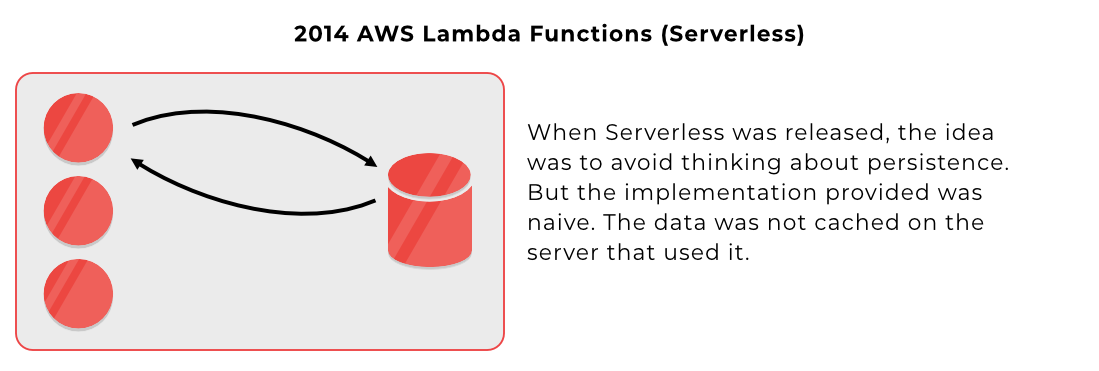
1A | I can scale already, using Serverless architecture.
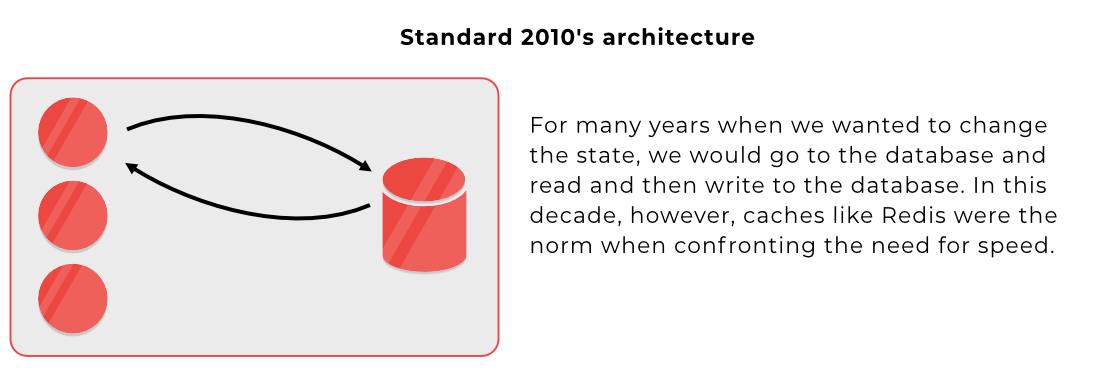
This is true. The main difference between Serverless architecture and the Actor Model is on where to put the state. In Serverless, you have your database separated from your server, and in some cases, you will make multiple queries to fulfill one request.
In the Actor Model, the data is stored where you use it, in the server. Which means fewer queries you need to perform against your database.
1B | In the Actor Model, is my state stored in my server?
In the best possible implementation of the Actor Model this is true, and yes you are going to be keeping a database consistent with each of your servers, asynchronously.
The act of keeping data ready for consumption, to not have to query a database, is defined by many as following the Reactive Manifesto.
Akka is an implementation of the Reactive Manifesto.
1C | Does Akka Serverless provide this mechanism?
Yes.
Akka did not. Akka Serverless is the automation of good practices.
#2 What is the difference between Akka and Akka Serverless?
Akka did not offer a true abstraction over the implementation of persistence. It offered plugins instead and allowed you to create your own.
In the old days, if you wanted a more guided experience you would use Flink.
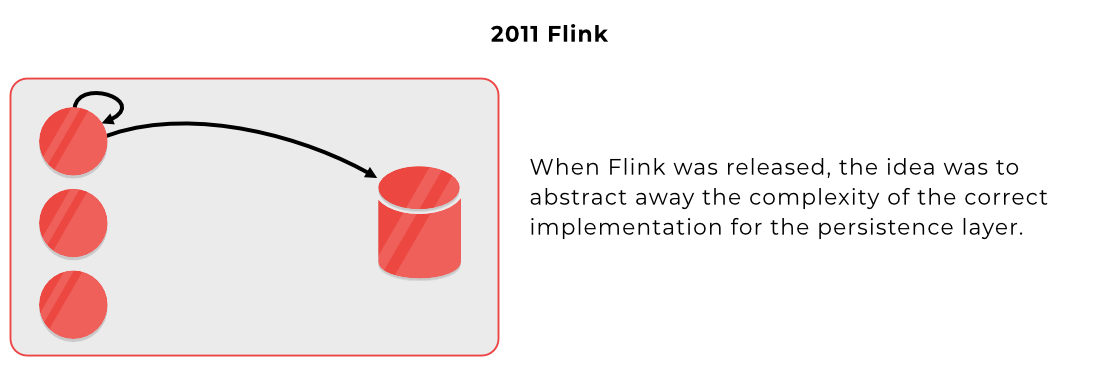
2A | Explain Flink
Flink offers an implementation of the Actor Model that fully abstracts over the implementation of persistence. In Flink the actors persist to local disk usage, like Kafka does, using RocksDB. A Key Value database to persist on your local disk. And there is a background task that takes the new changes in batches and updates a database. In this manner, when you add new nodes, the new nodes will read from this database instead of reading from disk during setup, and once they are synchronized, they start working as usual. Persisting to disk, updating the database in batches in the background.
#3 If we were to compare Akka against Flink. Who wins?
Before Akka Serverless the experience with Flink used to be more guided.
A common source of trouble in the Akka community was the Akka Persistence Plugin for Cassandra, for example, where your actors would query the database every time you create them, or after you call them a few minutes later. This did not follow the Reactive Manifesto and caused the usual issues the industry had experienced over years before the manifesto was written. The database would become a bottleneck during intensive writes. Flink avoided this by updating the database in the background.
With Akka Serverless, the experience with Flink or Akka becomes deprecated.
Akka Serverless is the clear winner against Akka or Flink because it really abstracts in the best way possible over any difficult decision you need to make.
3A | With Akka Serverless I don’t have to worry then about the database?
The database and the caches are all implemented for you.
In detail, a server is launched alongside your own, which automates the best practices for you.
3B | What is the answer from Flink to Akka Serverless?
It is actually Akka Serverless which was released after Flink Stateful Functions.
See here:
Flink Stateful Functions release — May 07, 2020
Akka Serverless Open Beta release — June 16, 2021
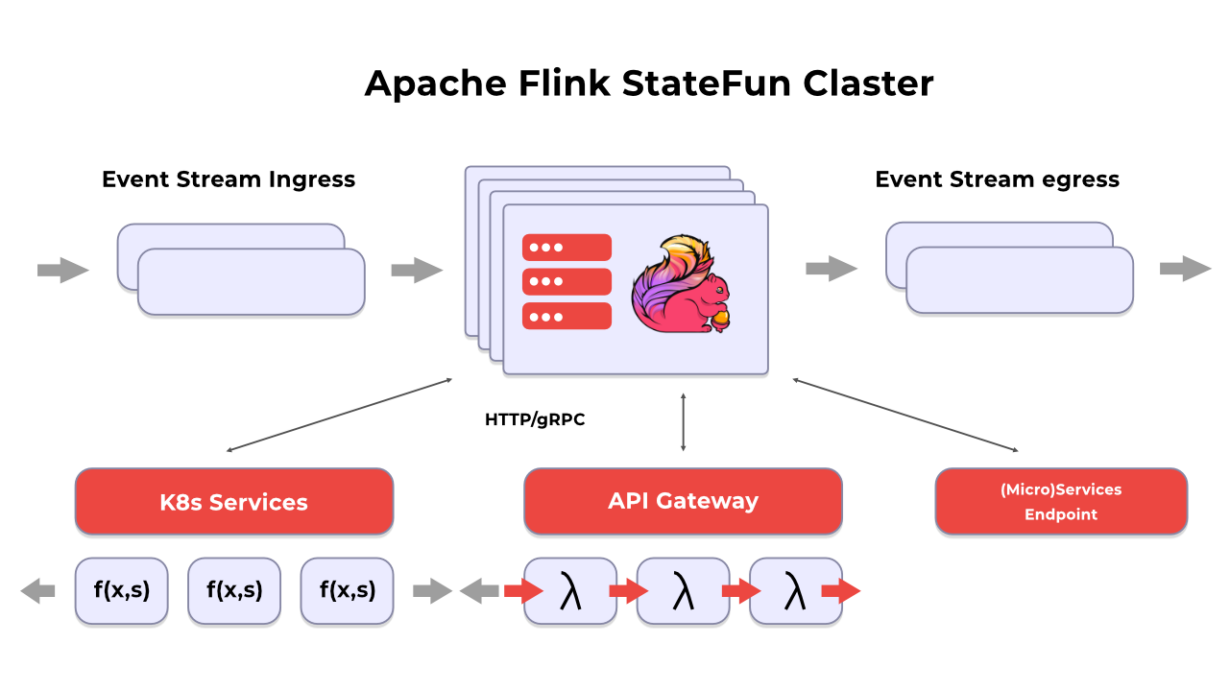
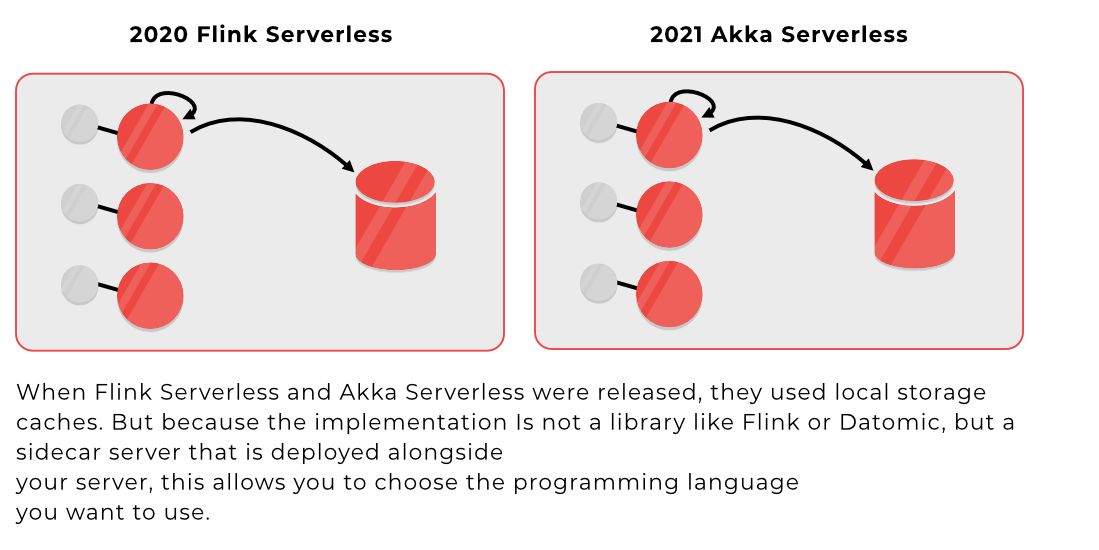
3C | What are the differences between the two on the inside?
This is the architecture provided by Flink Stateful Functions:
This is the architecture provided by Akka Serverless:
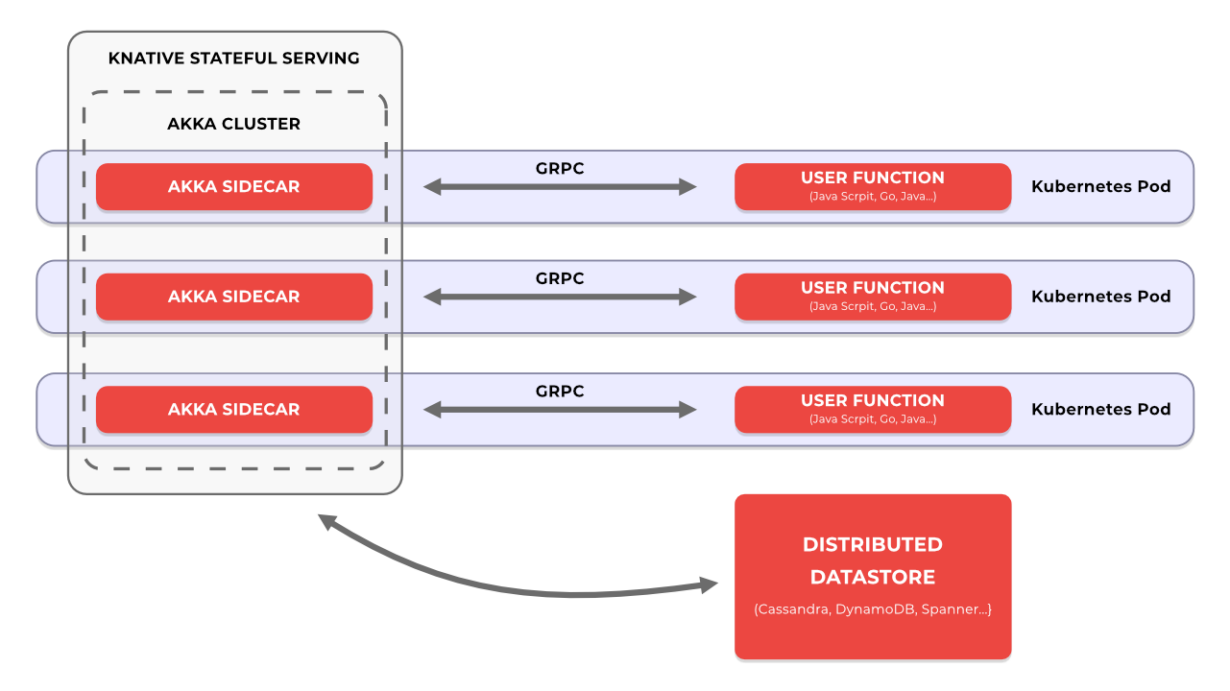
While the colors and diagrams seem to be different, in fact, both share the same main idea:
To have an SDK for Javascript, Python, and many other languages that when deployed, the platform at the same time is in charge of deploying what is called a sidecar. This is another server made to interact with your server, that will abstract with you over the difficult, but perfect, implementations of the Reactive Manifesto.
This is, in a few words, the architecture of the new wave of platforms of which Akka Serverless is part of.
3D | Where can I find more information about the comparisons between the two?
Here you have the CTO of Lightbend (responsible for Akka) and the CTO of Ververica (responsible for Apache Flink), together in a call. This will enlighten you on the similarities between the two.
We live in the Stone Age. Building Cloud applications is like programming assembly before compilers were around.
Asterios Katsifodimos
There is also a fantastic back and forth that I recommend reading, that will also enlighten you on the small differences between the two:
In my mind, actor systems are the toolkit with which distributed systems like StateFun can be implemented.
Aris Kolipoulos
#4 Why Javascript? Why Python? Why not Scala?
We are seeing Microsoft, Verberica, Lightbend, all rushing this year to support common parlance languages. Dialects that were made to be comfortable to write and read. That was their main objective at the time. With Python especially, there was nothing more important at the time for its author, Guido Van Rossum.
So it’s no surprise that AI tends to understand these small syntaxes, no types, languages, better than more complex ones.
Rule of thumb:
For as long as AI favors these languages, expect to see more integrations which were once unheard of, between incredibly critical systems that once demanded strict guarantees, and now for an unbeknownst reason they throw away all guarantees and suddenly work without compilation compromises. Once AI learns to write strongly typed languages, expect yet another pivot. 2021. The year when AI took control and became the driver of the industry.
4A | If this is true, what signs should we expect to see in the industry to prove it?
Microsoft has released a plugin that connects the Javascript API for Office to OpenAI.Codex.
If in the upcoming months we see new products from companies that have offered new Javascript APIs this year targeted at interoperations with AI, then that’s it.
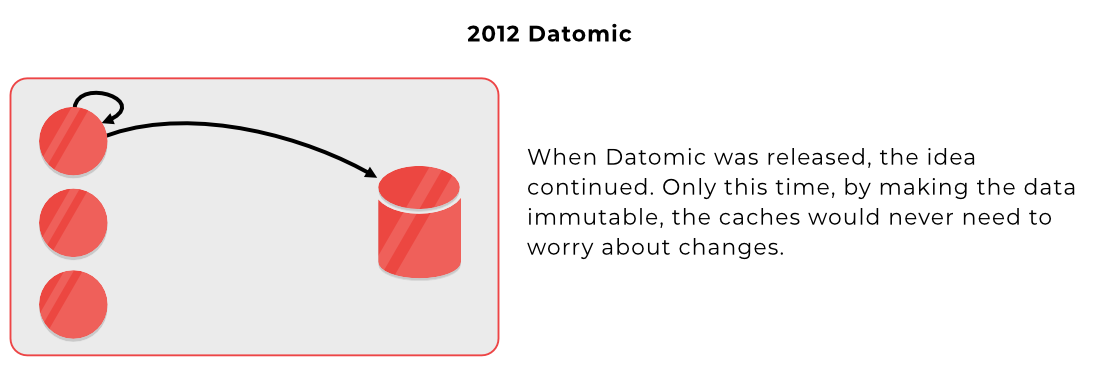
Automation of best practices throughout the years

Read more on Akka
- Scala/Akka Actors, CQRS/ES, and IoT
- There is More To Akka-typed Than Meets the Eye
- Making ZIO, Akka and Slick play together nicely
- Using Akka HTTP with Sangria as GraphQL backend
- User Authentication with Keycloak – Part 2: Akka HTTP backend
See also

Authors

Akka developer that reached 170K writes per second on each of three t2.xlarge AWS instances on production in the domain of government taxes. I specialize in data pipelines.
Popular Posts in category

Looking into Scala.js

Your first microservices using Scala and Lagom
Handling Split Brain scenarios with Akka